背景
在网络安全领域,渗透测试被视为评估系统防御能力、发现潜在漏洞并验证修复策略的核心手段之一。其中,黑盒渗透测试代表了一种高度贴近真实攻击者视角的极端场景:测试人员在对目标系统内部架构、源代码及网络拓扑结构一无所知的情况下,仅依赖外部接口探测、攻击面映射以及业务逻辑推演,合规地识别并利用安全漏洞。长期以来,这一过程高度依赖人类专家的经验、直觉与复杂系统认知能力。
尽管自动化漏洞扫描工具(例如 Nmap 等网络扫描器及各类商业化 Web 扫描平台)已在工业界得到广泛应用,但其主要基于预设规则、指纹匹配与已知漏洞特征库运行,侧重识别显性配置缺陷与常见漏洞模式。这类工具普遍缺乏对业务语义与上下文约束的理解能力,也难以像人类攻击者那样,将多个低风险缺陷在时序与依赖关系上进行组合,构建具有真实破坏性的多阶段攻击链。因此,在现代分布式系统与复杂业务流程下,传统自动化方法在攻击链规划、跨组件关联与多步骤利用方面仍表现出明显局限。
为突破人工驱动渗透测试的规模瓶颈,学术界与工业界曾引入机器学习(ML)、深度学习(DL)与强化学习(RL)等方法构建自动化攻击代理。然而,这类方法往往依赖离散且人工设计的动作空间:在强化学习框架中,攻击行为通常被抽象为有限集合的扫描、利用或横向移动操作,进而限制了复杂利用原语的灵活组合与策略生成能力。同时,相关方法普遍存在样本效率低、对特定环境依赖强、跨场景泛化能力不足等问题;在缺乏现实世界建模与符号推理机制的情况下,其在长时序、多阶段攻防流程中的规划与推理能力受到显著约束,难以有效协调侦察、漏洞分析与利用验证等环节。
近年来,大语言模型(Large Language Models, LLMs)的快速发展推动网络安全自动化发生范式转移:安全能力的核心从“基于规则与特征匹配的确定性扫描”逐步演进为“以生成式模型为中心的概率性推理”。自 Transformer 架构确立大规模序列建模的技术基础以来,围绕计算最优训练、对齐优化与多模态能力融合的持续进展,使得以 GPT-4o 等为代表的模型在自然语言理解、模式归纳、代码生成与长上下文推理等方面表现出更强的通用能力。通过构建“执行-决策循环”(Perception-Action Loop),LLM 在信息收集、漏洞分析和漏洞利用的各个阶段展现出了前所未有的自主性 。
然而,将 LLM 直接应用于真实攻击场景仍面临系统性挑战:模型幻觉可能导致错误判断与无效操作;长上下文记忆衰减会削弱持续任务执行与状态保持能力;复杂任务分解与长程规划不足限制了对多阶段攻击流程的统一编排;同时,商业模型在安全对齐策略下可能拒绝执行与攻击相关的关键指令,影响端到端自动化的可用性。因此,如何在安全可控与合规约束下,将 LLM 的推理与生成能力稳定迁移到黑盒渗透测试,并实现可复现、可审计、可泛化的自动化流程,仍是当前研究亟需解决的关键问题。
本文旨在对 LLM 自动化渗透测试的发展历程、核心架构演进、实证实战效能、内生性技术缺陷以及未来的发展边界进行简单的分析。
核心架构演进:从状态外置到多智能体编排
在 LLM 出现之前,研究与工业界对渗透自动化主要依赖两类路线:
- 一类是“规则/建模驱动”:通过攻击图、状态机或显式规则,把渗透过程形式化为可搜索路径;在此基础上再用规划或强化学习寻找最优/近似最优攻击序列。这类方法在结构化环境中可行,但普遍依赖先验环境、相对固定的动作策略,并且很难在真实网络的噪声与多服务组合中泛化。
- 另一类是“工具链自动化”:用脚本与扫描器批量收集信息、生成报告,但在“从发现到可验证利用”的关键跨越处仍高度依赖专家判断。换句话说,工具可以自动化“收集”,却很难自动化“推理”和“取舍”。
早期将 LLM 应用于网络安全的尝试,主要局限于“提示词工程”(Prompt Engineering),即将通用的大型语言模型作为一个静态的安全知识问答助手。然而,在真实的渗透测试场景中,这种单体模型架构迅速暴露出了致命的缺陷。渗透测试是一个涉及长周期、多阶段、高噪声数据处理的复杂任务。当面对动辄数千行的扫描结果或长序列的Shell交互输出时,单体LLM极易触发“上下文衰减”(Context Decay)现象,导致模型“遗忘”早期的侦察信息,或者在海量的无关数据中迷失方向,进而产生错误的判断或提出无效的指令 。为了克服这些结构性瓶颈,自动化框架经历了几次关键的架构跃迁。
围绕这一瓶颈,学术界与工业界提出了多种系统性改进方案,包括基于树状结构的任务分解、多智能体协同推理,以及引入确定性验证机制的闭环执行框架等。现今研究与工业界聚焦的点在于能否把渗透测试做成端到端的、状态驱动的、可执行的决策循环(perception–action loop)
PentestGPT: State Externalizatio, 把“长链条渗透”拆成可维护的状态机式结构
PentestGPT 是较早尝试将大语言模型系统性引入渗透测试流程的代表性框架之一。该方法最初于 2023 年以预印本形式提出,并于 2024 年发表于 USENIX Security 2024。其核心洞察在于:尽管 LLM 在单个子任务层面(如生成攻击命令、解析工具输出或提出下一步建议)表现出较强能力,但在端到端、长周期的渗透测试过程中,模型往往难以持续保留和有效利用既有信息,导致对整体攻击场景的理解出现碎片化甚至遗忘。
PentestGPT 并未试图单纯依赖更长的上下文窗口,而是将状态外置(State Externalization),即将渗透测试的“进度与状态”显式表示为一个外部结构,并围绕该结构构建了三层模块化架构,包括推理模块(Reasoning Module)、生成模块(Generation Module)以及解析模块(Parsing Module)。
- 推理模块负责维护一个以自然语言表示的渗透测试任务树(Pentesting Task Tree, PTT),用于对整体测试流程进行层次化分解与状态追踪,并据此生成下一步高层测试策略;
- 生成模块将高层任务拆解为更细步骤,再转为具体可执行动作;通过把“全局任务上下文”与“当前动作上下文”隔离,减少长上下文带来的误导。
- 解析/压缩模块把冗长工具输出与原始信息流压缩为关键要点,避免将大量噪声直接塞回 LLM,引发成本与注意力偏置。
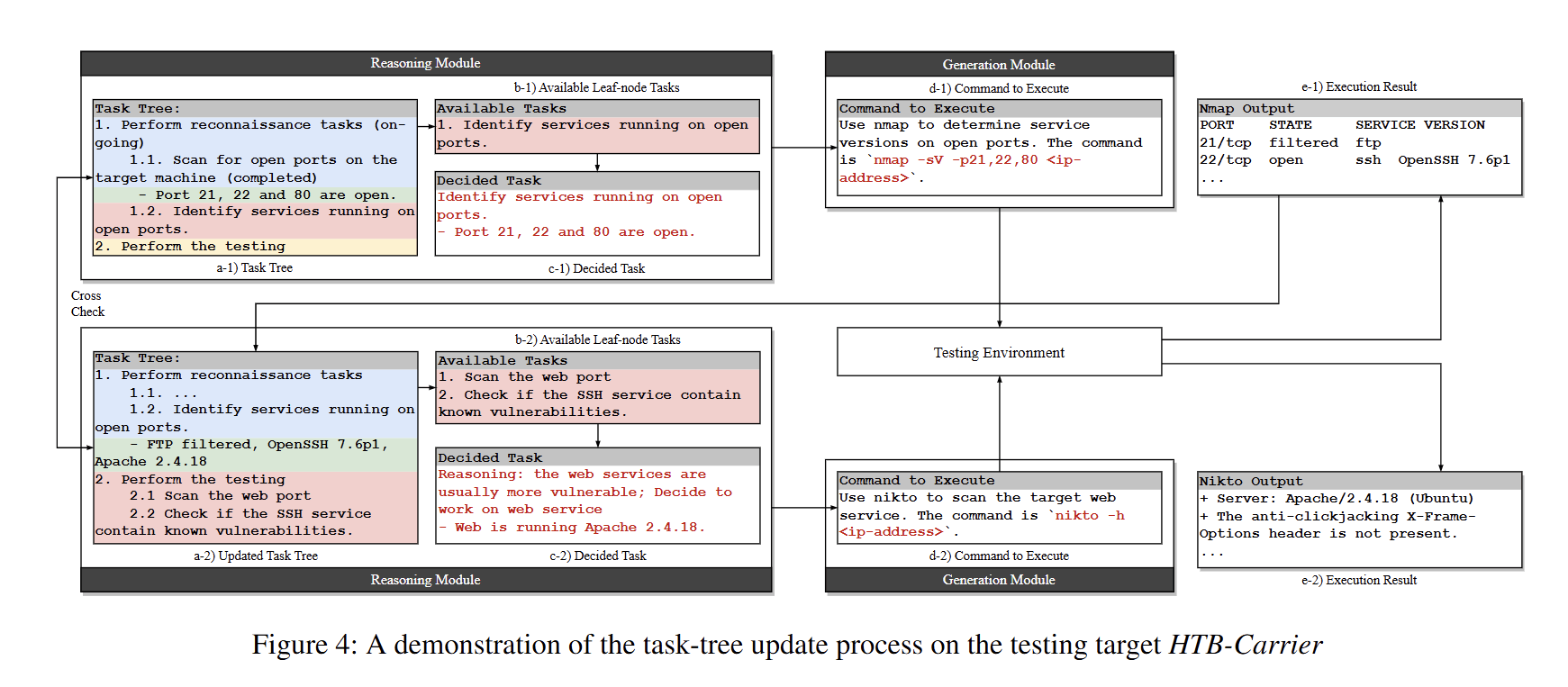
评估效果
在评估结果上,论文主要用“能否打穿靶机”和“能把多少步骤做完”两类更直观的指标来展示架构收益,结论可以压缩成下面几条:
- 在作者自建的 13 台 HTB/VulnHub 靶机基准中(共标注 182 个渗透子任务/步骤),直接用 GPT-4 交互式做渗透时,最终能拿到目标权限/关键成果的靶机是 5/13;换成 PentestGPT 并接入 GPT-4 后提升到 8/13,并且覆盖到更多中等难度靶机。
- 同一基准里,如果按“完成了多少渗透步骤”来衡量(例如枚举→识别服务→验证漏洞→利用→提权等),论文给出的分难度统计是:
- GPT-4:easy/medium/hard 分别完成 52/27/8
- PentestGPT + GPT-4:easy/medium/hard 分别完成 69/57/12
- 论文还给了一个汇总口径:在该基准的“任务完成率”统计下,PentestGPT 相比直接使用 GPT-3.5 的提升为 228.6%,相比直接使用 GPT-4 的提升为 58.6%。
另外两组“更像真实使用”的外部验证也可以作为补充指标:
- Hack The Box Active Machines(10 台、每台最多尝试 5 次):以“同一台机器 5 次里至少成功拿到 root flag 1 次”作为该机器成功标准,PentestGPT + GPT-4 共覆盖 5 台(4 台 easy + 1 台 medium),并报告总 API 成本约 131.5 美元。
- picoMini CTF(21 题):PentestGPT + GPT-4 解出 9/21,累计 1400 分,在 248 支有效提交队伍中排名第 24。
这一步的范式意义在于:把“LLM 很聪明但不稳定”的问题,转成可工程化的三个接口:状态表示(PTT)、策略选择(Reasoning)、动作落地(Generation)与信息压缩(Parsing)。
VulnBot:用 PTG 把多阶段渗透做成“可编排的 DAG”
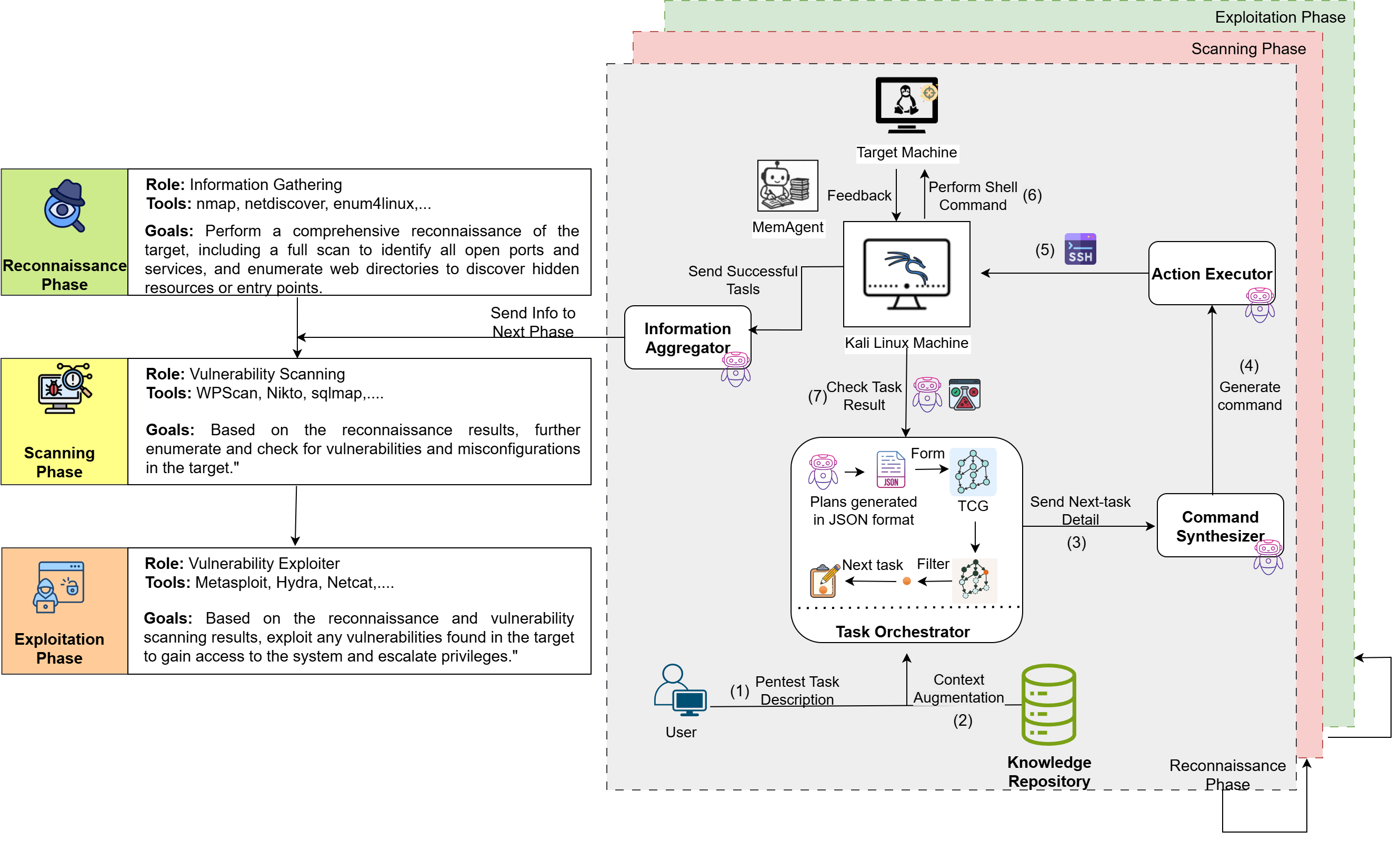
尽管状态外置机制有效缓解了记忆衰退,但单体模型在面对跨度极大的不同测试阶段(如从网络侦察的广度搜索转向特定服务漏洞利用的深度挖掘)时,仍显得力不从心。随后的研究范式开始向多智能体协同(Multi-Agent Systems)演进。例如,VulnBot 框架将渗透测试重新定义为一组专门化 LLM 智能体之间的协作工作流。与此前以树状结构刻画流程的做法不同,VulnBot 放弃了单一路径假设,该框架引入了“渗透任务图”(Penetration Task Graph, PTG)来作为智能体协作的刚性约束,强制规定了从侦察、扫描到利用的阶段顺序,有效遏制了模型在缺乏明确线索时盲目开辟无效攻击分支的倾向。PTG 被形式化为一类有向无环图(Directed Acyclic Graph, DAG),能够精确建模多阶段任务之间复杂的前置与后置依赖关系,从而保证侦察、扫描与漏洞利用等任务在逻辑一致、无冲突的约束下自主推进。
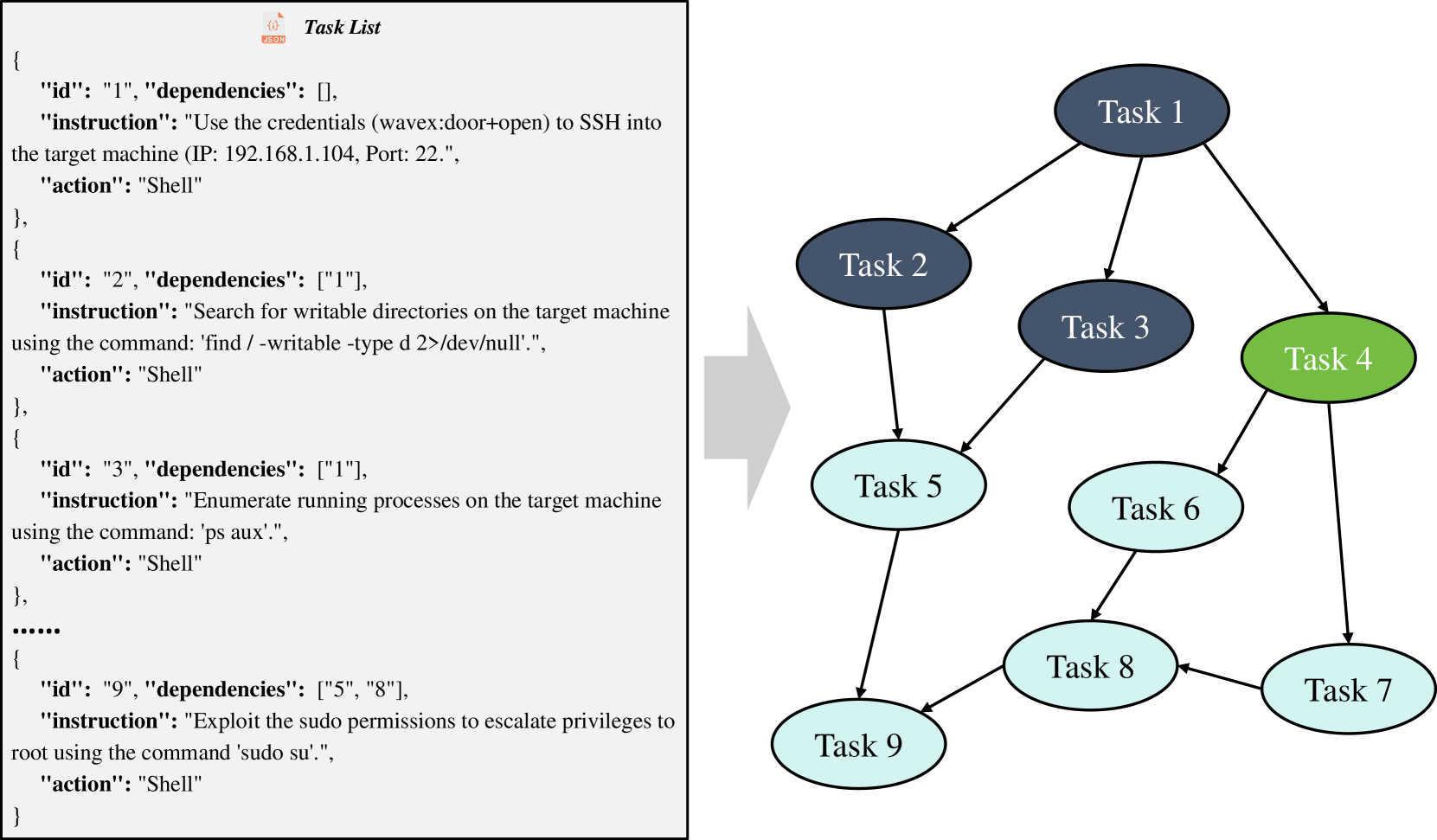
在具体实现上,VulnBot 将渗透测试流程划分为**侦察(Reconnaissance)—扫描(Scanning)—利用(Exploitation)**三个阶段,并通过 PTG 显式表达跨阶段任务的依赖结构与执行顺序。围绕该图结构,系统设计了一组协同工作的核心模块:Planner 负责构建和更新任务图,Generator 将高层任务转化为具体命令或动作,Executor 执行实际操作,Summarizer 在阶段边界对执行结果进行压缩与抽象,而 Memory Retriever 则在需要时检索历史上下文以补全关键信息。该架构把“跨阶段推理”明确落地为“图结构 + 摘要通信”的工程化对象:任务图负责约束顺序与依赖,摘要模块负责控制信息流规模,记忆检索则在需要时补全历史。
在实验评估方面,VulnBot 的论文报告显示,其在 AutoPenBench 上的子任务完成率与整体任务完成率均有显著提升,并在 AI-Pentest-Benchmark 的部分真实靶机环境中表现出更稳定的端到端执行能力。进一步的消融实验表明,移除 PTG 或 Summarizer 等关键组件都会导致性能明显下降,验证了图结构建模与阶段性摘要通信在系统中的核心作用。
总体而言,VulnBot 将渗透测试任务的组织方式从以往的树结构(PTT)推进到更具表达力的图结构(PTG),使复杂攻击链中的分支关系与依赖约束成为可显式操作的对象;同时,它将“人类渗透测试团队中的信息总结与交接机制”模块化地嵌入系统设计之中,为多智能体协同渗透提供了一种更可控、可扩展的工程范式。
评估效果
在评估结果上,论文主要用了两套基准:一套是 AUTOPENBENCH(按 Access Control / Web Security / Network Security / Cryptography / Real-world 分类),另一套是更贴近真实靶机的 AI-Pentest-Benchmark(13 台 VulnHub 机器中选 6 台做评测;每台跑 5 轮,取最好的一次表现;并限制步骤预算:AUTOPENBENCH 15 steps、AI-Pentest-Benchmark 24 steps)。
- 整体目标完成率:在 AUTOPENBENCH 上, VulnBot-Llama3.1-405B 在 ALL 类别为 10/33=30.30%,高于 GPT-4o 的 7/33=21.21%,也显著高于把相同基座模型接到 PentestGPT 的 3/33=9.09% 以及 Llama3.1-405B 的 3/33=9.09%。分项上,VulnBot-Llama3.1-405B 在 AC 达到 60%,Real-world 达到 27.27%。
- 子任务完成率:在 AUTOPENBENCH 上:
- 只运行一次的情况下(1 Experiment,Total Subtasks=210):VulnBot-Llama3.1-405B 达到 145/210=69.05%,对比 base Llama3.1-405B 的 103/210=49.05%,以及 PentestGPT-Llama3.1-405B 的 84/210=40.00%。
- 运行五次的情况下(5 Experiments,Total Subtasks=1050,要求 5 次都完成):VulnBot-Llama3.1-405B 为 524/1050=49.90%,对比 base Llama3.1-405B 的 260/1050=24.76%,以及 PentestGPT-Llama3.1-405B 的 181/1050=17.24%。
- 组件增益(消融实验,AUTOPENBENCH):去掉角色分工后,subtask 成功数从 55 降到 32;去掉 PTG 降到 37;去掉 Summarizer降到 27;且只要移除任一组件,整体的任务成功率会被“直接清零”。
- 真实靶机表现(AI-Pentest-Benchmark,6 台机器):VulnBot-Llama3.1-405B 在 Victim1/Library2/WestWild 上的 subtask completion rate 分别达到 0.33/0.40/0.57;VulnBot-DeepSeek-v3 在 Victim1 与 WestWild 上分别达到 0.83 与 0.71。
PentestAgent: Multi-Agent + RAG,多智能体编排与领域知识的检索增强
然而,无论是通用模型还是多智能体网络,都面临着一个共同的领域知识鸿沟:LLM的训练数据存在固有的时间截断特性,导致模型无法掌握最新披露的通用漏洞披露(CVE)细节或即时更新的漏洞利用代码(Exploit)。
为了填补这一领域知识鸿沟并解决短期记忆问题,2024 年 11 月提出的 PentestAgent 框架在架构上实现了改进 。其在 PentestGPT 的基础上,把瓶颈进一步明确成两类:渗透知识不足与自动化不足,并用“ Multi-Agent + RAG + 结构化输出”把知识检索、计划与执行串起来。
该框架采用 Multi-Agent 协同架构,将流程硬性切分为情报收集、漏洞分析和漏洞利用三个阶段,并为每个阶段分配了专属的智能体与工具集 。为了解决知识陈旧的问题,PentestAgent 在渗透测试框架中深度整合了检索增强生成(Retrieval Augmented Generation, RAG)技术。在模型进行响应合成之前,RAG 模块会从外部安全数据库中动态检索最新的漏洞文档和攻击技术,将其作为补充上下文注入给模型 。
此外,通过引入思维链(Chain-of-Thought, CoT)技术与执行反馈进行迭代修正,智能体能够在执行前对其生成的攻击载荷进行逻辑推演和错误修正 。在基于 VulHub 和 HackTheBox 的综合基准测试中,PentestAgent 的情报收集完成率、漏洞利用成功率、漏洞利用效率都得到了提升,例如在某些任务中,耗时仅为 PentestGPT 的三分之一,漏洞利用成功率从 30% 升至 70% 。
评估效果
在评估效果上,论文把“是否真正跑通一次自动化渗透”拆成了更可落地的三类指标:整体成功率、分阶段完成度、以及时间/成本开销。作者构建了一套可复现实验集:以 VulHub 的易受攻击 Docker 环境为主体,每个任务给定目标(IP/服务),要求系统从零开始完成侦察/指纹识别→漏洞定位与匹配→选择/生成并运行 exploit,直到得到利用成功的结果;此外还额外纳入 11 个 HackTheBox CTF 挑战用于更贴近真实的实用性研究与对 PentestGPT 的对比实验,并按 easy/medium/hard 做难度分层评估。
- 整体成功率(从给定 IP 出发,能否自动拿到可用 exploit 并成功打进目标):在基准任务上,PentestAgent 以 GPT-4 为底座的总体成功率为 74.2%,GPT-3.5 为 60.6%。
- 分阶段完成度:作者把流程拆成信息收集(识别出目标应用/服务)、漏洞分析(找到并人工验证可用 exploit)、漏洞利用(自动执行 exploit 并拿到访问权限)三段,并给出完成度统计。例如在 easy 任务上,GPT-4 在信息收集与漏洞分析阶段都能做到 100% 完成,而在漏洞利用阶段为 81.8%;在 hard 任务上,GPT-4 的信息收集完成度降到 50%,显示难点主要集中在更复杂的侦察/指纹识别与后续利用环节。
- 效率与成本:论在消融实验中,PentestAgent 对不同 LLM 底座统计了每个目标平均耗时(I.G./V.A./E 三阶段,秒)+ 平均 API 成本(美元)。结果显示,GPT-3.5 的总耗时更低且成本最低(约 $1.1/target),但利用阶段完成度偏弱;o1-mini 成本更高(约 $2.0/target),且在漏洞分析阶段耗时更长;GPT-4 成本最高(约 $2.6/target);Llama 3.1-8B-Instruct 虽然几乎无 API 成本,但时间开销显著偏大,尤其在漏洞分析阶段接近 1.2×10^4 秒量级。
- 与 PentestGPT 的对照:作者用 HackTheBox 目标做案例比较(两者都用 GPT-3.5 ),给出非常直观的时间差:PentestAgent 的信息收集平均 220 秒,而 PentestGPT 为 1199 秒;PentestAgent 的漏洞利用平均 172 秒,而 PentestGPT 为 364 秒。作者解释 PentestGPT 由于需要人参与反馈与决策,使得整体效率被拉慢。
TermiAgent: 上下文精准激活与漏洞利用标准化
在解决长周期渗透测试中的“上下文遗忘”问题上,TermiAgent框架提出了更具针对性的解决方案。传统的多智能体系统在漫长的测试中往往会被海量无关历史数据淹没。TermiAgent 的关键创新,正是在系统层面重新定义了“记忆”与“漏洞利用”在智能体决策过程中的角色,并通过二者的协同设计,构建了一个以获取 shell 为唯一目标的长期决策闭环。在该系统中,Located Memory Activation(LMA)与 Exploit Arsenal 构成了两个相互协作的关键子系统,分别解决了长时记忆失控与漏洞利用不可解释这两个在既有工作中普遍存在的问题。
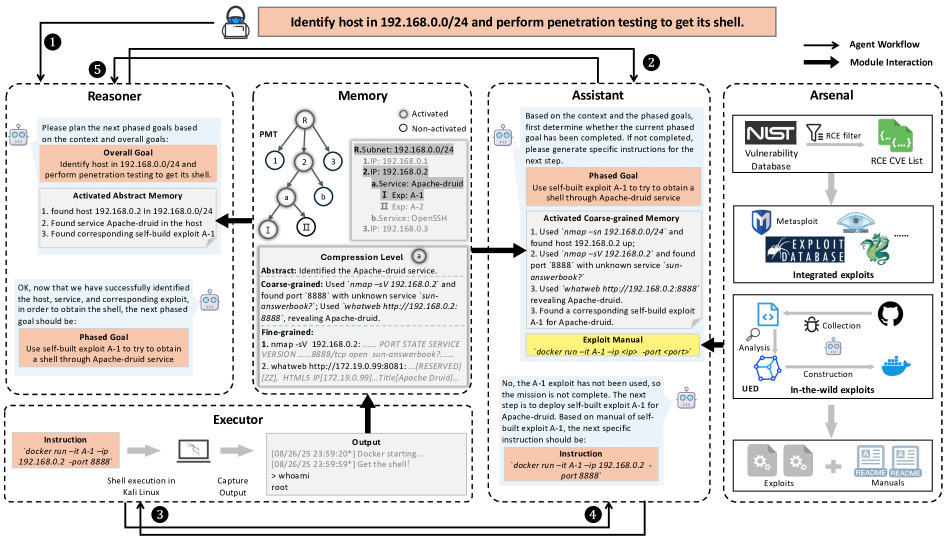
LMA 的核心思想是:在不同的执行阶段,智能体所需要关注的信息类型是不同的。为此,TermiAgent 在每轮决策前会先识别当前所处阶段,并仅激活与该阶段和当前攻击路径相关的上下文来构造提示输入。例如在漏洞利用阶段,模型主要需要围绕目标服务与版本线索、当前假设以及最近几次利用尝试的成败证据来决定下一步动作,而不必反复回顾早期扫描阶段的大量原始输出或无关历史命令。
为了实现这种“按位置、按阶段”的记忆选择,TermiAgent 将一次端到端渗透过程外置为一棵渗透记忆树(Penetration Memory Tree, PMT):树的节点记录某个决策点的执行上下文(已发现服务、假设、动作及结果等),边表示一次分支决策(选择入口/服务、切换 exploit 方案、转向提权路径等);当流程进入新的阶段或切换到新的探索分支时,系统在当前节点下派生子节点并将后续交互写入相应分支。随后,LMA 通过从当前节点沿 PMT 向根节点逆向回溯,仅聚合该分支上的祖先链记忆作为当前决策上下文,从而在保留关键证据链的同时有效抑制其他分支带来的冗余与噪声。
在具体实现上,系统还会将历史交互按功能划分为若干记忆槽(例如侦察结果、服务指纹、漏洞利用尝试、权限状态、网络结构等),并为各决策阶段定义明确的激活规则:每次决策只将与当前认知任务直接相关的记忆子集“升温”并注入模型上下文,其余信息保持“冷却”状态。由此形成的决策点驱动记忆激活机制,使智能体在长链路任务中既能维持必要的全局一致性,又能避免上下文膨胀对推理与行动稳定性的破坏。
然而,仅有可控的记忆机制仍不足以支撑稳定的攻击策略收敛。为此,TermiAgent 进一步提出 Exploit Arsenal,对漏洞利用在系统中的抽象方式进行了重构。与传统将 exploit 视为脚本或外部工具不同,Exploit Arsenal 将每一个漏洞利用建模为具有明确语义边界的动作原语(action primitive)。具体而言,每个 exploit 被拆解为前置条件、执行动作、可解析观测以及结果语义四个部分,其中前置条件用于约束适用场景,结果语义则对失败进行细粒度分类,而非仅返回成功或失败。
这一设计的关键意义在于:exploit 的失败首次被系统化地转化为可推理的信息,而非被动日志输出。不同类型的失败模式会被写入专门的 exploit 记忆槽,并直接影响后续策略分布,例如降低同类远程代码执行漏洞的优先级,或引导系统转向配置缺陷、认证绕过或横向移动等替代路径。由此,漏洞利用不再是一次性的尝试行为,而成为长期策略优化过程中的重要反馈信号。例如如果某个 exploit 多次因为 connection_reset导致执行失败,则 TermiAgent 会推断是否是因为 WAF 或者 crash ,从而降低该 exploit 的权重转向其他尝试。
在整体架构中,LMA 与 Exploit Arsenal 形成了紧密耦合的决策闭环:LMA 决定在特定决策位置“应该想起什么”,而 Exploit Arsenal 则保证这些被激活的记忆具备清晰、可计算的语义边界,使失败经验能够被累积、对比并用于策略调整。正是通过这一协同机制,TermiAgent 才得以在真实世界复杂环境中避免盲目重复尝试,并逐步收敛到更具攻击价值的行动路径。
评估效果
在评估结果上,作者围绕“更贴近真实渗透”的 TermiBench 与“偏 CTF 的 Auto-Pen-Bench”两类场景,给出了 TermiAgent 相对既有系统的增益,并进一步用限信息设置、轻量模型与消融实验解释这种增益来自哪里。
- 在 CTF 场景(Auto-Pen-Bench,33 题)上,TermiAgent 的整体通过数为 10–15/33(随底座模型变化),而 VulnBot 为 4–9/33、PentestGPT 为 0–4/33;以 DeepSeek-V3 为例,TermiAgent 为 15/33,VulnBot 为 9/33,提升约 1.67 。
- 在真实渗透场景(TermiBench 抽样 230 台主机,目标为拿到交互式 shell,结果以 “shell/root shell” 计)上,TermiAgent 能在不同底座模型下获得 91–131 个 shell(其中 root shell 为 46–60),而 VulnBot 仅 3–15 个 shell,PentestGPT 为 0;同样以 DeepSeek-V3 为例,TermiAgent 为 128/46,VulnBot 为 15/9,约 8.5× 的差距。
- 在“限信息”设定下(将任务输入压缩为最小必要信息,仅提供子网范围与目标主机,不再给出额外背景与提示),TermiAgent 的通过数从 15 降到 8(DeepSeek-V3)或从 15 降到 10(Qwen3-30B);而 VulnBot 从 9 降到 3、从 7 降到 2(分别下降 66.67% 与 71.43%)。作者据此指出 VulnBot 更依赖额外提示,而 TermiAgent 在信息更接近真实红队场景时仍能保持可用表现。
除成功率外,论文还用“轻量模型可用性 + 成本”补充说明其工程意义:
- 轻量模型兼容性:在同一组 230 台 TermiBench 主机上,TermiAgent 使用 Qwen3-4B 仍能完成 137/230(shell/root 为 137/58),Qwen3-1.7B 也能完成 67/230;而 VulnBot 在 Qwen3-30B 仅 5/230,在 1.7B 为 0。
- 成本与时间:在作者选取的“双方都能攻陷”的交集目标上,CTF 场景两者平均耗时与费用接近;但在真实渗透场景,TermiAgent 平均耗时 11.7875 分钟、平均成本 0.0074 美元,而 VulnBot 分别为 63.1402 分钟与 0.0996 美元(约 18.67% 时间、7.43% 成本)。
最后,消融实验把性能增益“拆开解释”:
- 去掉 Arsenal Module:在 Qwen3-30B 上,成功数从 118 降到 83(下降 29.66%)。
- 去掉 Located Memory Activation(用“把完整 PMT 全塞进上下文”的方式替代):118 个成功目标中有 79 个不再能攻陷,等价于成功数降到 39(下降 66.95%),且失败主要集中在服务数更多的主机上。
多阶段复杂漏洞场景下的阶梯学习与经验重用
现有多智能体系统在单点漏洞验证或较短的线性攻击链上往往能取得不错表现,但一旦进入需要跨阶段协调、深度上下文推理、以及跨场景复用经验的复杂漏洞场景(尤其是安全关键系统与大型企业级基础设施),就会迅速遭遇组合爆炸:可探索的行动分支成倍增长,前置条件之间相互牵制,任何一步偏差都可能让后续路径整体失效。为突破这一上限,研究开始把注意力从单纯的任务分解与并行协作,转向更接近人类专家工作方式的两类能力:阶梯式技能习得,以及可迁移的经验重用。
随着大语言模型在独立子任务上的执行与推理逐步成熟,研究重心也从单步自动化推进到端到端、长链路的真实攻击过程。在真实黑盒环境里,渗透更像一条深度耦合的多阶段链路:例如先通过目录枚举锁定隐藏管理入口,再借助注入类缺陷获取凭证材料,随后离线破解或凭证填充获得可登录凭证,最终进入主机侧横向移动与权限提升。此类链路的关键困难不在于某个工具是否会用,而在于跨工具、跨阶段、跨语义的前置依赖如何被持续满足,以及失败后如何回退、改道并重用已获得的证据。
在这种背景下,早期以树状任务分解为核心的建模方式(如 PTT)逐渐显露出与标题所强调目标不匹配的结构性局限:树结构更擅长表达单向推进的流程,却不擅长表达经验复用与条件共享。当前置条件在不同分支间可复用、或多个阶段存在交叉依赖时,系统容易出现三类问题:相同枚举被反复执行、状态分叉难以收敛、以及在未满足关键依赖时过早深入导致不可恢复的死胡同。换言之,挑战已经从把任务拆开变成如何让系统在复杂图状依赖里稳定推进,并把过去的成功片段迁移到新情境中。
如果说 PentestGPT 的核心贡献在于解决长周期渗透中的上下文一致性与流程不迷航,那么 2025 年前后的一系列工作则更贴近把问题前移到复杂漏洞链路的可持续推进上,重点引入两种机制来对抗组合爆炸。其一是阶梯学习:让智能体从可控的简单任务逐步积累技能与策略,而不是每次面对复杂目标都从零开始盲搜。其二是经验重用:把已验证的证据、有效的行动序列与失败模式结构化沉淀,使其能在后续相似场景中被快速检索与迁移,从而减少重复试错、提升决策稳定性,并在执行过程中具备自我纠错与持续推进能力,而不是中途崩溃或停滞。
CurriculumPT:把“课程学习 + 经验知识库”引入多智能体渗透
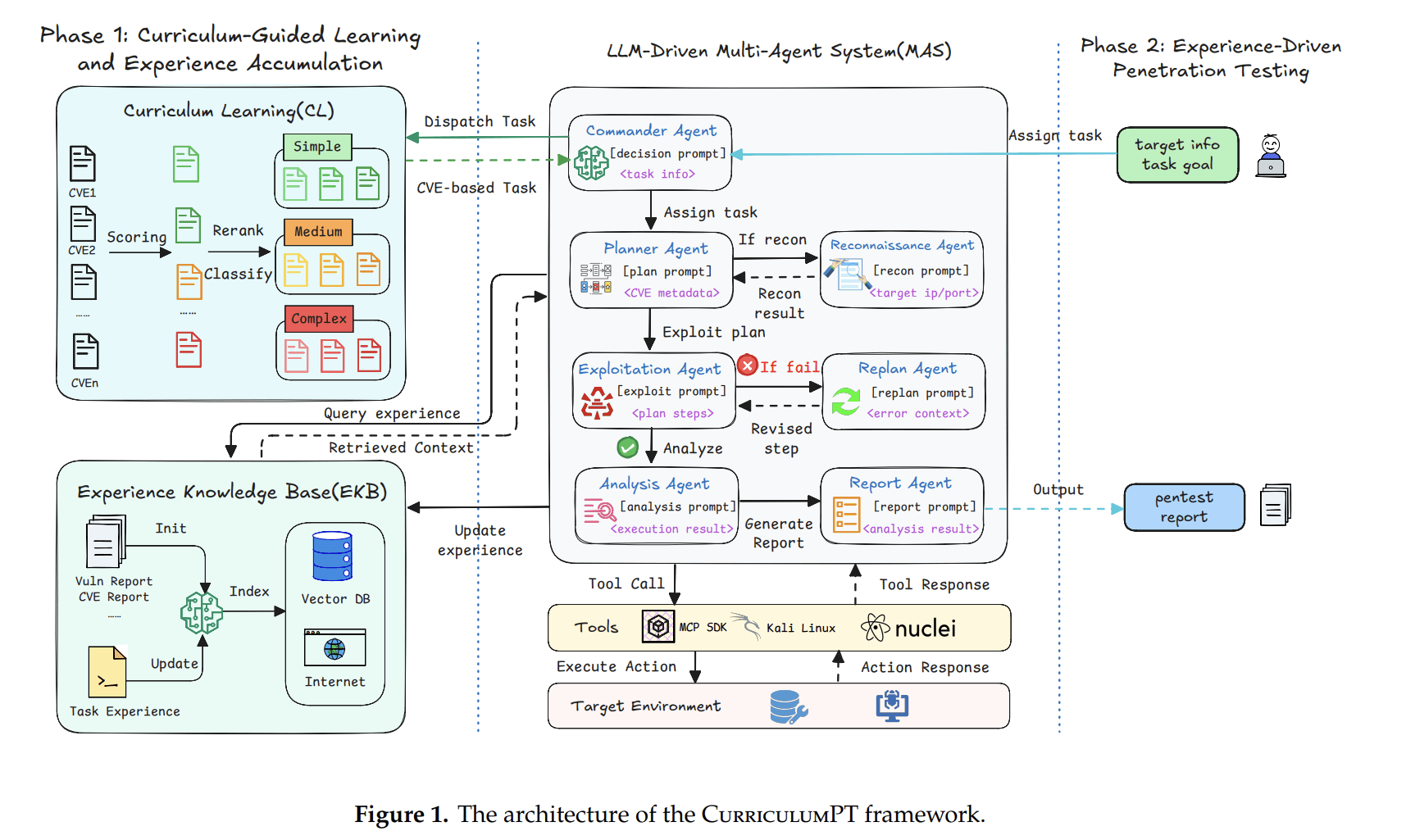
2025 年提出的 CurriculumPT 框架标志着自动化渗透测试研究范式的一次重要转向。与以往将渗透测试建模为单次“规划—执行”问题的工作不同,CurriculumPT 将其重新定义为一个持续学习与技能迁移(continual learning and skill transfer)的问题:系统的能力不应仅依赖即时推理,而应随着实践不断积累和演化。
CurriculumPT 的核心思想是将机器学习中的**课程学习(Curriculum Learning)**引入 LLM 驱动的渗透测试系统,使智能体能够像人类安全专家一样,从简单漏洞出发,逐步过渡到复杂、多阶段攻击链,在实践中形成可复用的攻击经验。为实现这一目标,框架在整体设计上引入了三项关键机制:课程驱动的任务调度机制、多智能体协同执行架构,以及显式的经验知识库(Experience Knowledge Base, EKB)。
从整体目标上看,CurriculumPT 并不假设模型在系统启动时就具备处理复杂渗透任务的能力,而是将渗透测试过程明确设计为一个逐步积累经验的学习过程。系统初始状态下并不包含任何预定义的攻击模板或策略库,仅拥有一个由大量 CVE 复现环境构成的任务池。与传统方法直接随机或并行执行这些任务不同,CurriculumPT 的第一步是对每一个 CVE 利用任务进行系统化的难度建模。
具体而言,对于任意一个 CVE 任务 $t$,系统从以下四个维度刻画其学习与执行难度:
- Attack Complexity (AC):漏洞利用对攻击条件的依赖程度,对应 CVSS 中的攻击复杂度指标;
- User Interaction (UI):漏洞利用是否依赖用户参与(如点击、打开文件等);
- Privileges Required (PR):漏洞利用是否需要已有权限或权限提升;
- Exploitation Steps (ES):完成漏洞利用所需的操作步骤数量。
其中,AC、UI 与 PR 可直接由 CVSS 信息获得,而 ES 则通过对公开复现文档、PoC 说明以及漏洞分析文本进行解析,并由 LLM 辅助估计得到。所有指标均被归一化到 $[0,1]$ 区间,并通过加权线性组合计算任务整体难度:
$$ D(t) = \lambda_1 \cdot AC(t) + \lambda_2 \cdot UI(t) + \lambda_3 \cdot PR(t) + \lambda_4 \cdot ES(t) $$其中权重设置为:
$$ \lambda_1 = 0.3,\quad \lambda_2 = 0.2,\quad \lambda_3 = 0.2,\quad \lambda_4 = 0.3 $$该设计强调攻击条件复杂度与操作链长度在学习难度中的主导作用。
基于计算得到的难度分值,系统将所有 CVE 任务划分为离散的课程层级,例如简单、中等与复杂:
$$ \text{Level}(t) = \begin{cases} L_1 & D(t) < 0.4 \\ L_2 & 0.4 \le D(t) < 0.7 \\ L_3 & D(t) \ge 0.7 \end{cases} $$在实际执行阶段,CurriculumPT 并不会同时尝试不同难度层级的任务,而是严格从最低难度层级开始。这些任务通常具有依赖少、步骤短、复现稳定等特点,适合作为系统的“基础练习”。在单个任务内部,系统仍采用多智能体协同方式完成完整的渗透流程,包括攻击规划、信息收集、漏洞利用执行以及失败后的策略调整。这一执行层面的流程与现有多智能体渗透测试框架在形式上并无本质差异。
在应对复杂的多阶段漏洞时,单次利用尝试失败是常态。CurriculumPT采用两阶段设计来确保系统的鲁棒性。在“学习与积累阶段”,如果漏洞利用步骤遭遇挫折,Replan Agent 会立即介入,触发类似 ReAct 的反馈循环。它会深入分析错误上下文,并向 EKB 查询历史上类似错误的解决范式,动态生成修正后的攻击步骤。当任务最终成功时,Report Agent 负责提取极具价值的实战情报,包括成功的非标准利用策略、特定的工具链组合以及关键决策背后的逻辑基准,并将其结构化存储入EKB 。
随着系统在低难度任务中的不断实践,经验知识库逐步积累起一批可复用的攻击套路与问题解决模式。同时,系统会持续评估自己在当前难度层级下的整体表现。当该层级任务的成功率稳定达到预设阈值后,系统才会进入更高难度的课程阶段;若在某一层级频繁失败,系统则会放缓难度提升节奏,通过继续执行相对简单的任务来补充经验,而非强行推进。
当系统进入中等或高难度任务时,其攻击规划已不再完全依赖即时推理。在生成新的攻击方案之前,Planner Agent 会首先基于当前任务特征 $f(t)$,从经验知识库中检索与漏洞类型、目标服务或失败模式相似的历史经验:
$$ E^{*} = \operatorname{Retrieve}(\text{EKB}, f(t)) $$随后,这些经验会与当前任务描述共同作为上下文输入,用于生成新的攻击计划:
$$ \pi_t = \operatorname{Plan}(t, E^{*}) $$因此,在高难度场景中,系统的推理过程更多表现为对既有经验的组合、调整与迁移,而非从零开始的反复试错。
通过上述机制,CurriculumPT 将渗透测试从一系列彼此独立的任务,转变为一个连续的学习过程。系统能力的提升并非通过模型参数更新实现,而是通过“任务难度控制 + 经验显式积累”的方式逐步形成。其最终优势不在于掌握更多漏洞细节,而在于面对新漏洞时,能够像有经验的渗透测试人员一样,快速调用过往实践中沉淀的攻击思路与操作模式。
评估效果
在评估结果上,论文主要从“随难度递进的整体表现(RQ1)—与代表性框架对比(RQ2)—关键组件消融(RQ3)”三条线来呈现 CurriculumPT 的收益。
- 其一,在分级课程(Simple/Medium/Complex)与混合难度上,CurriculumPT 的成功率随难度上升而下降,但仍保持整体完成度:Level 1 为 95.3%±4.7,Level 2 为 75.0%±7.1,Level 3 为 60.0%±8.1;在未见过的场景上漏洞利用成功率为 66.7%±7.8,且经验复用命中率(EHR)维持在 80.0%(120/150),体现出一定的泛化与可迁移性。
- 其二,在与 AutoPT、VulnBot、PentestAgent 的对比中,作者强调 CurriculumPT 在同一底座模型与一致环境下取得“更高成功率 + 更低开销”的组合收益:论文概括其相对其他最强的基准框架最多可带来 18% 的成功率提升,同时平均执行时间降低约 20.6%、token 消耗降低约 25.5%,且决策步数最少;作者并给出该组对比实验中 CurriculumPT 的核心指标为 ESR 60.0%、ATE 390s、ATU 3.5M tokens、AST 5.1。
- 其三,在消融实验中,作者把收益拆解为“课程调度机制”与“经验知识库”的互补贡献:完整配置在复杂任务上可维持 60.0% 的成功率;移除经验知识库后复杂任务成功率降到 43.3%,移除课程调度(但保留经验知识库)则因缺乏系统性技能积累而进一步变差;两者都移除时整体最低成功率仅 33.3%,同时平均用时、推理消耗与推理开销显著上升。
| 核心组件配置变体 | 漏洞利用成功率 (ESR) | 平均利用耗时 (ATE) | 平均Token消耗量 (ATU) | 平均推理-执行迭代步数 (AST) |
|---|---|---|---|---|
| 完整系统配置 (CurriculumPT) | 60.0% | 370秒 | 5.6M | 5.5 |
| 移除经验知识库 (No EKB) | 43.3% | 400秒 | 5.9M | 5.8 |
| 移除课程学习 (No CL) | 40.0% | 390秒 | 5.6M | 5.7 |
| 基础配置 (No CL + No EKB) | 33.3% | 450秒 | 6.2M | 6.0 |
领域微调与自主推理能力的批判性评估
在验证了多智能体编排和经验重用的有效性后,学术界和工业界开始反思过度依赖昂贵的闭源前沿模型(如GPT-4o、Gemini 2.5 Pro)的局限性。这些超大规模通用模型虽然在自然语言理解上表现卓越,但它们并未专门针对网络攻击的严苛逻辑和隐蔽特征进行内化训练。此外,闭源模型的高昂调用成本和隐私数据外泄风险,也阻碍了其在企业级自动化安全扫描中的无限制部署。
xOffense:从更大模型转向领域微调和编排
 这一痛点催生了基于深度领域微调(Fine-tuning)的本地化智能体架构,其中 xOffense 框架给出了自己的解决方案。其研究团队指出,过度依赖 GPT-4o、LLaMA3-70B 等超大型通用模型,不仅带来极高的推理成本,更在复杂、多阶段的渗透测试场景中暴露出严重的可靠性问题:模型容易在长链条推理中产生“幻觉”,错误地翻译工具指令,或在不断演化的网络状态中迷失攻击逻辑。这一现象表明,单纯依靠更大的通用模型,并不能保证黑盒渗透任务的稳定性。
这一痛点催生了基于深度领域微调(Fine-tuning)的本地化智能体架构,其中 xOffense 框架给出了自己的解决方案。其研究团队指出,过度依赖 GPT-4o、LLaMA3-70B 等超大型通用模型,不仅带来极高的推理成本,更在复杂、多阶段的渗透测试场景中暴露出严重的可靠性问题:模型容易在长链条推理中产生“幻觉”,错误地翻译工具指令,或在不断演化的网络状态中迷失攻击逻辑。这一现象表明,单纯依靠更大的通用模型,并不能保证黑盒渗透任务的稳定性。
xOffense 对此作出了一个关键性的理论判断:黑盒渗透测试本质上并非信息检索或命令生成问题,而是一个高度条件化的进攻决策过程。一个漏洞是否值得尝试,往往取决于多个隐含前提是否同时成立,例如版本区间是否精确匹配、服务是否以特定模块或配置方式部署、返回的错误信息是否支持当前漏洞假设,以及继续尝试的边际收益是否高于切换攻击面。这类判断在真实红队中几乎是下意识完成的,但对通用大语言模型而言并非其预训练目标的一部分。通用模型更擅长生成“看似合理的下一步”、复述已有知识,或在不确定时“尝试看看”,而这种行为模式在渗透测试中往往正是导致失败的根源。
基于上述认识,xOffense 将问题重新定义为:自动化渗透测试的核心瓶颈不在于漏洞知识是否充足,而在于是否具备对“进攻条件是否成立”的稳定判断能力。这种能力无法通过检索增强或提示工程获得,只能通过针对性训练习得。因此,作者认为,仅依赖 prompt engineering、RAG 或多智能体协作,已不足以从根本上解决问题,必须引入一个经过进攻决策对齐的微调模型。
xOffense 的核心技术突破在于其训练数据的构建与注入方式。研发团队利用极其精细的“思维链”(Chain-of-Thought, CoT)渗透测试数据对 Qwen3-32B 进行了深度微调。这种微调不仅仅是赋予模型安全领域的专业词汇,更重要的是让模型内化了多步攻击中的因果推理逻辑,使其能够生成极其精确且符合语法规范的漏洞利用工具调用指令,并在面临复杂网络防御时展现出高度一致的多步推理能力 。
在具体实现上,xOffense 选择 Qwen3-32B 作为模型基座,并对其进行所谓的 Offensive Knowledge–Enhanced 微调。与常见以 CVE 文档或漏洞描述为中心的安全微调不同,该过程遵循两个明确原则。
首先,训练样本不以“漏洞事实”为中心,而以“进攻推理过程”为中心。每一条训练数据通常包含如下结构化逻辑链条:
- 给定当前阶段可观察信息(如端口、服务、版本、返回错误)
- 明确列出可行的攻击假设
- 对每个假设进行条件验证或排除
- 选择“值得继续尝试”的攻击路径,或主动放弃
也就是说,模型并不是被教“Apache 2.4.49 有什么漏洞”,而是被反复暴露于类似这样的推理情境:“在 Apache 2.4.x 的情况下,为什么某个 CVE 在这个版本区间不可利用?失败信息意味着什么?下一步应当回退到哪个策略?”
其次,训练数据显式纳入大量“失败—反思—修正”的进攻轨迹。不同于早期系统主要展示成功 exploit 路径,xOffense 要求模型学习区分 exploit 失败的不同成因,并据此决定是尝试变体、彻底放弃该漏洞,还是回退至扫描阶段或切换攻击面。这一设计显著减少了自动化系统中最常见的一类错误:在 exploit 阶段对一个本不该打的漏洞反复投入资源。
从方法论角度看,xOffense 明确区分了两类能力:一类是信息获取能力,适合通过 RAG 等方式解决;另一类是进攻决策能力,只能通过训练获得。RAG 可以帮助模型检索漏洞或 exploit,但无法让其理解何时不该使用某个 exploit、为何某条失败信息比另一条更关键,以及在攻击链中当前阶段的最优行动是什么。因此,Offensive Knowledge–Enhanced 微调本质上是一种**认知对齐(Cognitive Alignment)**过程,即将模型的推理路径对齐至人类渗透测试专家的决策逻辑,而非单纯扩大知识覆盖面。
在系统运行阶段,xOffense 并未简单依赖不同 prompt 来塑造模型行为,而是通过微调使同一模型在不同阶段呈现出显著不同的推理侧重点:在侦查阶段关注信息覆盖率与扫描成本,在漏洞分析阶段关注条件验证与假设排除,在漏洞利用阶段则更加重视失败信号、回退策略与风险控制。由此,模型的行为更接近一组“角色化专家”,而非在不同阶段反复切换提示词的通用助手。
在流程控制层面,xOffense 进一步引入了灰盒提示(Grey-Box Prompting)机制。与 PentestGPT 的状态压缩不同,该机制压缩的并非是执行历史,而是决策前提。在阶段切换时,由集中式 Orchestrator 生成高度凝练的关键信息摘要,例如已被否定的漏洞假设、已确认的服务信息以及当前仍然成立的攻击路径,并将其作为前置条件注入下一阶段的 agent。这种设计为模型提供了类似“人类渗透笔记”的认知支点,有效避免了重复扫描与前后矛盾的决策。
进一步地,xOffense 认识到,即便模型具备正确判断能力并获得结构化信息输入,若其行动空间缺乏约束,仍可能在合法但不合理的路径上发散。为此,系统引入了任务控制图(Task Control Graph, TCG),以预定义有向图的形式刻画渗透测试中允许的高层动作转移关系。TCG 不记录执行状态,也不参与具体漏洞推理,而是在系统层明确限定在给定阶段下“哪些类型的操作是被允许的”,从而将流程合法性判断从语言模型中剥离出来。
从发展角度看,xOffense 的模型微调、灰盒提示与任务控制图三项设计共同标志着研究范式的一次收敛。与 PentestGPT 主要关注防止模型在长流程中“忘记做过什么”不同,xOffense 更关注如何防止模型在错误前提下持续行动。其核心思想不在于赋予语言模型更大的自主性,而在于通过判断能力对齐、认知输入约束与行动空间控制,将语言模型定位为一个受控的进攻决策模块。
评估效果
在评估效果上,xOffense 主要用 AutoPenBench(33 个任务)与 AI-Pentest-Benchmark(VulnHub 13 台机器中的 6 台代表靶机)两组实验,来验证“中等规模开源模型 + 领域微调 + 多智能体编排 +(可选)RAG”的叠加收益,结果可以概括为三层:
- 在 AutoPenBench 的端到端攻陷率(Overall task completion rate)上,Qwen3-32B-finetune 达到 24/33 = 72.72%,显著高于 GPT-4o 的 21.21%、VulnBot(Llama3.1-405B) 的 30.30% 以及 PentestGPT(Llama3.1-405B) 的 9.09%;同时,相比同尺寸的 Qwen3-32B-base(30.30%),微调带来约 2.4× 的攻陷提升率。
- 宽松成功率(跑 5 次里,只要有 1 次跑通就算这个子任务成功):Qwen3-32B-finetune 取得 79.17%,高于 VulnBot(Llama3.1-405B) 的 69.05%,也高于 Qwen3-32B-base 的 52.36%;作者强调这是在模型规模远小于 405B 的情况下取得的优势。
- 严格成功率(同一个子任务跑 5 次,必须 5 次都跑通才算成功):Qwen3-32B-finetune 成功率为 60.94% 仍保持领先,仍高于 VulnBot(Llama3.1-405B) 的 49.90% 与 Qwen3-32B-base 23.03%
在更贴近真实链路的 AI-Pentest-Benchmark(6 台靶机)实验中,作者分别报告了 No-RAG 与 RAG 两种设置下的变化趋势:
- No-RAG:Qwen3-32B-finetune 在 6 台机器上整体优于 Qwen3-32B-base,并在若干靶机上给出显著增益。对比 VulnBot-DeepSeek-v3,那么 xOffense(Qwen3-32B-finetune)逐机对比如下:
- Victim1:83% vs 83%(持平)
- Library2:60% vs 20%(+40 个百分点)
- Sar:58% vs 36%(+22 个百分点)
- WestWild:88% vs 71%(+17 个百分点)
- Symfonos2:42% vs 29%(+13 个百分点)
- Funbox:54% vs 44%(+10 个百分点)
- RAG:接入 Knowledge Repository 后,对比接入 RAG 后的 VulnBot :
- Victim1:xOffense 100%,高于最强基线 83%(+17 个百分点)
- Library2:xOffense 80%,与最强基线 80%(持平)
- Sar:xOffense 58%,低于最强基线 73%(-15 个百分点)
- WestWild:xOffense 100%,与最强基线 100%(持平)
- Symfonos2:xOffense 58%,高于最强基线 43%(+15 个百分点)
- Funbox:xOffense 63%,高于最强基线 56%(+7 个百分点)
PentestGPT V2 / Excalibur: 失败模式的分类学
尽管 xOffense 等系统取得了显著进展,但基于LLM的渗透测试系统在报告的性能上依然存在巨大的波动性。2026 新春伊始,Pentest GPT V2 把 LLM 驱动渗透测试智能体的瓶颈,从“模型更强/工具更多就会更好”进一步推进到一个更结构性的上限:复杂度壁垒(complexity barriers,文中对应 Type B failures)。作者系统梳理了 2023–2025 年间 28 个 LLM 渗透测试相关系统,并从中选取 5 个代表性方案,在三个复杂度逐级提升的基准上做对照评测。作者给出两个关键发现:
许多既有系统的设计,主要是在对冲当时底座模型的“暂时性短板”,例如上下文窗口有限、工具知识不足等,因此引入摘要、RAG、工具提示模板等工程补强。但当底座模型升级时(论文以 GPT-4o → GPT-5 为例),不同架构间的性能差距会明显收敛,说明这类“补短板式”设计不一定能与模型能力提升形成叠加效应,其边际收益会随模型变强而下降
更重要的是,失败原因可以清晰分为两类:Type A 能力缺口与 Type B 复杂度壁垒。
能力缺口 (Type A, capability gaps): 例如工具不会用、命令格式错误、输出解析不稳、知识陈旧等,这类问题通常可以通过更完善的工具封装、解析器与 RAG 补齐;
复杂度壁垒 (Type B, complexity barriers): 表现为长链任务中的上下文衰减、过早锁定某条路线、探索/利用失衡以及多阶段链路中途崩溃。
论文强调,真正决定 LLM Agent 渗透测试的上限的往往是 Type B,因为它并非“换更大模型/加更多工具”就自然消失,而是需要一种能够在执行过程中持续评估“这条路线还要多少步、证据是否足够、继续投入是否划算”的机制,才能避免智能体在低价值分支上耗尽预算与上下文。
为了解决复杂度壁垒问题,作者进一步把 Type B 的根因归结为:现有渗透测试智能体普遍缺少一种关键能力,即实时的任务难度评估(real-time task difficulty estimation)。这会带来非常直接的行为后果:智能体无法判断一条路径究竟是“再 3 步就能到目标”还是“可能要 30 步且高度不确定”,于是容易对低价值分支过度投入;同时缺乏“证据是否足够支撑进入利用阶段”的量化指标,导致侦察与利用切换失当;再加上不监控上下文消耗,长链对话更容易因上下文负载上升而推理质量静默退化并偏航。论文也强调,人类渗透测试员依靠经验形成“难度直觉”,而智能体需要把这种直觉机制化,才能避免在不产出强证据的分支上耗尽预算与上下文。
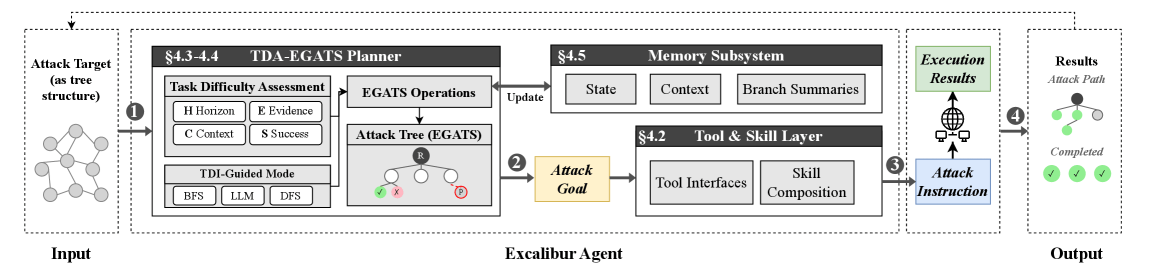
基于这一观察,论文提出 PENTESTGPT V2(并将其设计思想命名为 Excalibur),核心增量就是 Task Difficulty Assessment (TDA):用四个可测维度估计路径的可行性/可控性,并据此驱动搜索过程中的探索—利用决策与止损策略。
- Horizon Estimation:估计从当前状态到关键目标的“剩余步数/距离”。
- Historical Success Rate:利用相似尝试的历史成功表现,对重复失败进行抑制。
- Context Load:度量上下文窗口的消耗比例,并用它识别推理质量退化风险;论文还通过受控实验确定了可触发裁剪/压缩的经验阈值。
- Evidence Confidence:把“证据强弱”按可复现的规则打分,用来判断何时“证据已足够支撑进入利用”,何时仍应继续侦察。
上述四维信号会被组合成一个统一标尺 Task Difficulty Index (TDI)(论文给出显式公式),其直观含义是:失败累积、证据不足、上下文负载上升或历史成功率偏低时,TDI 会升高,代表“继续在该分支投入的边际价值在下降”。 TDI 随后触发三类关键控制决策:
- 模式选择(Mode selection):高 TDI(>0.6)偏向继续侦察扩展(更像 BFS);低 TDI(<0.3)偏向深入利用(更像 DFS);中间区间则把 TDI 与各维度分数交给 LLM 做一次带理由的裁决。
- 分支优先级(Branch prioritization):在“看起来同样有希望”的分支间,用 TDI 区分“可控/短期可达”和“高难低收益”。
- 剪枝止损(Pruning):当分支在至少 3 次尝试后仍长期保持高 TDI(>0.8),则剪枝以避免搜索坍缩为无意义循环。
在搜索框架上,TDA 被集成进 Evidence-Guided Attack Tree Search(EGATS)。EGATS 把一次渗透过程看成一棵不断生长的“攻击树”:每个节点是一条当前假设下的行动序列(做了哪些探测、得到了哪些输出、形成了哪些证据),每次扩展就相当于在某个分支上再走一步。系统在多个候选分支之间需要反复回答一个问题:下一步该继续深挖当前这条路,还是转去尝试别的攻击面?为此 EGATS 采用一个“打分选路”的策略(论文用 UCB 选择 (Upper Confidence Bound selection) 表达这种权衡思想):
- 如果某条分支带来的证据在变强、离目标看起来更近,它的优先级就会上升,系统更愿意继续沿着它深入(偏“利用”)。
- 如果某条分支反复尝试却没有新增强证据、失败累积、上下文负载变高,TDA 计算出的 TDI 会升高,这会作为“难度惩罚”压低该分支的优先级,促使系统及时转向其他分支或直接剪枝止损(偏“探索/回溯”)。
与依赖随机试探的传统蒙特卡洛树搜索 (Monte Carlo Tree Search, MCTS) 不同,EGATS 的更新与选择主要由可观测的证据信号与实时难度估计驱动。其效果是:在证据不足或难度持续上升的路径上及时减少投入,避免在不可行分支上耗尽上下文与预算;而当证据置信度达到阈值且 TDI 显示路径仍可控时,系统才将搜索重心转向更深层的利用步骤。
与此同时,论文还配套了一个检索增强的 Memory Subsystem:把主机、服务、凭证、会话、漏洞及其来源(provenance)等事实状态外置到结构化存储中,并根据当前树节点选择性注入“最小充分上下文”;再结合 Context Load 作为压缩/裁剪触发信号,直接缓解长链渗透中常见的上下文退化与跨分支切换时的“失忆”。
评估结果
在评估结果上,论文进一步用三类由易到难的基准验证“Type A 工具层 + Type B 规划层(TDA-EGATS)”的叠加收益。
- 其一,在偏 CTF/Web 的 XBOW Beanchmark(104 题) 上,PENTESTGPT v2 在启用思考模式的前沿模型 (GPT-5.2、Claude-Opus-4.5、Gemini-3.0-Pro) 配置下达到 91% 完成率,显著高于第二的 PentestAgent 的 61% ,相对提升约 49% ;
- 其二,在更接近端到端渗透的 PentestGPT Benchmark(13 台 HTB/VulnHub) 上,v2 可攻陷 12/13 ,而第二的 VulnBot 为 9/13 ,相对提升约 33%;
- 其三,在 GOAD(5 主机 AD 环境)中,v2 稳定攻陷 4/5 ,而第二名仅 2/5 ,即 80% vs 40% ,实现了攻陷率翻倍。
除最终成功率外,作者还报告了更贴近“复杂度壁垒”的搜索行为变化:在 PentestGPT Benchmark 上,v2 的 探索分支数 由 3.2→7.8 、回溯率由 8%→34%、成功 pivot 由 0.4→2.6,并出现平均 4.2 条分支的剪枝,体现出 TDA 驱动的探索—利用调度与止损机制确实改变了长链决策行为。
成本方面,v2 在 XBOW 上因减少无效试错使 LLM 调用数中位数 12 次(vs 基线均值 15.6,约 -23%),而在 GOAD 上为换取更充分探索调用数约 +18%,但按“每次成功”口径整体成本效率仍提升(论文估算 XBOW 约 1.8×、GOAD 约 1.7×)。
真实环境实证研究
实验室环境下的 CTF 挑战和容器化靶机虽然提供了严谨的受控评估基准,但它们往往缺乏真实企业网络那庞大的体量、深度的分层防御体系以及充满噪声的业务流量。要客观评判LLM智能体是否具备取代或补充人类专家的能力,必须将其置于高风险的真实生产环境中进行“刺刀见红”的对照实证研究。
CAI: 面向真实用户的黑盒渗透治理框架,协作编排与可控接管
之前的评估适用的场景大多数还是以 CTF 等理想化场景作为 Benchmark ,CAI 在一开始的研究目标就不再停留在能解 CTF 的自动化 agent ,而是将系统明确设计成面向 Bug Bounty 的工作流、可被真实用户使用的半自主安全智能体框架。其关键贡献是把黑盒渗透中最关键的工程问题(自治分级、协作编排、可观测可审计、可控的人类接管)系统化为框架级概念与组件,使 LLM 渗透智能体从能跑的研究系统更接近可被漏洞赏金/真实测试使用的工作流平台。它不仅把工具调用与多智能体协作做成了可复用的框架,还试图回答黑盒渗透里最现实的问题——在信息不完整、噪声很大、攻击链很长的情况下,系统到底能自主到什么程度、哪里必须引入人类监督。
论文先给出一套面向网络安全的自主性等级(autonomy levels)分类,并用四个能力维度来刻画系统是否能在规划(planning)、扫描/枚举(scanning)、利用(exploiting)、缓解(mitigating)上独立闭环;作者将 CAI 定位为开源体系里唯一声称覆盖这四类能力“全自动化”的方案,用于把“黑盒渗透自动化程度”从主观感受变成可比较的系统属性。
在系统架构上,CAI 强调把黑盒渗透的复杂性外置成明确的“协作与执行骨架”,核心由六个支柱组件组成:Agents、Tools、Handoffs、Patterns、Turns、Human-In-The-Loop(HITL),并辅以 Extensions 与 Tracing 做调试与监控。其运行逻辑可以理解为:
- Human Interface Layer:通过 HITL 让操作者下达目标、在关键节点给反馈/批准。
- Agent Coordinator Layer:用 Patterns(可理解为“多智能体协作范式/模板”)组织多个专用 agent,并通过 Handoffs 在 agent 之间交接子任务(例如侦察→Web 测试→逆向→利用)。
- Execution Layer:agent 调用 Tools 执行真实动作(nmap、gobuster、hashcat、Burp/Ghidra 等),并把结果回流给模型继续推理。
- Tracing/Extensions:对 agent 行为、交接与工具调用做记录(tracing),并允许通过扩展增强能力(例如审计、复盘、集成更多安全工具链)。
为了让这套框架更贴近黑盒渗透,CAI 不是只提供“一个通用 agent”,而是把不同渗透角色固化为可复用的 patterns:例如 Red Team Agent(以拿到 root 为目标,偏枚举→利用→提权)、Bug Bounty Hunter(以 Web 资产发现与漏洞验证、负责任披露为目标,集成 shodan/google 等外部情报工具)、Blue Team Agent(偏监控与防御/响应)。这类模式化设计的价值在黑盒场景里很直接:它把“我现在处于什么阶段、该用哪些工具、该产出什么证据、下一步交给谁”变成结构化的协作模板,减少通用 LLM 在长链路里迷路、重复枚举或误用工具的概率。
论文还用一个完整靶机示例展示 CAI 的端到端链路:端口扫描发现 FTP/SSH/HTTP → 利用匿名 FTP + Web 可达目录上传 webshell → 搜索线索并爆破 hash → SSH 登录后借助 sudo 配置缺陷提权到 root。
评估效果
- CTF :作者报告 CAI 在多类别任务上显著降低时间与成本,尤其在取证、逆向相关题型上优势很大;但在 pwn、crypto 这类更依赖深层数学/复杂利用链的题型上存在明显短板。
- Hack The Box:作者用 HTB 做了 7 天集中评测,报告 CAI 在挑战题(单点、边界更清晰的任务)上相对人类能更快拿到 First Blood ;但在需要长链路、多阶段联动的靶标攻陷上,仍普遍慢于人工测试。它往往能在首次运行里全自动解决中等难度并推进到高难目标的 80–90%,借助 HITL 还能攻到更高难度,但在 pwn/利用相关的高级缓解机制(例如 ASLR、stack canary)下会明显受阻
- HTB “AI vs Human” 竞赛:作者报告 CAI 取得 AI 队伍第一,并在总榜进入前列,强调其在限时竞赛中的效率优势(例如更早拿到最后一个 flag、拿到某题 first blood)。
- 漏洞赏金:使用 CAI 辅助挖洞中,一周内报告了若干中高危问题(文中举例包括 open redirect 绕过、APK 相关 WITM/中间人链路、NoSQL 注入等),但是并没有纰漏具体细节,仍然包含有一些虚假漏洞或者价值比较低的漏洞
尽管该框架试图尝试在 LLM 驱动的自动化渗透测试中引入 HITL 辅以加强人机协作,但在真实环境的漏洞挖掘场景下表现仍不够理想,不过也算是在 LLM 自动化测试的流程中一次不错的尝试。
工业界路线:从助手型产品到可验证自治平台
学术界原型常以“可发表、可评测、可对比”为中心,而工业界更关注三件事:可集成、可控、可持续运营(更新工具/模板/知识、记录审计、减少误报与误伤)。这一差异导致工业界往往把系统工程组件做得更丰富:工具编排层、沙箱隔离、日志与可观测、权限与合规闸门、以及可验证的证据链。
nebula-ai:把 LLM 嵌入渗透测试日常操作的“终端与笔记系统”
Nebula-ai 的核心价值并不在于追求“完全自治”,也不像不少学术框架那样把重点放在复杂的任务图或攻击树搜索上;它更像一个面向单兵作业的“渗透测试助手工作台”:用即时建议、过程证据沉淀(日志/笔记/截图标注)以及周期性的状态汇总,降低长流程渗透中常见的上下文搬运、过程遗忘与交付材料整理成本,从而把“执行—记录—复盘/报告”连成一条可交付的链路。
在模型接入上,Nebula 支持本地 Ollama 推理与云端 API 模型两种路径:你可以用本地模型在终端内完成分析与建议生成,也可以按需切换到外部模型服务。这个设计的直接优势是合规与成本的可控性:在敏感资产场景下,你可以选择不把命令输出、目标信息等内容发送到云端模型,而是留在本地推理环境中处理,从而显著降低数据外传风险;同时 Ollama 侧既可用 CPU 推理,也支持 GPU 加速(具体取决于平台与驱动/构建情况)。
交互方式上,Nebula 把 AI 能力放进你本来就在用的 CLI 工作流:允许在“终端执行”和“AI 对话/生成”之间切换(例如用 ! 触发模型),并围绕真实命令输出与历史上下文给出下一步建议,而不是在外部对话里脱离环境“想象”结果。架构上可以概括为三层协同:交互层负责终端工作台与上下文触发入口;智能层是可插拔的推理后端,并可通过 agent 做联网检索以补全漏洞情报与背景;证据层统一管理命令结果、笔记与截图标注,并提供检索与回放,让长链路渗透的状态跟踪更稳定、交付更顺滑。
HexStrike-AI:围绕 MCP 的“工具执行中台”——把数百安全工具变成 AI 可调用能力
HexStrike AI 的核心并不是又一个会自己渗透的 LLM,而是把 150+ 真实安全工具打包成一个 MCP Server,让 Claude/GPT/Copilot 这类支持 MCP 的客户端把它当外部工具箱来调用:LLM 负责读输出、做判断、决定下一步;HexStrike 负责把这一步落实成具体工具命令、执行、收集输出再回传给 LLM。在 README 中,其架构图呈现 “AI Agent(Claude/GPT/Copilot)→ MCP Protocol → HexStrike MCP Server v6.0 → 工具执行/结果回传” 的整体工作流。
从“创新点”讲,HexStrike 的重点是工具编排:一方面它把工具调用做成标准 MCP 接口,解决“不同 LLM/不同 IDE/不同 agent runtime 接工具都要重写一遍”的问题;另一方面它为突出了资源管理(例如缓存、资源优化、错误恢复等),针对的就是自动化跑工具时常见的重复扫描、资源争用、超时/报错后无法继续推进等痛点。
相对很多“LLM + 渗透”原型,它的优势在于接入与扩展,它更像“工具层底座”而不是“规划层论文框架”:LLM 负责理解目标、制定策略、解释结果;HexStrike 负责把策略可靠地落到工具调用上,并把工具输出以更可用的形式回传给 LLM 继续迭代,让模型在对话里按需调用工具完成侦察、枚举、验证、汇总。其还宣称集成了大量安全工具并按领域分组,这使得它更像一个可横向扩展的工具执行底座,而不是只覆盖少量固定工具的 demo。在工程形态上,它不仅提供了面向 Claude Desktop、Cursor、VS Code Copilot 的 MCP 配置示例,还已进入 Kali 的工具仓库并支持通过 apt 安装,至少表明其安装与分发做到了可打包、可复用的程度。
PentAGI:自托管自治代理系统的“平台化实现”——沙箱、知识图谱与可观测
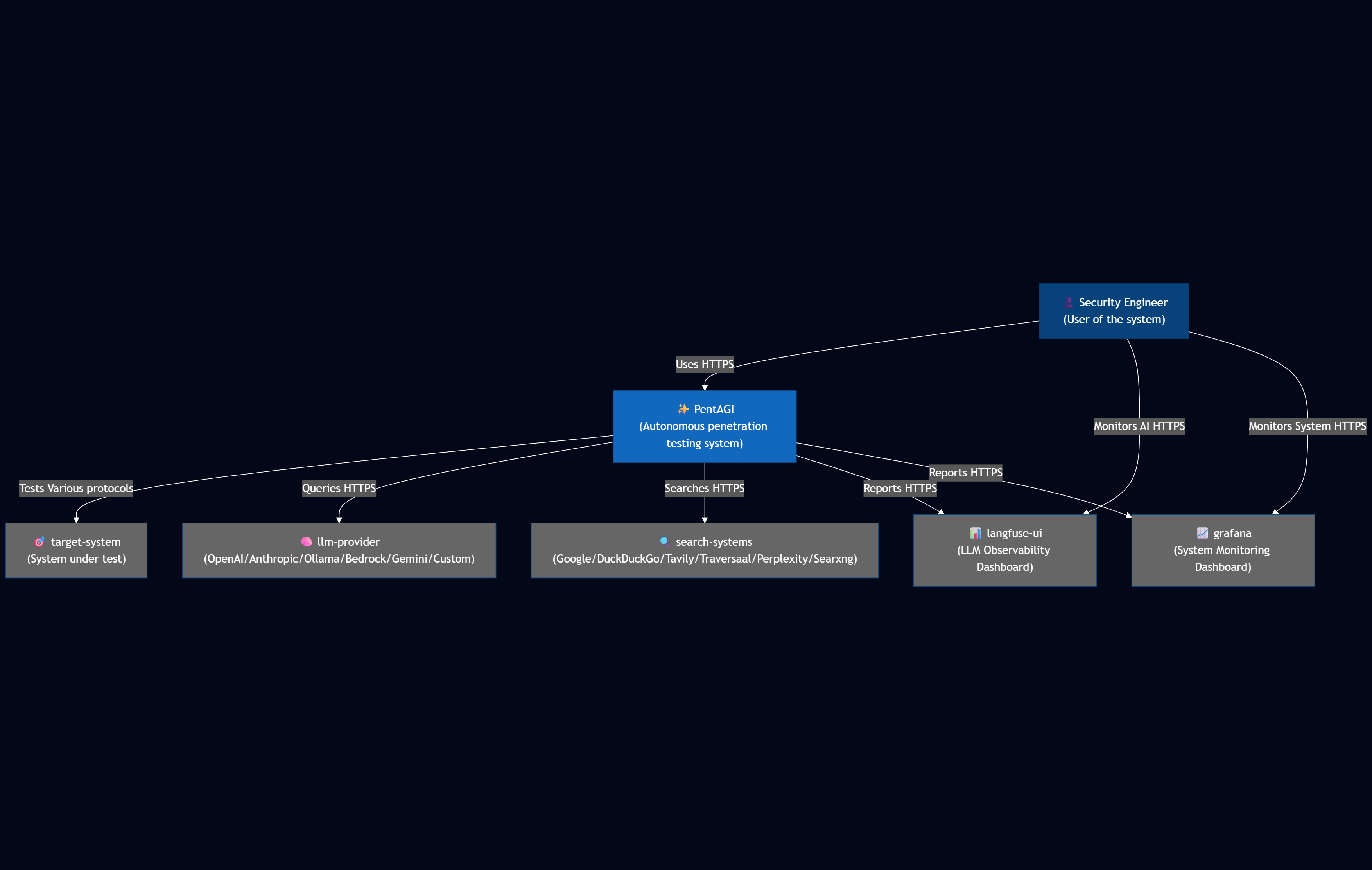
PentAGI 的核心思路是把“LLM 会写命令”升级为“能在受控环境里真实执行并形成可复盘闭环”的渗透智能体系统。它默认将执行侧工程化为 Docker 沙箱,内置一批常见渗透工具,把模型的决策输出直接落到隔离环境中运行,再把命令、输出与上下文统一回收与存储,从而支持端到端流程推进、回放与审计,而不是一次性对话式建议。
在记忆方面,PentAGI 和学术框架的存在一些共同点,都尝试把上下文维持从把所有历史塞进提示词改为外置状态/外置记忆 + 分模块/分角色协作。例如 PentestGPT 通过三模块分工来缓解长流程中的上下文丢失问题,并以外部结构来维护测试进度与已知信息。 PentestAgent 则把流程拆成多个阶段智能体,并强调用检索增强来补足知识与支撑长流程决策,这种“多智能体分工 + RAG/检索”的思路与 PentAGI 的向量记忆层是同一类路线。
PentAGI 则并更偏工程化落地:一方面用 PostgreSQL + pgvector 做可持久化的语义检索;另一方面可选接入 Graphiti/Neo4j 的时序知识图谱,把交互、工具执行等抽取为实体关系并按时间组织,用图查询来支持关系追踪与更结构化的上下文理解。对比很多论文系统常见的摘要或者使用 RAG 获取知识片段,这种向量库 + 时序知识图谱并存的组合更强调可查询的结构记忆,尤其适合处理证据之间的依赖关系和跨阶段串联。
例如,只用摘要或 RAG 时,通常是在大量日志里找一段语义相似的文本:比如“出现过 404 " / “疑似版本号” / “nmap 扫描结果”。这对定位单条线索很有效,但当要回答这种问题时就会吃力,比如这个版本号是从哪个端口/哪个服务 banner 得到的? / 这个目录枚举结果对应哪个虚拟主机?/ 这个 credential 是哪一次尝试成功的,成功后拿到了什么权限? 通过知识图谱把“证据—来源—对象—时间”变成可查询的关系(实体和边),更容易直接定位某个结论依赖哪些证据或某个证据影响了哪些后续动作。
在执行架构层面,所有的渗透测试任务和内置的 20 多种安全工具(如 Nmap、Metasploit)均在沙箱化的 Docker 环境中完全隔离执行。同时,它支持无缝接入各种主流大模型(包括本地部署的 Ollama)和多个外部搜索引擎以获取最新情报。此外,它还深度集成了企业级的可观测性技术栈(如 Grafana、OpenTelemetry 和 Langfuse),不仅能实时监控系统指标和大模型调用,还能在测试完成后自动生成带有详细利用指南的漏洞报告。
整体来看,PentAGI 是为数不多完成度比较高的开源 LLM 自动化渗透系统:提供可交互的前端 UI,后端以 REST/GraphQL API 对外暴露能力,内部由数据库、任务队列与执行器等组件协同完成“任务编排—工具执行—结果回收—状态更新”的闭环,用 Langfuse 记录 LLM 调用与链路,用 Grafana/Prometheus/OTel 等体系采集系统指标、日志与追踪。这种“可观测 + 沙箱化执行 + 可扩展 API”的组合,让它更容易在真实环境里更方便接入既有自动化平台或评测流水线。
XBOW:把“误报”作为核心指标——创造性探索与确定性验证分离
XBOW 在 LLM 自动化渗透测试谱系里更像一个面向生产环境的路线分叉:它不是把重点放在模型是否能提出更多可疑点,而是把交付门槛前移到证据与可复现性本身。其公开平台介绍强调,漏洞利用必须在非破坏性的受控挑战中完成验证,验证逻辑要求确定性、可审计,并且整个平台的自治活动应当可观测、受约束,最终再将结果呈现给用户。 这套叙事的现实意义在于,相比能否提出可疑点,更关键的是能否给出可复现、可验证的证据,否则报告规模上来后会迅速演化为审核负担,从而避免把仅基于猜测或特征匹配的潜在漏洞直接输出给用户。
更关键的是,XBOW 对外展示的并不是单一长生命周期智能体在长链条推理中的胜利,而是以架构手段绕开长会话的脆弱性:用大量短生命周期、目标聚焦的 agent 做并行探索,将创造性探索与确定性验证解耦,再用验证器把假设落到可重复执行的证据链上。 官方复盘给出过相对具体的验证思路,例如在 XSS 等问题上通过无头浏览器确认 payload 的脚本执行,而不是停留在响应特征或文本匹配层面。 从批判角度看,这也意味着 XBOW 的能力边界并不只由模型决定,而更像由验证器覆盖面与验证成本决定:验证器做得越“硬”,误报越低,但可扩展性与维护成本越高;验证器做得越“软”,就会重新滑回概率性猜测与噪声膨胀。
关于其在 HackerOne 场景的成绩,XBOW 官方确实宣称曾在 HackerOne leaderboards 达到领先位置,且在特定筛选条件下可以看到 XBOW 排名靠前。 但这类榜单更像结果信号而非可迁移的能力证明:其一,HackerOne 明确提出对 hackbots 的规则约束,强调目前仍是人类在环的提交模式,需要人类专家在提交前进行调查、验证与确认。 其二,榜单缺乏公开的l漏洞严重性分布、通过率、重复性与对照评测,无法据此推出超越人类或大量 0day 的结论;个人认为更稳妥的评价是,XBOW 把可审计的确定性验证放到产品架构中心,并围绕平台规则构建人机协作与风险约束,这是其比较清晰、也最容易被外部证实的差异点。
内生性技术缺陷剖析:幻觉机制、假阳性困境与信噪比博弈
LLM 在自动化渗透测试中确实能显著降低侦察、枚举、脚本编写与报告整理的人工负担,但一旦把目标提升为端到端的黑盒攻陷与高置信度的可利用性验证,系统就会立刻暴露出一些由模型工作方式直接导致的结构性缺陷。和通用对话任务不同,渗透测试的每一步都要对真实系统状态负责:命令是否可执行、输出是否可信、假设是否被证据支持、下一步是否在授权边界内。只要其中任何一环被幻觉或误判污染,就会把整条攻击链推向错误分支,最终表现为低信噪比、假进展、假阳性与高成本空转。
幻觉在自动化渗透中的三类典型形态
大语言模型固有的“幻觉”(Hallucinations)现象在安全测试的严苛执行环境中不再仅仅是“输出错误文本”这么简单,其引发的后果是灾难性的。深度的实证分析表明,自动化安全工具中的幻觉可以精细化解构为三个截然不同且极具破坏性的维度 :
- 命令幻觉(Command Hallucination):这类幻觉发生在战术执行的最底层,可进一步细分为“工具选择幻觉”和“工具调用幻觉”。模型可能会基于训练数据中残留的模糊记忆过度自信地选择目标靶机环境中根本不存在的探测工具;或者在调用真实存在的工具(如Nmap、Metasploit)时,凭空捏造不兼容的参数、遗漏关键的鉴权标志,甚至随意填充错误的负载数据,导致指令直接报错崩溃 。
- 逻辑幻觉(Logic Hallucination):发生在攻击路径选择层。在规划阶段,模型错误地匹配了攻击逻辑。例如,模型可能在探测到一个纯粹的静态文件服务器时,基于“Web服务”的宽泛标签,荒谬地尝试使用复杂的SQL注入技术或反序列化攻击向量。它看起来像在规划,实际是在用模板化经验套目标,缺乏对前置条件与失败证据的硬约束。
- 状态幻觉(State Hallucination):发生在长链路交互与多轮试错之后。它可能会在上一轮的漏洞利用脚本明确返回“连接拒绝”的情况下,错误地“臆想”系统已经成功获取了 Root 权限的 Shell ,并开始煞有介事地发出诸如收集密码哈希等无意义的后渗透指令,导致整个攻击图谱发生严重的逻辑断裂 。
进一步的现实风险是,自动化渗透系统往往会让 LLM 生成或改写验证脚本(例如 Python/Node.js 的 PoC、探测器、辅助解析器)。一旦模型在依赖名、模块名或下载地址上产生幻觉,流水线如果直接安装并执行,就可能引入供应链投毒风险(Slopsquatting,即针对AI幻觉的供应链投毒)。对渗透智能体而言,最关键的不是写脚本能力,而是对依赖存在性、来源可信度、执行环境隔离的强制校验,否则验证漏洞的工具会反过来变成企业内部的引入点。
误验证困境:假阳性、假进展与成本的负反馈
自动化渗透里的难点往往不是发现线索,而是把线索变成可复现、可审计的利用证据。只要系统把“可能”当成“已经确认”,就会产生三种典型噪声:
- 假阳性 (False Positive, FP):把正常响应误判为漏洞存在,例如把重定向当开放重定向、把错误栈当可利用信息泄露、把可控参数当注入点。
- 假进展:工具输出被错误解析或被过度解释,导致状态树提前推进,后续每一步都在错误基础上继续消耗预算。
- 成本空转:为了自证合理,模型可能不断追加扫描、换字典、换 payload、换工具,工具调用次数、Token 与耗时上升,但实际验证成功率不升反降。
相关研究甚至指出,在某些自动化框架(如MAPTA)的实际部署中,模型为了验证一个漏洞而盲目增加的工具调用次数、Token消耗量和时间成本,与其最终的验证成功率之间甚至呈现出负相关性(例如,工具调用次数与成功率的相关系数 $r = -0.661$) 。
因此,面向 LLM 自动化渗透,过滤机制的重点应从“让模型更会猜”转为“让系统更会证伪”。一种常见的可落地策略是把发现与验证解耦:
- 发现阶段允许更高召回,快速扩展假设空间;
- 验证阶段用更严格的裁判模块(可以是规则、也可以是专门的判定模型)对证据链做一致性检查,只输出可复现的最小证据集,例如必要的命令、关键输出片段、环境前置条件与失败分支说明。
例如,Datadog 公司推出的 Bits AI 技术,其核心逻辑并非替代扫描器,而是建立在扫描器的基础之上。当传统 SAST 扫描器或自动化探测工具抛出一个潜在漏洞时,Bits AI 会将被标记的漏洞及其周围深度的源代码上下文联合输入给 LLM ,由 LLM 充当逻辑分析师,综合评估该漏洞在企业特定的业务上下文中是否具备真实的可利用性,并生成详细的推理说明 。这种将大型语言模型的强项用于 FP 过滤,而非盲目生成攻击载荷的策略,通过整合多维度检测工具的优势并引入交叉验证机制,被证明是当前提升系统整体判定精度与有效控制 FP 灾难的实践路径之一。
执行边界管控与有界自主:面向企业落地的渗透智能体治理
当 LLM 从助手走向可自主执行的渗透智能体,最核心的问题就从能力转为治理:如何在释放自动化效率的同时,保证所有动作都在授权范围内、可审计、可回滚,并且不会因误判对生产系统造成不可控影响。这里需要一套能映射到工程机制的自主性分级与护栏体系。
AI智能体自主性成熟度的五级框架
基于人类操作者在AI智能体运行周期中所掌握的控制权比重,研究者们提出了的五级自主性成熟度理论框架(Levels of Autonomy for AI Agents) 。这一框架不仅界定了当前技术的发展方位,也为未来的合规性部署提供了参考依据:
- L1(Operator - 操作员模式):自主性最低的层级。在此模式下,人类专家保留了绝对的规划与决策权。AI仅仅作为一个高级的终端界面或代码补全工具存在,严格依据人类下达的单步指令被动执行特定动作(如格式化某个Nmap扫描参数),自身不具备任何链式推理能力 。
- L2(Collaborator - 协作者模式):控制权在人类与机器之间实现双向流动。智能体能够理解高层意图,主动生成多步攻击计划并提供战术建议,但每执行完一个关键阶段,控制权便无缝交还给人类。人类可以随时纠正智能体的偏误,典型的如具备深层交互能力的副驾驶(Copilot)系统 。
- L3(Consultant - 顾问模式):智能体开始主导整个渗透测试的生命周期。它独立执行从信息侦察到漏洞扫描的全量任务,仅在遭遇超出其知识库的罕见防御机制,或者在选择多种等效但风险不同的利用载荷时,才会主动挂起进程并向人类专家“咨询”专业意见和偏好设定 。
- L4(Approver - 审批者模式):AI智能体实现了高度的闭环独立运行。它可以在无人值守的情况下连续运行数小时甚至数天,自主挖掘深层网络拓扑。只有当其决策树判定下一步操作极有可能触发高风险后果(例如尝试利用一个可能导致目标服务崩溃的堆栈溢出漏洞,或者尝试跨越核心网段的横向移动)时,系统才会触发强制拦截机制,要求具有对应权限的人类主管进行明确的“审批”授权 。
- L5(Observer - 观察者模式):自主性的终极形态。多智能体系统在极具弹性的沙箱或已高度授权的“红队”演习中完全独立运作。人类彻底退出实时的战术和战略决策回路,其角色退化为纯粹的“观察者”,仅负责在测试结束后接收结构化的漏洞利用报告、攻击复盘树以及合规性评估审计文件 。
从行业现状来看,诸如早期的 PentestGPT 大多处于L2阶段,而融合了 RAG 机制的 xOffense 以及实现了阶梯学习的 CurriculumPT 等先进框架,正处于从 L3 向 L4 迈进的关键转折点 。
受限执行与有界自主的工程化落地
在企业级安全架构的实际部署中,“执行自主性”不能仅仅停留在理论探讨阶段,而必须被转化为可用代码强制执行的护栏策略 。为了防止高等级自主智能体在复杂网络中“暴走”,系统工程界发展出了“受限执行”(Guarded Execution)与“有界自主”(Bounded Autonomy)这两大核心防御性架构 。
受限执行机制将 AI 生成的攻击载荷和系统配置更改指令拦截在执行的“最后一公里”。当智能体生成了一个试图利用目标漏洞的命令时,该命令不会被直接推送到底层 Shell ,而是必须首先通过企业标准的工作流引擎。系统会自动根据预设的安全策略对其进行静态分析,检查诸如:目标IP地址是否严格位于本次安全审计的授权白名单范围内?所选用的漏洞利用脚本历史数据是否表明存在较高的导致服务拒绝(DoS)的概率?只有通过了所有自动化校验逻辑,并在必要时获得了相关负责人的电子审批后,该攻击动作才会被最终放行 。
有界自主则是一种更为动态的约束哲学。它允许智能体在预先定义好的“安全操作空间”内(例如:只能针对特定的隔离子网进行测试、只能调用已知非破坏性的 CVE 库)发挥极高的自我推理和连续试错能力。然而,一旦智能体的行为轨迹,如探测到核心数据库所在的敏感网段或尝试进行未授权的凭证转储——触及或试图跨越这些预设的红线边界时,安全编排层将立即介入,触发针对该智能体的权限降级策略或直接阻断其当前工作流并强制上报 。此外,为防止智能体本身被受控靶机反向渗透利用,业界也开始在基础设施层面采用隔离执行(Isolated Execution)技术,例如为渗透测试智能体分配专用的硬件资源、实施严格的网络边界隔离,以及广泛采用带有 TLS 双向认证的 Docker-in-Docker 安全容器机制,确保自动化测试流程在极度受限且绝对安全的物理与逻辑容器中运行
展望与总结
对大型语言模型在自动化渗透测试领域发展的全面研究表明,网络安全评估技术正经历一次不可逆转的深度变革。从依赖人为直觉的单线程手动测试,到基于硬编码规则的传统漏洞扫描,再到如今由概率性推理驱动的多智能体协同系统,自动化工具已经跨越了单纯执行机械命令的门槛,初步具备了在庞大且嘈杂的异构IT基础设施中进行全局信息规划与动态战术调整的能力。
| 框架 | 时间与出处 | Agent 模式 | 自动化程度 | 核心状态/规划机制 | 知识更新与记忆 | 工具执行层特点 | 验证与证据链 | 学习与经验重用 | 评测口径与代表性结果 |
|---|---|---|---|---|---|---|---|---|---|
| PentestGPT | USENIX Security 2024(最初 2023 预印本) | 单系统内三模块协作(推理/生成/解析) | 交互式为主(更偏 HITL) | 渗透测试任务树 PTT 作为外置进度与上下文骨架,围绕 PTT 更新与决策 | 以外置结构化状态缓解上下文丢失;不以长期经验库为中心 | 生成模块产生命令、解析模块读输出,强调模块化与可控协作流程 | 未把独立 exploit verification 作为核心机制主打 | N/A | 以能力分析 + 系统设计 + 案例验证为主 |
| PentestAgent | arXiv 2024-11-07 | 多智能体协作,覆盖情报收集/漏洞分析/利用等阶段 | 面向自动化、减少人工介入 | 以阶段化分工与协作编排为主(按渗透阶段拆任务) | 明确引入 RAG 补齐版本细节与漏洞知识 | 强调工具与代理结合,自动化执行多类子任务 | 更偏流程自动化 + 知识增强,非验证器导向 | N/A | 报告在其基准上完成度与效率优于对比系统 |
| VulnBot | arXiv 2025-01-23 | 多智能体协作 | 强调自动化、降低人工干预 | 三阶段(侦察/扫描/利用),用渗透任务图 PTG 约束执行顺序与路径 | 重点在图结构化流程与跨 agent 通信,不以长期经验库为中心 | 通过角色专长与通信减少无结构输出,提高可控性 | 未突出专门的 exploit verification 作为主线 | N/A | 声称在自动化渗透任务上优于若干 LLM 基线 |
| TermiAgent | arXiv 2025-09 | 多智能体框架 | 强调端到端自动化与低成本落地 | Located Memory Activation:按阶段/路径定位并激活相关记忆,缓解长链遗忘 | 结合 exploit arsenal,把公开 exploit 封装为结构化可调用资产,提升可用性与可复用性 | 更强调把 exploit 变成可执行资产,而不是每次临场生成与拼提示 | 通过资产化与结构化过程降低不可复现与误用风险(验证更多依赖其资产流程) | 有机制化经验管理(记忆激活 + 资产库),但不是在线训练式学习 | 声称在评测中优于当时 SOTA,并降低时间与成本 |
| CurriculumPT | Applied Sciences 2025 | 多智能体系统 | 以自动化为目标,强调持续学习视角 | 课程调度:按由易到难组织任务,驱动技能渐进习得 | 动态经验库用于知识重用与迁移(经验而非单次上下文) | 工具底座不是核心贡献,重点在调度与经验重用框架 | 验证机制不是主轴 | 明确主打跨任务经验积累与迁移 | 报告课程化带来更稳定成功率与一定泛化收益 |
| xOffense | arXiv 2025-09-16 | 多智能体(侦察/扫描/利用)+ 编排层 | 明确定位全自动、可扩展工作流 | 以多阶段编排为主,强调把流程从人工转为机器可执行 | 强调领域适配与成本控制,可接入知识增强;报告使用开源模型微调配置 | 目标是更稳定的工具指令与一致的多步决策(微调 + 编排结合) | 未突出独立验证器为核心模块 | 偏向于离线微调带来的能力迁移 | 报告在 AutoPenBench、AI-Pentest-Benchmark 上超过若干对比系统 |
| PentestGPT v2 | arXiv 2026-02 | 分层架构(工具与技能层 + 难度感知规划层 + 记忆子系统) | 面向更强自治,强调端到端稳健性 | Task Difficulty Assessment + Evidence-Guided Attack Tree Search:用实时难度信号与证据回传做分支选择与剪枝 | 结构化状态 + 检索增强;工具与技能层用类型化接口与技能组合减少工具型失败 | 工具与技能层提供类型化接口与技能组合,系统性减少命令/语义用错 | 把证据置信度作为规划信号之一,用证据驱动剪枝减少走偏 | 不强调在线训练,但把历史成功模式与难度估计纳入决策 | 三基准:XBOW 91%、PentestGPT Benchmark 12/13、GOAD 4/5,并相对最佳基线提升明显 |
以上是对当前学术界自动化渗透测试框架的梳理。从表格可以看出,这条技术演进主线更像是三次架构重心的迁移:早期以 PentestGPT 为代表,通过状态外置的任务树 PTT 把长链条渗透过程结构化,缓解模型在多阶段任务中遗忘与上下文碎片化的问题;随后以 PentestAgent 等工作为代表,把检索增强引入渗透流程,用可更新的外部知识弥补预训练知识对漏洞细节与版本信息覆盖不足的短板;再往后,研究焦点进一步从单纯补齐信息转向可复用能力的组织与调度,例如 CurriculumPT 用课程调度与经验库把任务按难度递进安排,试图让系统在反复实践中积累可迁移的攻击经验,而 TermiAgent 则通过按阶段激活记忆与将 exploit 资产化,提高长链任务中的稳定性与可复现性。与此同时,xOffense 展示了另一条路径:通过工作流编排结合开源模型的领域适配,使多步决策与工具调用更稳定,减少在复杂状态空间里因指令漂移导致的失败。总体而言,这些框架在基准环境中的成功率与端到端能力已显著提升,但其证据链严谨性、误报控制与对真实企业环境中强噪声与强对抗条件的泛化能力,仍取决于是否具备更明确的验证机制与更可审计的执行闭环。
不过将当前的 LLM 架构直接等同于“无需人类干预的完美黑客”也是一种过度乐观的表现。存在于底层模型中的内生性缺陷构成了阻碍其向完全自主的 L5 模式迈进的核心壁垒。Pentest GPT V2 中的复杂性壁垒揭示了模型在面对多分支策略时,由于缺乏内在的任务难度评估和理性算力分配机制而极易陷入无效循环的“隧道视野”;三维度的幻觉机制不仅直接导致了攻击链条的断裂,更坏的是,它可能进一步引入了供应链投毒风险;而长期居高未下的 False Positive ,如果不能通过诸如Bits AI 之类的交叉验证机制加以遏制,必将进一步恶化现代 SOC 本已不堪重负的告警疲劳。
展望 2026 年及以后的安全技术格局,单纯依靠增加模型参数规模或堆叠算力已不足以从根本上解决网络对抗中的高阶逻辑博弈问题。下一代自动化渗透测试平台的演进轨迹,必然是向着“具备认知约束的工程化智能”方向发展。这要求学术界与工业界在算法内核层面,广泛部署如 PentestGPT v2 中所见的基于证据引导的搜索树和动态难度评估网络等算法,以赋予智能体类似于人类的直觉性风险预判与资源规划能力;同时,在系统架构层面,必须坚定不移地推行受限执行与有界自主机制,将 AI 的创造性破坏力牢牢锁定在合规与业务连续性的物理围栏之内。只有当深度推理算法的进化与严苛的边界管控工程实现完美契合时,LLM驱动的自动化渗透测试才能真正从一把不可预知的双刃剑,蜕变为捍卫数字时代基础设施最坚不可摧的自动化免疫防线。
致谢
感谢 ChatGPT / Gemini 在本文撰写过程中给予的帮助,包括编辑、润色等。
References
- PentestGPT: Evaluating and Harnessing Large Language Models for Automated Penetration Testing, https://www.usenix.org/system/files/usenixsecurity24-deng.pdf, USENIX, Aug 2024
- PentestAgent: Incorporating LLM Agents to Automated Penetration Testing, https://arxiv.org/abs/2411.05185, ArXiv, 7 Nov 2024
- VulnBot: Autonomous Penetration Testing for A Multi-Agent Collaborative Framework, https://arxiv.org/abs/2501.13411, ArXiv, 23 Jan 2025
- AutoPentest: Enhancing Vulnerability Management With Autonomous LLM Agents, https://arxiv.org/abs/2505.10321, ArXiv, 15 May 2025
- CAI: An Open, Bug Bounty-Ready Cybersecurity AI, https://arxiv.org/abs/2504.06017, ArXiv, 8 Apr 2025
- TermiAgent: Real-World Benchmarks and Memory-Activated Agents for Automated Penetration Testing, https://arxiv.org/abs/2509.09207, ArXiv, 11 Sep 2025
- xOffense: An AI-driven autonomous penetration testing framework with offensive knowledge-enhanced LLMs and multi agent systems, https://arxiv.org/abs/2509.13021, ArXiv, 16 Sep 2025
- CurriculumPT: LLM-Based Multi-Agent Autonomous Penetration Testing with Curriculum-Guided Task Scheduling, https://www.mdpi.com/2076-3417/15/16/9096, MDPI, 13 August 2025
- The State of Cybersecurity in 2025: Data-Driven Insights from Over 50,000 NodeZero® Pentests, https://horizon3.ai/category/downloads/research/, Horizon3.ai, Mar 2025
- Levels of Autonomy for AI Agents, https://arxiv.org/abs/2506.12469, arXiv / Knight 1st Amendment Institute, Jun 2025
- 2025 State of Pentesting Report, https://pentera.io/blog/2025-state-of-pentesting-insights/, Pentera, 2025
- Slopsquatting: When AI agents hallucinate malicious packages, https://www.trendmicro.com/vinfo/pl/security/news/cybercrime-and-digital-threats/slopsquatting-when-ai-agents-hallucinate-malicious-packages, Trend Micro, 2025
- Using LLMs to filter out false positives, https://www.datadoghq.com/blog/using-llms-to-filter-out-false-positives/, Datadog, 2025